Hive架构图及Hive SQL的执行流程
1、Hive产生背景
MapReduce编程的不便性
HDFS上的文件缺少Schema(表名,名称,ID等,为数据库对象的集合)
2、Hive是什么
Hive的使用场景是什么?
基于Hadoop做一些数据清洗啊(ETL)、报表啊、数据分析
可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能。
Hive是SQL解析引擎,它将SQL语句转译成M/R Job然后在Hadoop执行。
由Facebook开源,最初用于解决海量结构化的日志数据统计问题
构建在Hadoop之上的数据仓库
Hive定义了一种类SQL查询语言:HQL(类似SQL但不完全相同)
通常用于进行离线数据处理(早期采用MapReduce)
底层支持多种不同的执行引擎(现在可以直接把Hive跑在Spark上面)
Hive底层的执行引擎有:MapReduce、Tez、Spark
3、Hive 特点
Hive 最大的特点是 Hive 通过类 SQL 来分析大数据,而避免了写 MapReduce 程序来分析数据,这样使得分析数据更容易
Hive 是将数据映射成数据库和一张张的表,库和表的元数据信息一般存在关系型数据库上(比如 MySQL)
Hive 本身并不提供数据的存储功能,数据一般都是存储在 HDFS 上的(对数据完整性、格式要求并不严格)
Hive 很容易扩展自己的存储能力和计算能力,这个是继承自 hadoop 的(适用于大规模的并行计算)
Hive 是专为 OLAP(在线分析处理) 设计,不支持事务
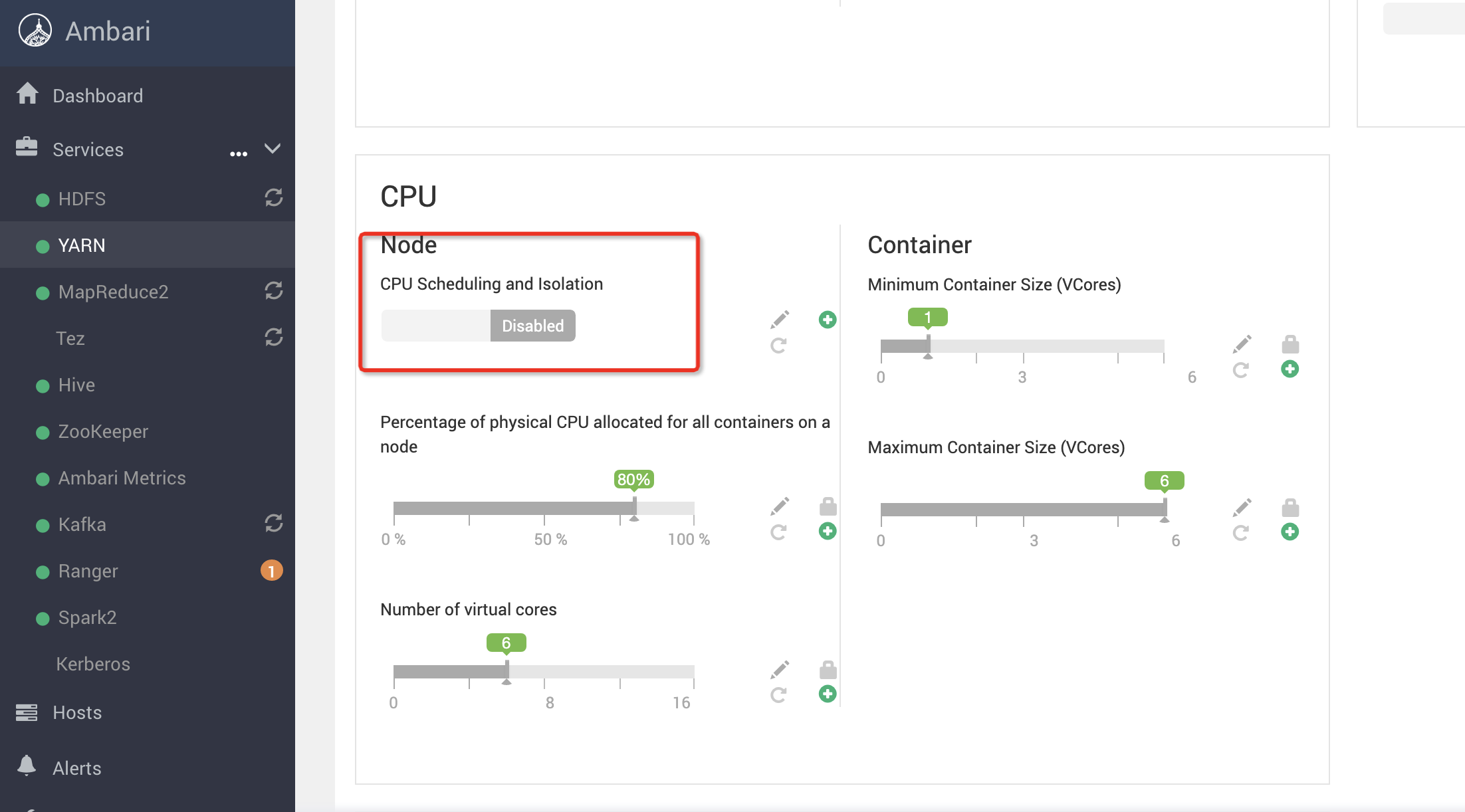
4、Hive体系架构
Hive是C/S模式
客户端:
Client端有JDBC/ODBC和Thrift Client,可远程访问Hive
可以通过shell脚本的方式访问,或者通过Thrift协议,按照平时编写JDBC的方式完成对Hive的数据操作
Server:CLI、Thrift Server、HWI(Hive web Interface)、Driver、Metastore
其中CLI、Thrift Server、HWI是暴露给Client访问的独立部署的Hive服务
Driver、Metastore是Hive内部组件,Metastore还可以供第三方SQL on Hadoop框架使用
beeine(Hive 0.11引入),作为Hive JDBC Client访问HiveServer2,解决了CLI并发访问问题
Driver:
输入了sql字符串,对sql字符串进行解析,转化程抽象语法树,再转化成逻辑计划,然后使用优化工具对逻辑计划进行优化,最终生成物理计划(序列化反序列化,UDF函数),交给Execution执行引擎,提交到MapReduce上执行(输入和输出可以是本地的也可以是HDFS/Hbase)见下图的hive架构
Metastore:
Metastore进行元数据管理:Derby(内置 )、Mysql;Derby:Derby只接受一个Hive的会话访问;Mysql:Hive跑在Hadoop之上的,Mysql进行主备(定时同步操作)

由上图可知,hadoop 和 mapreduce 是 hive 架构的根基。
MetaStore:存储和管理Hive的元数据,使用关系数据库来保存元数据信息。
解析器和编译器:将SQL语句生成语法树,然后再生成DAG形式的Job链,成为逻辑计划
优化器:只提供了基于规则的优化
列过滤:去除查询中不需要的列
行过滤:Where条件判断等在TableScan阶段就进行过滤,利用Partition信息,只读取符合条件的Partition
谓词下推:减少后面的数据量
Join方式
。 Map端join: 调整Join顺序,确保以大表作为驱动表,小表载入所有mapper内存中
。 shuffle join:按照hash函数,将两张表的数据发送给join
。对于数据分布不均衡的表Group by时,为避免数据集中到少数的reducer上,分成两个map-reduce阶段。第一个阶段先用Distinct列进行shuffle,然后在reduce端部分聚合,减小数据规模,第二个map-reduce阶段再按group-by列聚合。
。 sort merge join:排序,按照顺序切割数据,相同的范围发送给相同的节点(运行前在后台创建立两张排序表,或者建表的时候指定)
。 在map端用hash进行部分聚合,减小reduce端数据处理规模。
执行器:执行器将DAG转换为MR任务。执行器会顺序执行其中所有的Job,如果Job不存在依赖关系,采用并发的方式进行执行。
5、基于Hadoop上的Hive SQL的执行流程

sql写出来以后只是一些字符串的拼接,所以要经过一系列的解析处理,才能最终变成集群上的执行的作业
1.Parser:将sql解析为AST(抽象语法树),会进行语法校验,AST本质还是字符串
2.Analyzer:语法解析,生成QB(query block)
3.Logicl Plan:逻辑执行计划解析,生成一堆Opertator Tree
4.Logical optimizer:进行逻辑执行计划优化,生成一堆优化后的Opertator Tree
5.Phsical plan:物理执行计划解析,生成tasktree
6.Phsical Optimizer:进行物理执行计划优化,生成优化后的tasktree,该任务即是集群上的执行的作业
结论:经过以上的六步,普通的字符串sql被解析映射成了集群上的执行任务,最重要的两步是 逻辑执行计划优化和物理执行计划优化(图中红线圈画)