Java-API对HDFS的操作(IDEA版)
前期工作
首先就是安装maven
在win系统下不配置hadoop环境,直接运行代码会报错,显示缺少winutils.exe 和 hadoop.dll 两个文件
首先添加pom.xml文件
<dependencies>
<!-- Hadoop所需依赖包 -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.3.1</version>
</dependency>
<!-- junit测试依赖 -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>RELEASE</version>
</dependency>
</dependencies>
</project>
创建一个HDFSJavaAPI的类
创建目录
package com.hdfsdemo;
import java.io.BufferedInputStream;
import java.io.FileInputStream;
import java.io.InputStream;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.util.Progressable;
/**
* HDFS Java API文件操作
*/
public class HDFSJavaAPI {
public static void main(String[] args) throws Exception {
System.setProperty("HADOOP_USER_NAME", "root");
createDir();
createFile();
outFile();
deleteFile();
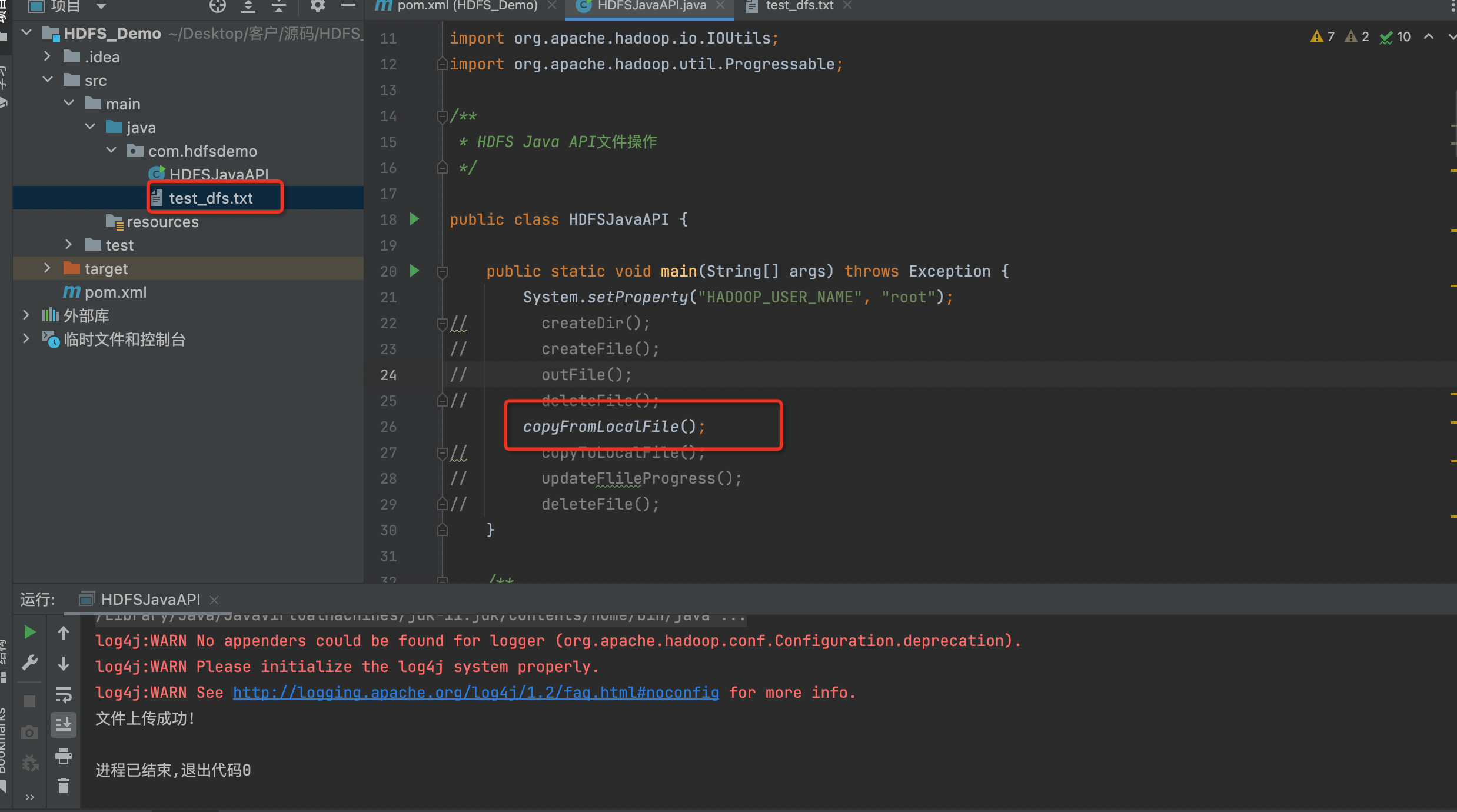
copyFromLocalFile();
copyToLocalFile();
updateFlileProgress();
deleteFile();
}
/**
* 定义创建目录方法
*/
public static void createDir() throws Exception {
Configuration conf = new Configuration();
conf.set("fs.default.name", "hdfs://172.16.121.194:8020");
FileSystem hdfs = FileSystem.get(conf);
// 创建目录
boolean isok = hdfs.mkdirs(new Path("hdfs:/mydir"));
if (isok) {
System.out.println("创建目录成功!");
} else {
System.out.println("创建目录失败!");
}
hdfs.close();
}
/**
* 定义创建文件方法
*/
public static void createFile() throws Exception {
Configuration conf = new Configuration();
conf.set("fs.default.name", "hdfs://172.16.121.194:8020");
FileSystem fs = FileSystem.get(conf);
// 打开一个输出流
FSDataOutputStream outputStream = fs.create(new Path(
"hdfs:/newfile2.txt"));
// 写入文件内容
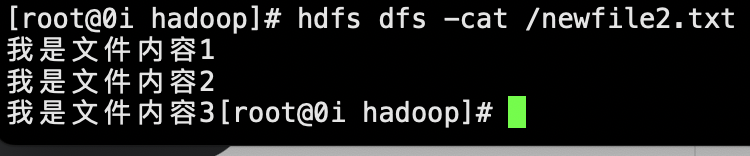
outputStream.write("我是文件内容1\n我是文件内容2\n我是文件内容3".getBytes());
outputStream.close();
fs.close();
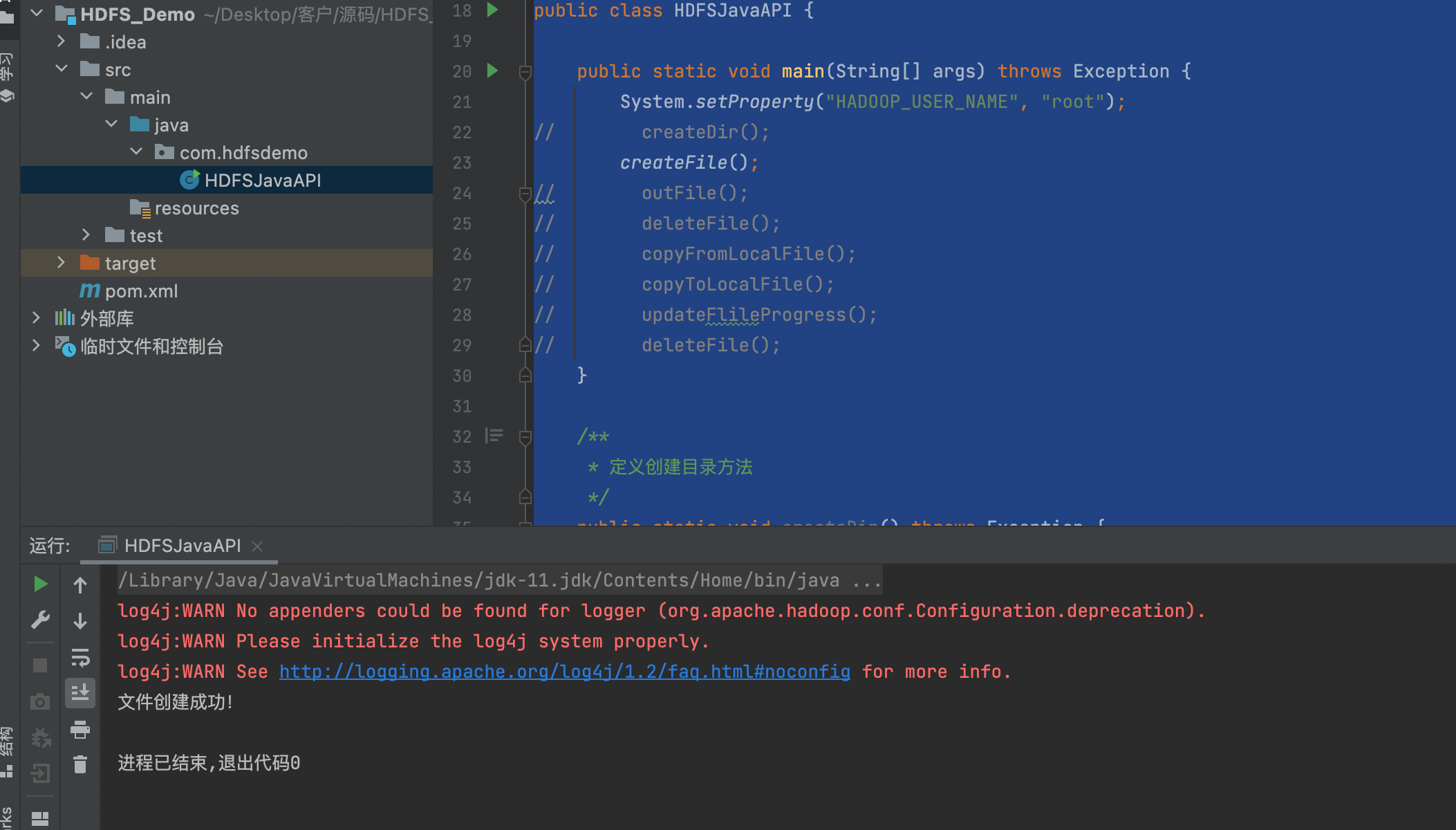
System.out.println("文件创建成功!");
}
// 删除文件
public static void deleteFile() throws Exception {
Configuration conf = new Configuration();
conf.set("fs.default.name", "hdfs://172.16.121.194:8020");
FileSystem fs = FileSystem.get(conf);
Path path = new Path("hdfs:/newfile2.txt");
boolean isok = fs.deleteOnExit(path);
if (isok) {
System.out.println("删除成功!");
} else {
System.out.println("删除失败!");
}
fs.close();
}
// 复制上传本地文件
public static void copyFromLocalFile() throws Exception {
// 1.创建配置器
Configuration conf = new Configuration();
conf.set("fs.default.name", "hdfs://172.16.121.194:8020");
// 2.取得FileSystem文件系统 实例
FileSystem fs = FileSystem.get(conf);
// 3.创建可供hadoop使用的文件系统路径
Path src = new Path("D:/copy_test.txt"); // 本地目录/文件
Path dst = new Path("hdfs:/"); // 目标目录/文件
// 4.拷贝上传本地文件(本地文件,目标路径) 至HDFS文件系统中
fs.copyFromLocalFile(src, dst);
System.out.println("文件上传成功!");
}
// 监控文件上传进度
public static void updateFlileProgress() throws Exception {
Configuration conf = new Configuration();
conf.set("fs.default.name", "hdfs://172.16.121.194:8020");
InputStream in = new BufferedInputStream(
new FileInputStream("D:/soft/test.zip"));
FileSystem fs = FileSystem.get(conf);
//上传文件并监控上传进度
FSDataOutputStream outputStream = fs.create(new Path("hdfs:/test.zip"),
new Progressable() {
public void progress() {//回调方法显示进度
System.out.print(".");
}
});
IOUtils.copyBytes(in, outputStream, 4096, false);
}
// 复制下载文件
public static void copyToLocalFile() throws Exception {
// 1.创建配置器
Configuration conf = new Configuration();
conf.set("fs.default.name", "hdfs://172.16.121.194:8020");
// 2.取得FileSystem文件系统 实例
FileSystem fs = FileSystem.get(conf);
// 3.创建可供hadoop使用的文件系统路径
Path src = new Path("hdfs:/newfile2.txt");// 目标目录/文件
Path dst = new Path("D:/new.txt"); // 本地目录/文件
// 4.从HDFS文件系统中拷贝下载文件(目标路径,本地文件)至本地
// fs.copyToLocalFile(src, dst);
fs.copyToLocalFile(false, src, dst, true);
System.out.println("文件下载成功!");
}
// 查看文件内容并输出
public static void outFile() throws Exception {
// 1.创建配置器
Configuration conf = new Configuration();
conf.set("fs.default.name", "hdfs://172.16.121.194:8020");
// 2.取得FileSystem文件系统 实例
FileSystem fs = FileSystem.get(conf);
InputStream in = fs.open(new Path("hdfs:/newfile2.txt"));
IOUtils.copyBytes(in, System.out, 4096, false);
IOUtils.closeStream(in);
}
}
上面代码中的参数"hdfs://hadoop1:8020"是hadoop配置文件中core-site.xml的配置信息:fs.defaultFS,
例如要创建一个.txt文件
只需要调用createFile();
例如调用上传文件只需要调用copyFromLocalFile();