Java-API-MapReduce的操作WordCount篇
首先就是pom文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>HDFS_Demo</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>11</maven.compiler.source>
<maven.compiler.target>11</maven.compiler.target>
<hadoop.version>3.3.1</hadoop.version>
</properties>
<dependencies>
<!-- Hadoop所需依赖包 -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<!--mapreduce-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-jobclient</artifactId>
<version>${hadoop.version}</version>
</dependency>
</dependencies>
</project>
代码(idea跑本地文件的)
package com.mapreduce;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
//静态内部类(静态内部类只能访问外部类的静态成员)
public static class WordCountMapper extends Mapper<LongWritable, Text, Text,IntWritable>{
// #2
private Text mapOutPutKey=new Text();
private final static IntWritable mapOutPutValue = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
// #1 方式1
// String [] words = value.toString().split(" ");//直接split性能较低,或参考
// for (String word : words) {
// context.write(new Text(word), new IntWritable(1));
// }
// #2 方式2 效率高
StringTokenizer stringTokenizer = new StringTokenizer(value.toString());
while(stringTokenizer.hasMoreTokens()){
String wordValue = stringTokenizer.nextToken();
mapOutPutKey.set(wordValue);
context.write(mapOutPutKey,mapOutPutValue);
}
}
}
public static class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
// 注意 reduce的输入类型是个迭代器 Iterable<IntWritable> value,因为map将分组后的数据传过来,map会做group,将相同key的value合并在一起,放到一个集合中,如<hadoop,list(1,1,...)>
@Override
protected void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable intWritable : values) {
// total
sum += intWritable.get();
}
context.write(key, new IntWritable(sum));//或 new IntWritable().set(sum)
}
}
//dirver(将dirver提出来了)
public int run(String[] args) throws Exception {
//1.get configuration
Configuration conf = new Configuration();
// conf.set("mapreduce.framework.name", "local");
//2.create job
Job job = Job.getInstance(conf,this.getClass().getSimpleName());
// run jar
job.setJarByClass(WordCount.class);
//3.set job (input -> map -> reduce -> output)
//3.1 map
job.setMapperClass(WordCountMapper.class);
//设置Map端输出key类和输出value类
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//3.2 reduce
job.setReducerClass(WordCountReducer.class);
//设置Reduce端输出key类和输出value类
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//3.3
//input path
FileInputFormat.addInputPath(job,new Path("/Users/mac/Desktop/客户/源码/HDFS_Demo/src/main/resources/input/test_dfs.txt"));
//output path
FileOutputFormat.setOutputPath(job,new Path("/Users/mac/Desktop/客户/源码/HDFS_Demo/src/main/resources/output"));
//submit job 提交任务
boolean isSuccess = job.waitForCompletion(true);//表示打印日志信息
System.out.println(isSuccess);
return isSuccess ? 0 : 1;
}
// run program 运行整个工程
public static void main(String[] args) throws Exception, ClassNotFoundException, InterruptedException {
int status = new WordCount().run(args);
// 结束程序
System.exit(status);
}
}
注意路径
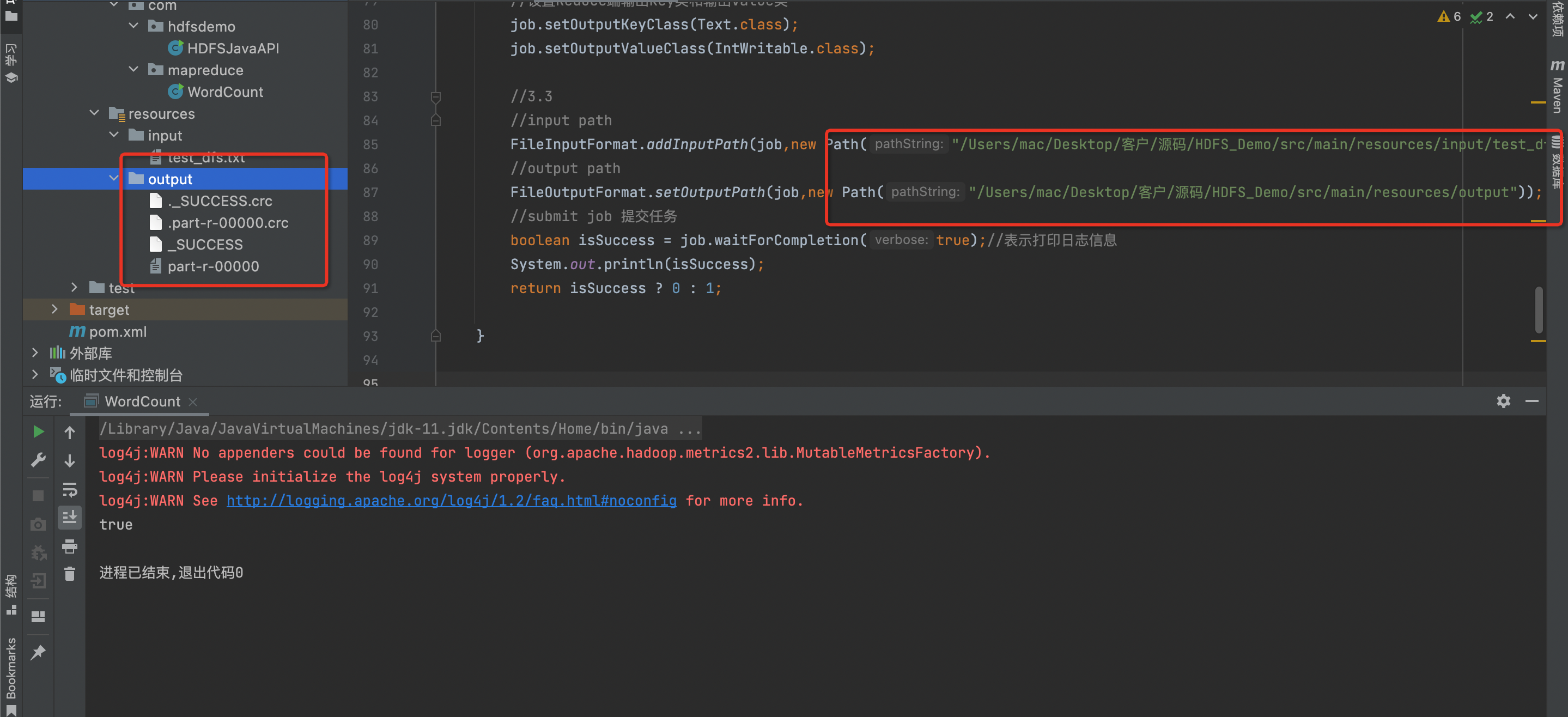
如果需要跑hadoop文件需要更改路径打包上传hadoop
Hdfs创建目录
创建目录:
hdfs dfs -mkdir -p /input
删除目录:
hdfs dfs -rm -r /output
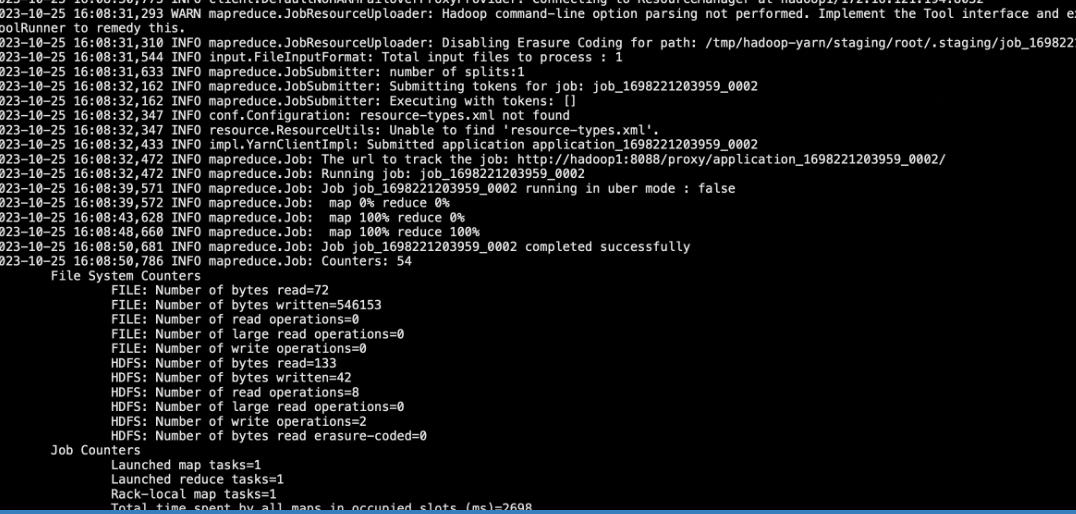
提交jar
hadoop jar HDFS_Demo-1.0-SNAPSHOT.jar com.mapreduce.WordCount