hadoop集群集成Iceberg操作指导
hadoop集群集成Iceberg操作指导书
一、 准备工作
1. 大数据集群运行正常,完成hive、trino、spark、flink部署,并可以正常使用相关组件引擎提交任务
2. 通过https://iceberg.apache.org/releases/下载相关iceberg jar包,主要jar包为spark、hive、flink三种,请根据需要集成的版本进行下载(spark需要注意scala版本)
3. Flink可以使用yarn-session模式和pre-job模式成功提交任务
Trino可对接hive正常进行查询操作
二、 Hive集成iceberg
1. 下载相关jar包,具体链接参考1.2
2. 拷贝libfb303-0.9.3.jar至hadoop目录下
cp $HIVE_HOME/lib/libfb303-0.9.3.jar /opt/hadoop/share/hadoop/mapreduce/lib
3. 修改hive-site.xml相关配置
cd $HIVE_HOME/conf vim hive-site.xml #添加如下配置 <!--以下配置为应用程序全局启用Hive支持--> <property> <name>iceberg.engine.hive.enabled</name> <value>true</value> </property> <!--设置白名单可在客户端set iceberg和yarn相关参数--> <property> <name>hive.security.authorization.sqlstd.confwhitelist</name> <value>mapred.*|hive.*|mapreduce.*|spark.*|iceberg.*i|yarn.*</value> </property> <property> <name>hive.security.authorization.sqlstd.confwhitelist.append</name> <value>mapred.*|hive.*|mapreduce.*|spark.*|iceberg.*|yarn.*</value> </property> <!--Tez相关参数设置--> <property> <name>tez.mrreader.config.update.properties</name> <value>hive.io.file.readcolumn.names,hive.io.file.readcolumn.ids</value> </property> <!--关闭向量化--> <property> <name>hive.vectorized.execution.enabled</name> <value>false</value> </property> <!--设置iceberg引用jar包路径--> <property> <name>hive.aux.jars.path</name> <value>/opt/hive/iceberg-hive-runtime-1.0.0.jar</value> </property>
4. 重启hive和metastore服务
bash $HIVE_HOME/bin/stop_hive.sh bash $HIVE_HOME/bin/start_hive.sh
5. 通过beeline进入
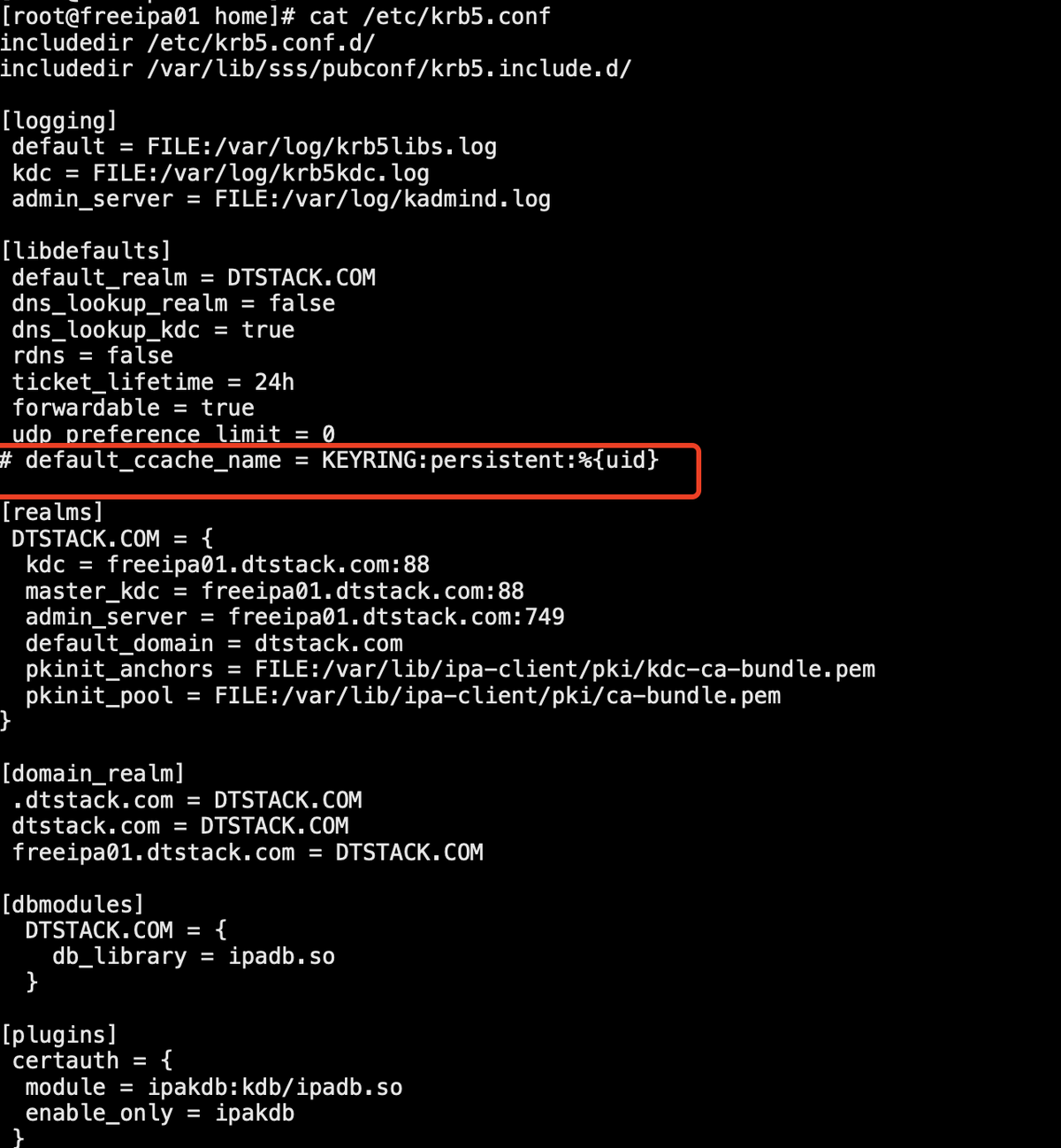
beeline -u 'jdbc:hive2://host:10000/default;principal=hive/principal@realm'
6. 执行如下命令选择catalog
注:Hive本身没有Catalog的概念,但是Iceberg有Catalog。所以Hive将Catalog的信息用键值对的属性来实现,这样建表的时候就可以直接使用创建的Catalog,Hive集成Iceberg支持Hive Catalog和Hadoop Catalog。
注册名为hadoop的HadoopCatalog(标红部分注册名可自定义)
注
:此处请修改cluster_nameservice为实际集群的nameservice
SET iceberg.catalog.hadoop.type=hadoop; SET iceberg.catalog.hadoop.warehouse=hdfs://cluster_nameservice/user/hive/warehouse;
注册名为another_hive的HiveCatalog(标红部分注册名可自定义)
注:此处请修改第二配置值和第四配置值为实际集群值
SET iceberg.catalog.another_hive.type=hive; SET iceberg.catalog.another_hive.uri=thrift://example.com:9083; SET iceberg.catalog.another_hive.clients=10; SET iceberg.catalog.another_hive.warehouse=hdfs://example.com:8020/warehouse;
7. 在hive里创建iceberg表(此处以hadoop catalog为例进行操作)
#内表
CREATE TABLE table_g (
id bigint,
name string
) STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
location '/user/hive/warehouse/default/table_g'
TBLPROPERTIES ('iceberg.catalog'='hadoop');
#外表
CREATE EXTERNAL TABLE z (
i int
) STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
location '/user/hive/warehouse/z'
TBLPROPERTIES ('iceberg.catalog'='hadoop');8. 查看创建的表,确认为iceberg表

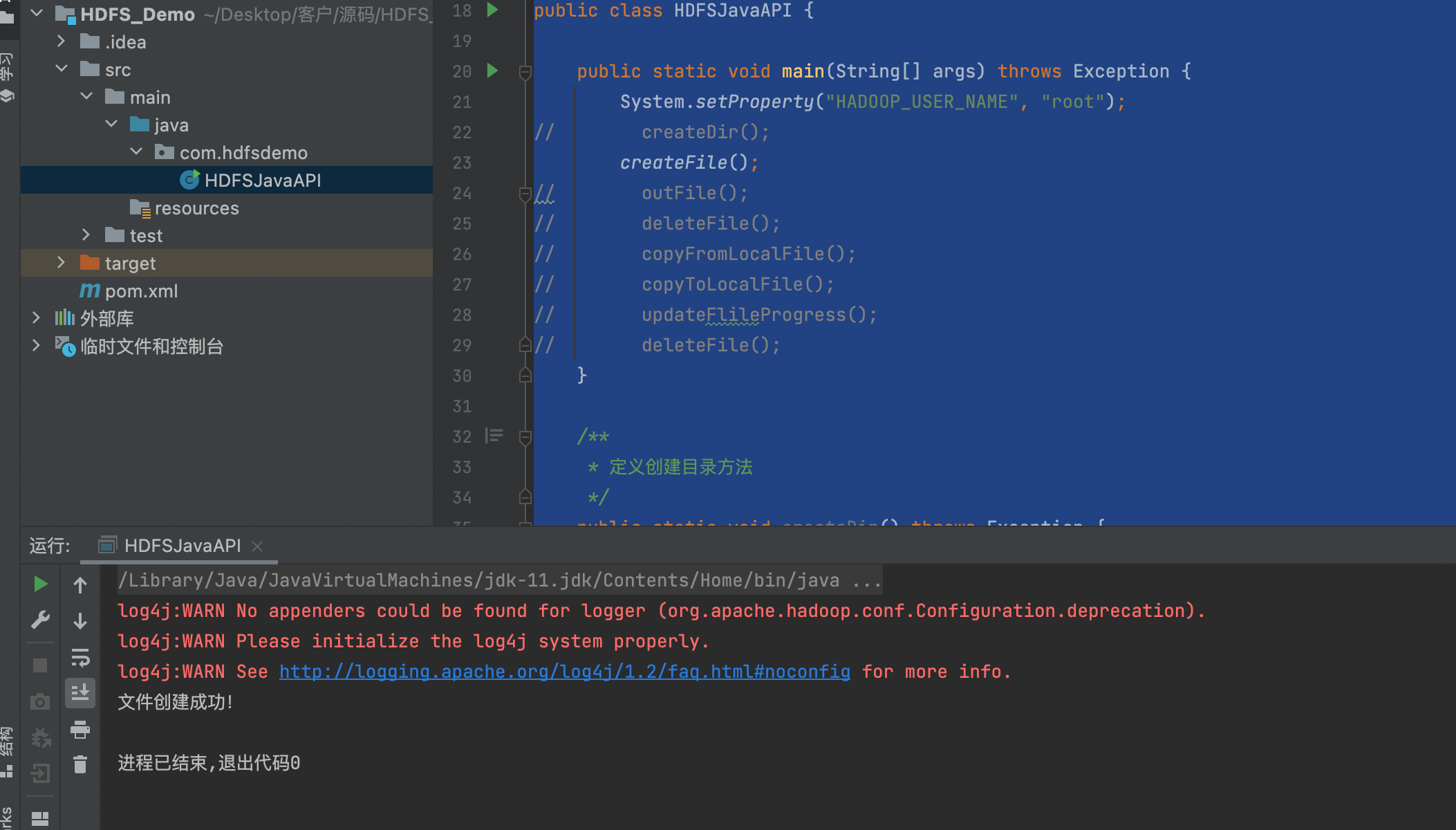
9. 测试插入和查询
#设置计算引擎为mr,tez引擎无法在hive3版本调用iceberg,在hive4版本可以 set hive.execution.engine=mr; insert into table_g values(1,'aaa'); select * from table_g;
10. 验证截图如下:
插入


查询:

三、 Spark集成iceberg
1. 将iceberg-spark-runtime-3.3_2.12-x.x.x.jar放入spark目录下的jars目录中,并修改属组和权限,和其他jar包保持一致
(请根据实际情形修改标红部分)
cp /opt/iceberg-spark-runtime-3.3_2.12-*.jar $SPARK_HOME/jars chown spark:spark iceberg-spark-runtime-*.jar chmod xxx iceberg-spark-runtime-*.jar
2. 运行spark-sql进入sparksql客户端
(标红部分修改即可为hive即可加载hive类型的catalog)
spark-sql --packages org.apache.iceberg:iceberg-spark-runtime-3.2_2.12:1.0.0\ --conf spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions \ --conf spark.sql.catalog.spark_catalog=org.apache.iceberg.spark.SparkSessionCatalog \ --conf spark.sql.catalog.spark_catalog.type=hadoop \ --conf spark.sql.catalog.spark_catalog.warehouse=/user/hive/warehouse \ --conf spark.sql.catalog.local=org.apache.iceberg.spark.SparkCatalog \ --conf spark.sql.catalog.local.type=hadoop \ --conf spark.sql.catalog.local.warehouse=/user/hive/warehouse
此命令含义是为表在/user/hive/warehouse路径下的表注册一个名为local的基于路径的catalog,catalog的类型为hadoop
3. 查询刚才在hive中创建的hadoop catalog的表

四、 Flink集成iceberg
1. 从以下地址下载flinksql-hive驱动包
https://repo.maven.apache.org/maven2/org/apache/flink/flink-sql-connector-hive-3.1.2_2.12/1.14.6/
具体版本连接地址
https://repo.maven.apache.org/maven2/org/apache/flink/flink-sql-connector-hive-3.1.2_2.12/1.14.6/flink-sql-connector-hive-3.1.2_2.12-1.14.6.jar
2. 将以下jar包添加到/opt/flink/lib下
hive-exec-3.1.0.jar(hive的jar包目录中存在)
iceberg-flink-runtime-1.14-1.0.0.jar
flink-sql-connector-hive-3.1.2_2.11-1.14.4.jar
libfb303-0.9.3.jar(hive的jar包目录中存在)
3. 登陆flinksql客户端
./sql-client.sh embedded shell
4. 加载catalog(每次重新连接客户端均需重新加载)
CREATE CATALOG hadoop WITH ( 'type'='iceberg', 'catalog-type'='hadoop', 'warehouse'='/user/hive/warehouse', 'property-version'='1' );
5. 进入名为hadoop的catalog
use catalog hadoop;
6. 设置flinksql提交模式
set 'execution.target' = 'yarn-per-job';
7. 可以查询到刚才在hive中创建的表

8. 执行查询语句,等待job完成后即可查询出结果(此处需要等待1-2min)

五、 Trino集成iceberg
1. 在/opt/trino/etc/catalog下添加文件iceberg.properties
配置如下:(部分参数需要根据实际情况修改)
Trino不支持类型为hadoop的catalog
connector.name=iceberg hive.metastore.uri=thrift://hadoop1.dtstack.com:9083 hive.config.resources=/opt/hadoop/etc/hadoop/core-site.xml,/opt/hadoop/etc/hadoop/hdfs-site.xml hive.metastore.authentication.type=kerberos hive.metastore.thrift.impersonation.enabled=false hive.metastore.service.principal=hive/hadoop1.dtstack.com@DTSTACK.COM hive.metastore.client.principal=hive/hadoop1.dtstack.com@DTSTACK.COM hive.metastore.client.keytab=/opt/keytab/hive.keytab hive.hdfs.authentication.type=KERBEROS hive.hdfs.impersonation.enabled=false hive.hdfs.trino.principal=trino/_HOST@DTSTACK.COM hive.hdfs.trino.keytab=/opt/keytab/trino.keytab iceberg.security=ALLOW_ALL
2. 查询在其他引擎创建的类型为hive的catalog表