CDP实操--HDFS角色迁移
hdfs角色迁移功能在cdp页面中就可以实现该功能,迁移的时间与namenode元数据大小,以及block数量多少有关,注意迁移过程中集群需要关闭,要预留出操作时间窗口。
1、页面选择迁移角色

2、设置源主机和目标主机


3、迁移完毕后角色分配

FAQ
Q:datanode组件不健康,显示连接不上namenode

A:网络问题导致,互通后问题解决

hdfs角色迁移功能在cdp页面中就可以实现该功能,迁移的时间与namenode元数据大小,以及block数量多少有关,注意迁移过程中集群需要关闭,要预留出操作时间窗口。
Q:datanode组件不健康,显示连接不上namenode
A:网络问题导致,互通后问题解决
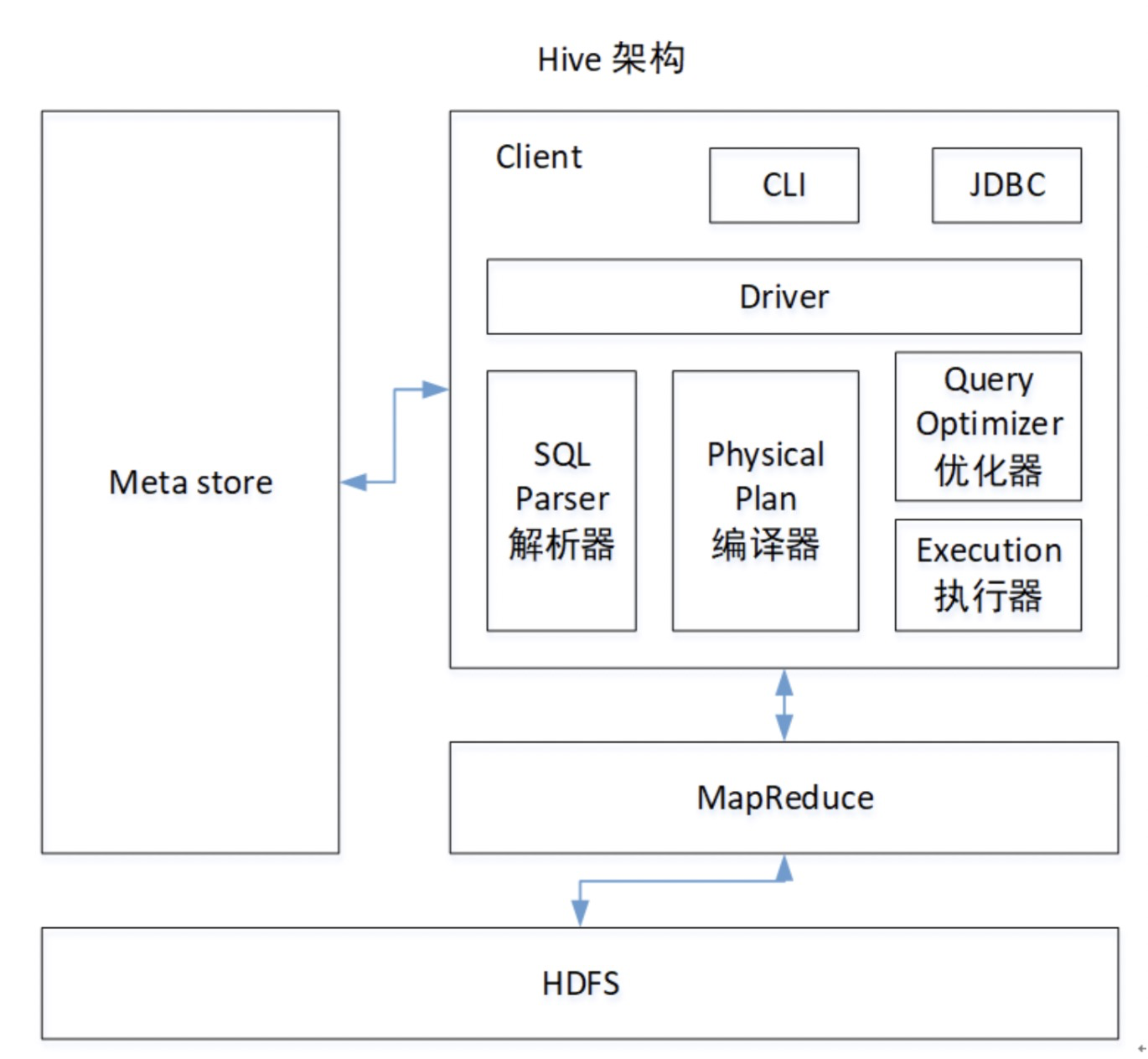
1、Hive产生背景MapReduce编程的不便性HDFS上的文件缺少Schema(表名,名称,ID等,为数据库对象的集合)2、Hive是什么Hive的使用场景是什么?基于Hadoop做一些数据清洗啊...

在全球数字化变革的背景下,为适应数字经济环境下企业生存发展和市场变化的需要,企业进行主动的、系统性、整体性的数字化转型升级。大数据、云计算、人工智能、区块链等新一代信息通信技术为企业的数字化转型提供了...
Gartner于今日发布企业机构在2023年需要探索的十大战略技术趋势。Gartner杰出研究副总裁Frances Karamouzis表示:“为了在经济动荡时期增加企业机构的盈利,首席信息官和IT高...
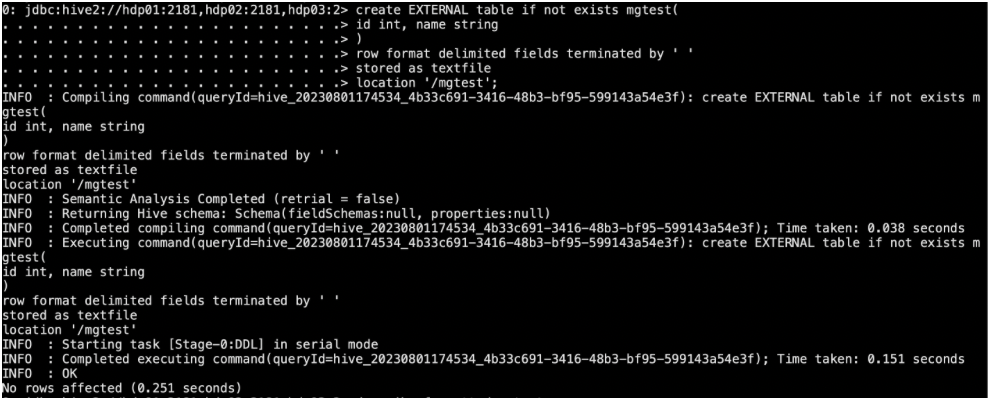
删除外部表操作例:1.首先我们创建一个外部表create EXTERNAL table if not exists mgtest(id int, name string)row format deli...
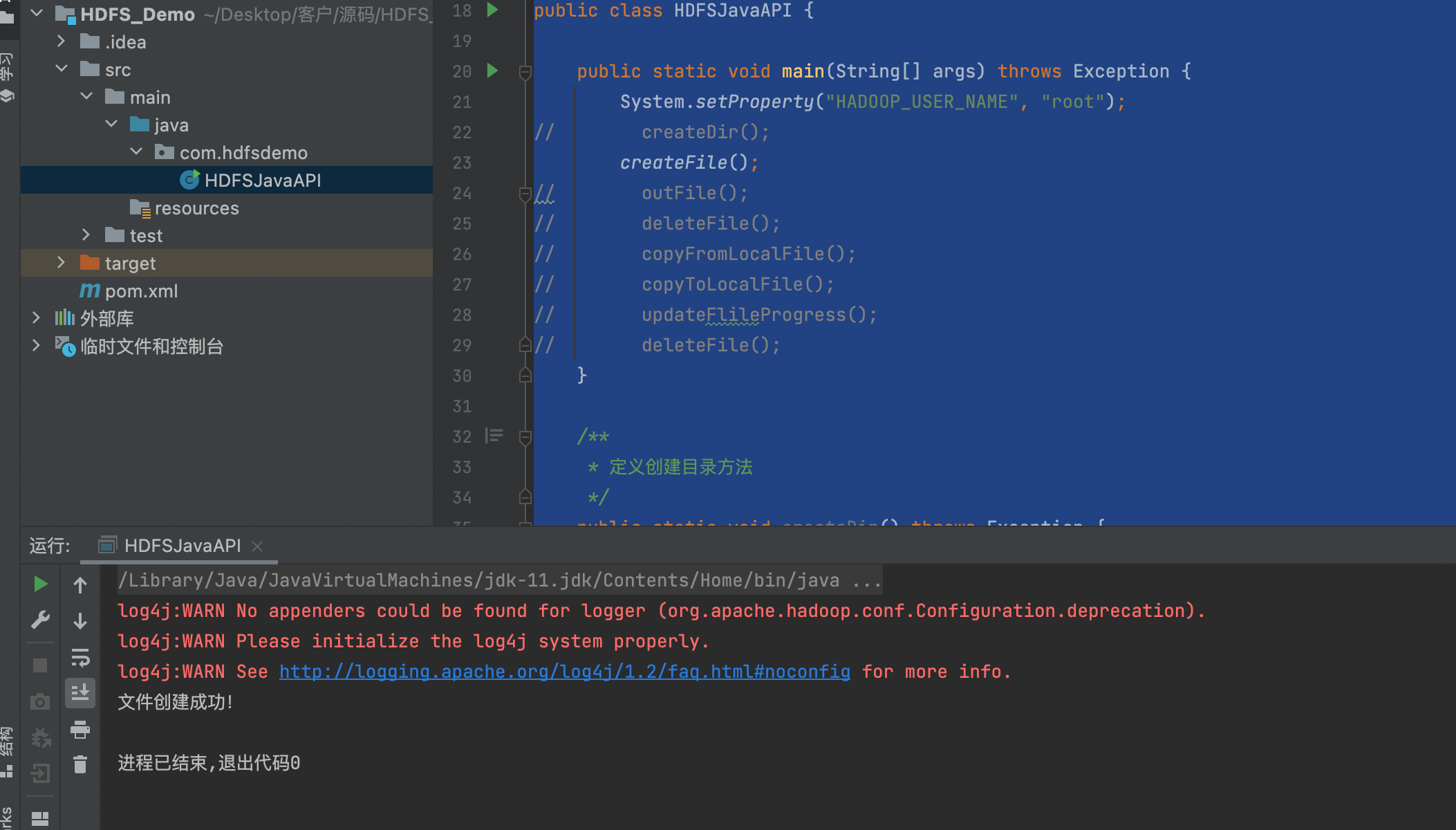
前期工作首先就是安装maven在win系统下不配置hadoop环境,直接运行代码会报错,显示缺少winutils.exe 和 hadoop.dll 两个文件首先添加pom.xml文件 <dep...
1 tmpfs介绍tmpfs是一种虚拟内存文件系统,正如这个定义它最大的特点就是它的存储空间在VM里面 VM是由linux内核里面的vm子系统管理的东...
