kafka模拟消费报错 ISR缺失 指定offset提取数据失败场景
测试集群信息
kafka版本:3.0.0
172.16.120.236 kafka-id: 0
172.16.121.150 kafka-id: 1
172.16.121.225 kafka-id: 2
背景描述
客户消费kafka中某一个topic的分区数据到达指定offset 就消费报错了 而且ISR副本也会同步失败
本文要做的是模拟拿出出问题的那个offset
创建一个测试topic
kafka-topics.sh --create --bootstrap-server emr1:9092,emr2:9092,emr3:9092 --replication-factor 3 --partitions 3 --topic kafka-check

编写一个脚本不断往里面写入数据
#!/bin/bash
while true
do
# 生成随机数据
data=$(head /dev/urandom | tr -dc 'a-zA-Z0-9' | head -c 1000)
# 向 Kafka topic 写入数据
echo "$data" | /opt/dtstack/Kafka/kafka/bin/kafka-console-producer.sh --broker-list emr1:9092,emr2:9092,emr3:9092 --topic kafka-check
done
消费看下
kafka-console-consumer.sh --bootstrap-server emr1:9092,emr2:9092,emr3:9092 --topic kafka-check
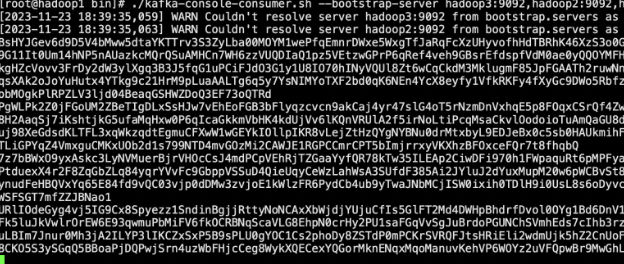
查看下当前分区情况
kafka-topics.sh --bootstrap-server emr1:9092,emr2:9092,emr3:9092 --topic kafka-check --describe

查看test消费组消费的情况
kafka-consumer-groups.sh --bootstrap-server emr1:9092,emr2:9092,emr3:9092 --describe --group test

例如分区0 当前offset:2827 最后offset:4346 滞后量:1519
比如现在我想拿到分区0的2828的offset数据
根据上图查看的分区情况来看的话 0分区的Leader在2上 我们就去kafka的id 2机器上
指定offset消费数据 犹豫我们要拿出的那个offset数据是指定offset消费不出来的
为了测试更加准确定 我们提前看一下2828的结果吧
kafka-console-consumer.sh --bootstrap-server emr1:9092,emr2:9092,emr3:9092 --topic kafka-check --partition 0 --offset 2828 | head -1
结尾:jMxMWtwOCzdyr7v4hLl

ok那我们继续测试
指定offset消费 1条从2827开始
kafka-console-consumer.sh --bootstrap-server emr1:9092,emr2:9092,emr3:9092 --topic kafka-check --partition 0 --offset 2827 | head -1
结尾:qI12ZjInjzOetudzQH

然后我们去数据目录(Leader的节点)
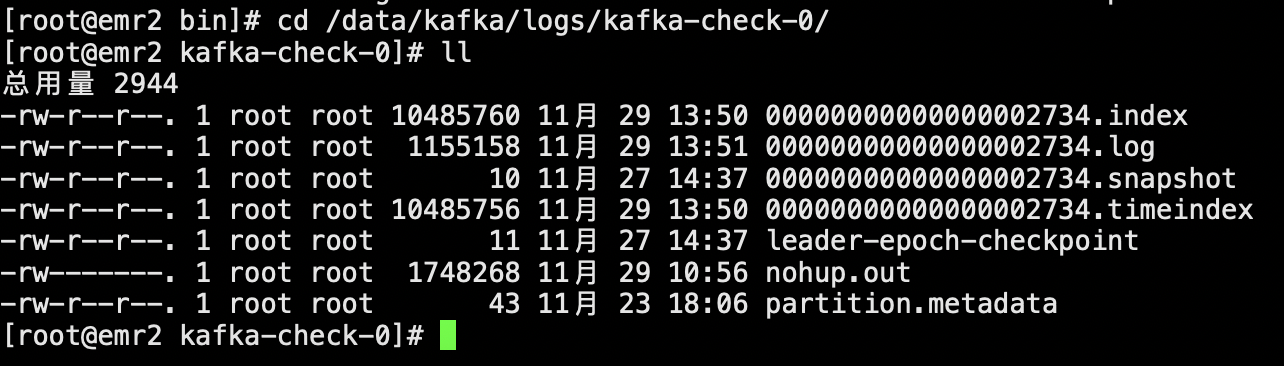
cd /data/kafka/logs/kafka-check-0/
ll
搜索这个数据
grep -Rn "qI12ZjInjzOetudzQH"

匹配到文件 进入这个二进制文件
搜索qI12ZjInjzOetudzQH
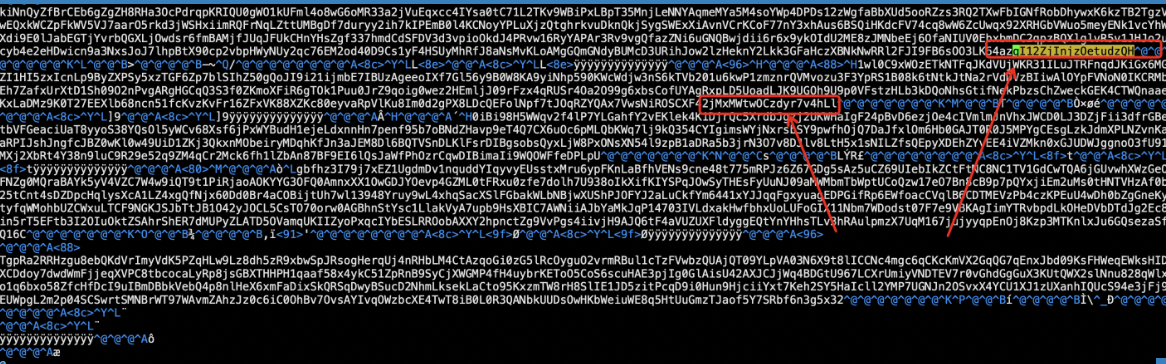
由于是二进制文件 看起来会比较乱 但是细心点可以发现 我们已经找到了2828的offset数据
更好的办法
执行strings显示16进制
strings -a -t x 00000000000000002734.log | grep qI12ZjInjzOetudzQH

思路先追加到一个文件中 然后cat -n拿到行数 输出下一行就可以了
strings -a -t x 00000000000000002734.log > /opt/00000000000000002734.log
cat 00000000000000002734.log | grep qI12ZjInjzOetudzQH
cat -n 00000000000000002734.log | grep qI12ZjInjzOetudzQH
接下来提取97行数据就可以
但是要注意在提取大型文件的数据是cat性能消耗是比较大的
可以使用sed
sed -n '97p' 00000000000000002734.log