Debezium部署以及同步之DB2数据到Kafka的同步
因为Debezium依赖于kafka之上,所以我们先部署kafka和zookeeper(忽略)。

1 环境介绍
Debezium1.9版本 Db2 11.5版本 附官网:https://debezium.io/documentation/reference/1.9/connectors/db2.html#_putting_tables_into_capture_mode
2 Db2开启CDC
第一步 准备要让Debezium 连接器监控的db2数据库(让里面的表开启CDC)
为了将表置于捕获模式,Debezium 提供了一组函数辅助实现捕捉模式
2.1 下载DB2的CDC函数
函数地址
把github上的debezium-examples/tutorial/debezium-db2-init/的db2server文件夹上传到服务器的db2inst1目录下:/home/db2inst1

2.2 编译Debezium提供的UDF代码
#用户身份登录到 Db2 db2instl
su - db2inst1
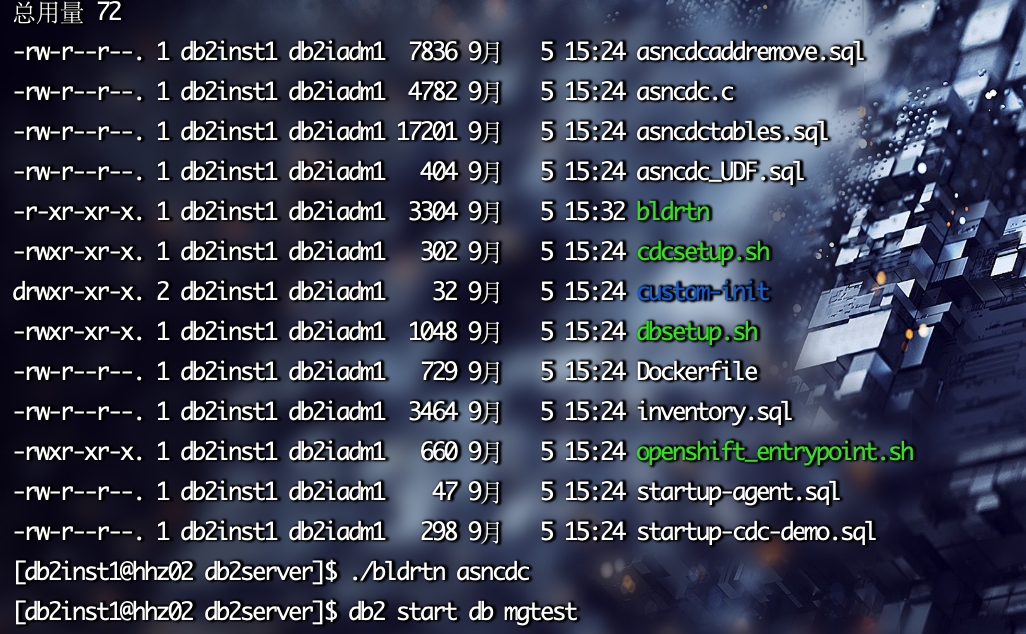
cd $HOME/db2server
#使用Db2 提供的命令bldrtn 编译Debezium提供的UDF代码
./bldrtn asncdc
../sqllib/samples/c/bldrtn asncdc
确保自己linux上有gcc,不然不能使用bldrtn
2.3 首先需要连接到数据库
首先需要连接到数据库:
第一步:db2 connect to mgtest user db2inst1 using 123456
第二步:db2 list active databases(查看活跃的数据库列表)

2.4 确保 JDBC 可以读取 Db2 元数据目录
cd $HOME/sqllib/bnd
db2 bind db2schema.bnd blocking all grant public sqlerror continue

2.5 连接到数据库以安装 Debezium 管理 UDF。
db2 connect to mgtest
2.6 复制 Debezium 管理 UDF 并为其设置权限:
cp -r $HOME/debezium-examples/tutorial/debezium-db2-init/db2server/* $HOME/sqllib/function
chmod 777 $HOME/sqllib/function
2.7 启用启动和停止 ASN 捕获代理的 Debezium UDF:
db2 -tvmf $HOME/sqllib/function/asncdc_UDF.sql
2.8 创建 ASN 控制表:
db2 -tvmf $HOME/sqllib/function/asncdctables.sql
2.9 启用将表添加到捕获模式并从捕获模式中删除表的 Debezium UDF:
db2 -tvmf $HOME/sqllib/function/asncdcaddremove.sql
启动代理之前需要配置Logarchmeth1 不然会开启报错。
2.10配置方法进入db2
update db cfg for mgtest using LOGARCHMETH1 LOGRETAIN
Logarchmeth1和Logarchmeth2配置可能有如下几种组合
1,Logarchmeth1设置为LOGRETAIN,Logarchmeth2只能设置为OFF
归档日志位置就是DB2数据库日志的位置,需要人工干预归档日志的转移和空间维护工作
2,Logarchmeth1设置为USEREXIT,Logarchmeth2只能设置为OFF
归档日志的管理交由USEREXIT来处理,通过设置编译USEREXIT可以实现相对复杂一些的归档管理方式
3,Logarchmeth1设置为<Directory>,Logarchmeth2设置为OFF
归档日志的工作将会自动进行,需要归档日志将会被自动归档到<Directory>指定的位置,由于归档是自动进行,DB2的日志目录中只有正常logprimary+logsecond个数据库日志。
4,Logarchmeth1设置为<Directory1>,Logarchmeth2设置为<Directory2>
2.11 重启db2数据库生效
若修改数据库LOGRETAIN参数,从循环日志模式改为归档日志模式,则会导致数据库backup pending状态。
db2 backup db mgtest to /opt/bak
将表格置于捕获模式。为要捕获的每个表调用以下语句。替换MYSCHEMA 为包含要进入捕获模式的表的模式的名称。同样,替换MYTABLE为要进入捕获模式的表的名称:
CALL ASNCDC.ADDTABLE('DB2INST1', 'TESTTB');
启动 ASN 代理:
进入db2
VALUES ASNCDC.ASNCDCSERVICES('start','asncdc');
重新初始化 ASN 服务:
VALUES ASNCDC.ASNCDCSERVICES('reinit','asncdc');
安装db2连接器:debezium-connector-db2-1.9.0.Final-plugin.tar.gz
[root@hhz02 app]# mkdir -p /opt/debezium/connector
[root@hhz02 app]# tar -xvf debezium-connector-db2-1.9.0.Final-plugin.tar.gz -C /opt/debezium/connector/
debezium-connector-db2/debezium-core-1.9.0.Final.jar
debezium-connector-db2/debezium-api-1.9.0.Final.jar
debezium-connector-db2/guava-30.1.1-jre.jar
debezium-connector-db2/failureaccess-1.0.1.jar
debezium-connector-db2/debezium-connector-db2-1.9.0.Final.jar
3 配置kafka connect
让kafka知道这个插件。(集群版配置connect-distributed.properties)
[root@hhz02 config]# vi connect-standalone.properties
配置注意项:(单机模式启动连接器 connect-standlone.properties)
bootstrap.servers=172.16.105.53:9092
offset.storage.topic=connect-db2-status
offset.storage.replication.factor=1
key.converter=org.apache.kafka.connect.json.JsonConverter
value.converter=org.apache.kafka.connect.json.JsonConverter
key.converter.schemas.enable=false
value.converter.schemas.enable=false
status.storage.topic=connect-db2-statu
status.storage.replication.factor=1
config.storage.topic=connect-db2-config
config.storage.replication.factor=1
group.id=connect-db2
offset.flush.interval.ms=10000
plugin.path=/opt/debezium/connector
rest.port=8083
注意:集群模式kafka 需要注意配置分发。
重启kafka集群使配置生效。
3.1 启动Kafka connector
/opt/app/kafka_2.12-2.8.0/bin/connect-distributed.sh -daemon /opt/app/kafka_2.12-2.8.0/config/connect-standalone.properties
注意结尾这个文件 集群模式为:connect-distributed.properties,单机模式为:connect-standalone.properties
(如果启动有问题 观察/opt/app/kafka/logs/connectDistributed.out)
3.2 检测Kafka connector是否正常工作
1. 检测kafka连接器的服务状态
[root@hdp01 kafka]# curl -H "Accept:application/json" hhz02:8083/
{"version":"2.0.0.3.1.5.0-152","commit":"a10a6e16779f1930","kafka_cluster_id":"Ahq9DtMLT4uZVtwteL3NAA"}
2. 检查向 Kafka Connect 注册的连接器列表
[root@hdp01 kafka]# curl -H "Accept:application/json" hhz02:8083/connectors/
[]
返回空列表, 表示目前还没有注册的连接器
附:删除命令
curl -X DELETE hhz02:8083/connectors/db2-connector1
3.3 部署Debezium DB2 Connector
Db2 连接器配置示例
以下是连接器实例的配置示例,该实例从位于 172.16.105.53的端口 60000 上的 Db2 服务器捕获数据
您可以选择为数据库中的模式和表的子集生成事件。或者,您可以忽略、屏蔽或截断包含敏感数据、大于指定大小或您不需要的列。
{
"name": "db2-connector1",
"config": {
"connector.class": "io.debezium.connector.db2.Db2Connector",
"database.hostname": "172.16.105.53",
"database.port": "60000",
"database.user": "db2inst1",
"database.password": "123456",
"database.dbname": "mgtest",
"database.server.name": "testtb",
"table.include.list": "DB2INST1.TESTTB",
"database.history.kafka.bootstrap.servers": "hhz02:9092",
"database.history.kafka.topic": "dbhistory.testtb"
}
}
1 向 Kafka Connect 服务注册时的连接器名称。
2 此 Db2 连接器类的名称。
3 Db2 实例的地址。
4 Db2 实例的端口号。
5 Db2 用户的名称。
6 Db2 用户的密码。
7 要从中捕获更改的数据库的名称。
8 Db2 实例/集群的逻辑名称,形成一个命名空间,用于连接器写入的所有 Kafka 主题的名称、Kafka Connect 模式名称以及Avro 连接器运行时对应 Avro 模式的命名空间用过的。
9 Debezium 应捕获其更改的所有表的列表。
10 此连接器用于将 DDL 语句写入和恢复到数据库历史主题的 Kafka 代理列表。
11 连接器写入和恢复 DDL 语句的数据库历史主题的名称。本主题仅供内部使用,消费者不得使用。
3.4 注册连接器
Kafka Connect 服务的 API 提交POST针对/connectors资源的请求,其中包含描述新连接器(称为inventory-connector)的 JSON 文档。
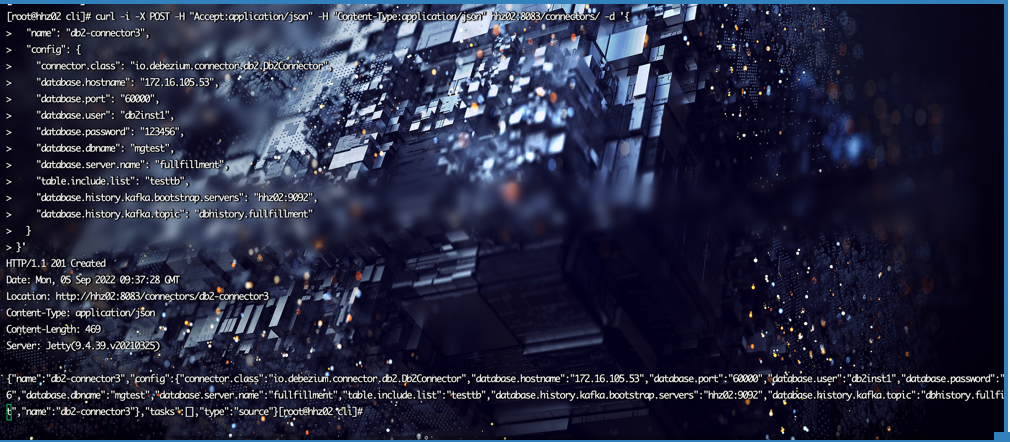
curl -i -X POST -H "Accept:application/json" -H "Content-Type:application/json" hhz02:8083/connectors/ -d '{
"name": "db2-connector1",
"config": {
"connector.class": "io.debezium.connector.db2.Db2Connector",
"database.hostname": "172.16.105.53",
"database.port": "60000",
"database.user": "db2inst1",
"database.password": "123456",
"database.dbname": "mgtest",
"database.server.name": "testtb",
"table.include.list": "DB2INST1.TESTTB",
"database.history.kafka.bootstrap.servers": "hhz02:9092",
"database.history.kafka.topic": "dbhistory.testtb"
}
}'
(如果注册有问题 观察/opt/app/kafka/logs/connectDistributed.out)
多看下日志 日志中都可以 写到 如果注册成功,也没有kafka数据 麻烦看下日志WARN中过滤问题。[sourceTableId=DB2INST1.TESTTB, changeTableId=ASNCDC.CDC_DB2INST1_TESTTB
]
3.5 查看kafka中的数据
查看所有topic:/opt/app/kafka_2.12-2.8.0/bin/kafka-topics.sh -list -zookeeper localhost:2181
消费topic:/opt/app/kafka_2.12-2.8.0/bin/kafka-console-consumer.sh --bootstrap-server hhz02:9092 --from-beginning --topic testtb.DB2INST1.TESTTB

成功的话connectDistributed.out同步日志:
INFO 1 records sent during previous 00:15:06.067, last recorded offset: {transaction_id=null, event_serial_no=1, commit_lsn=00000000:000036e4:00000000000683ef, change_lsn=00000000:00000000:0000000006a46f56}