HBase使用snappy压缩
安装编译环境依赖
yum install -y automake autoconf gcc-c++ cmake libedit libtool openssl-devel ncurses-devel
安装maven(本地这种模式可以忽略)
yum install maven
首先安装snappy
每个节点下载snappy源码包 并解压了
cd /opt
wget https://src.fedoraproject.org/repo/pkgs/snappy/snappy-1.1.3.tar.gz/7358c82f133dc77798e4c2062a749b73/snappy-1.1.3.tar.gz
tar -zxvf snappy-1.1.3.tar.gz
编译并安装snappy
cd snappy-1.1.3
./configure
make
sudo make install
验证安装完成
ll /usr/local/lib/ | grep snappy
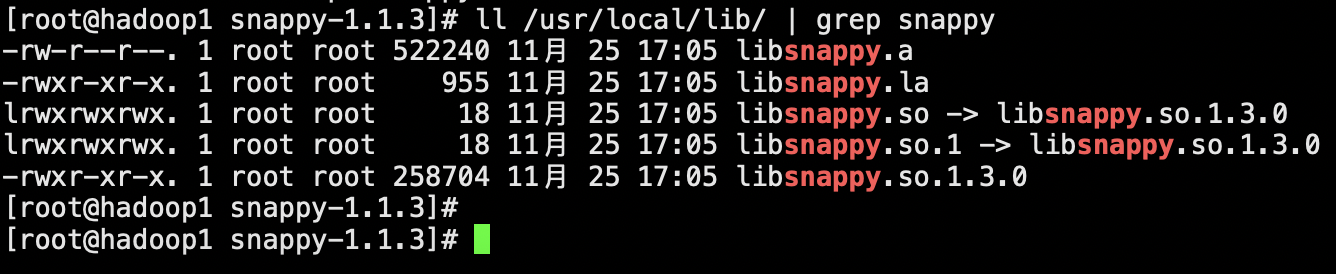
编译安装默认是安装到/usr/local/lib下的,拷贝到/usr/lib64下
sudo cp -dr /usr/local/lib/* /usr/lib64
安装HADOOP-SNAPPY
安装hadoop-snappy需要一系列的依赖
sudo yum -y install gcc c++ autoconf automake libtool
安装
git clone https://github.com/electrum/hadoop-snappy.git
cd hadoop-snappy && mvn package

Hadoop配置snappy 添加snappy本地库到 $HADOOP_HOME/lib/native/ 目录下
cp -dr /usr/local/lib/* /opt/app/hadoop-3.3.1/lib/native
将hadoop-snappy-0.0.1-SNAPSHOT.jar拷贝到 $HADOOP_HOME/lib、snappy的library拷贝到$HADOOP_HOME/lib/native/目录下即可
cp -r /opt/hadoop-snappy/target/hadoop-snappy-0.0.1-SNAPSHOT.jar $HADOOP_HOME/lib
cp /opt/hadoop-snappy/target/hadoop-snappy-0.0.1-SNAPSHOT-tar/hadoop-snappy-0.0.1-SNAPSHOT/lib/native/Linux-amd64-64/* $HADOOP_HOME/lib/native/
在每个节点上,编辑Hadoop的配置文件core-site.xml,添加以下内容:
<property>
<name>io.compression.codecs</name>
<value>
org.apache.hadoop.io.compress.GzipCodec,
org.apache.hadoop.io.compress.DefaultCodec,
org.apache.hadoop.io.compress.BZip2Codec,
org.apache.hadoop.io.compress.SnappyCodec
</value>
</property>
<property>
<name>io.compression.codec.snappy.native</name>
<value>true</value>
</property>

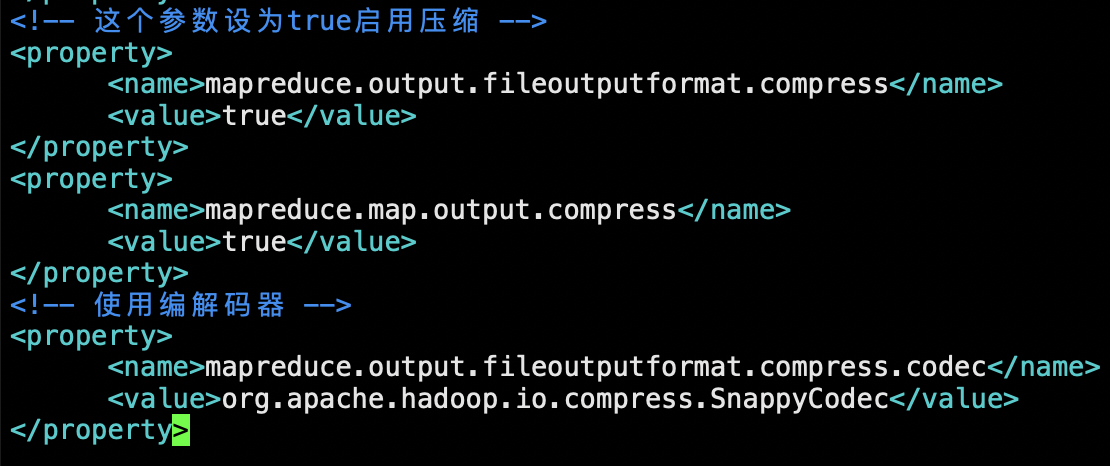
添加配置到mapred-site.xml
<!-- 这个参数设为true启用压缩 -->
<property>
<name>mapreduce.output.fileoutputformat.compress</name>
<value>true</value>
</property>
<property>
<name>mapreduce.map.output.compress</name>
<value>true</value>
</property>
<!-- 使用编解码器 -->
<property>
<name>mapreduce.output.fileoutputformat.compress.codec</name>
<value>org.apache.hadoop.io.compress.SnappyCodec</value>
</property>
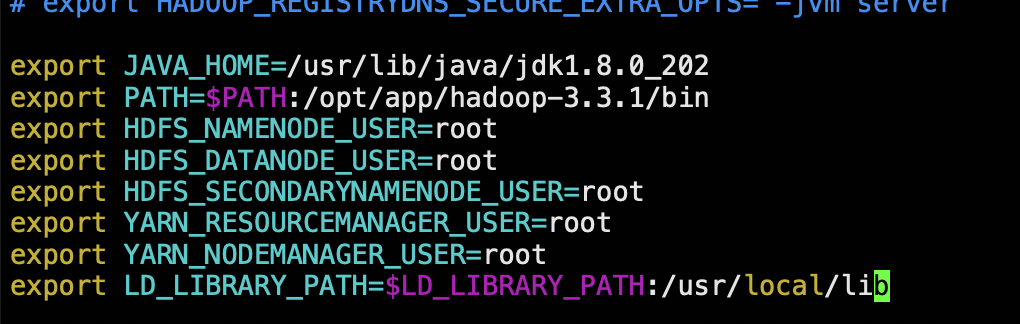
在每个节点上,编辑Hadoop的配置文件hadoop-env.sh,添加以下内容:
配置指定了Hadoop加载本地库的路径
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/lib
重启Hadoop
start-all.sh
到此配置snappy完成,下面命令是验证(其中/input是HDFS上的目录,下面随便丢几个文本文件即可。同时/output目录必须是不存在的,否则会失败)
hadoop jar /opt/app/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar wordcount /input /output11
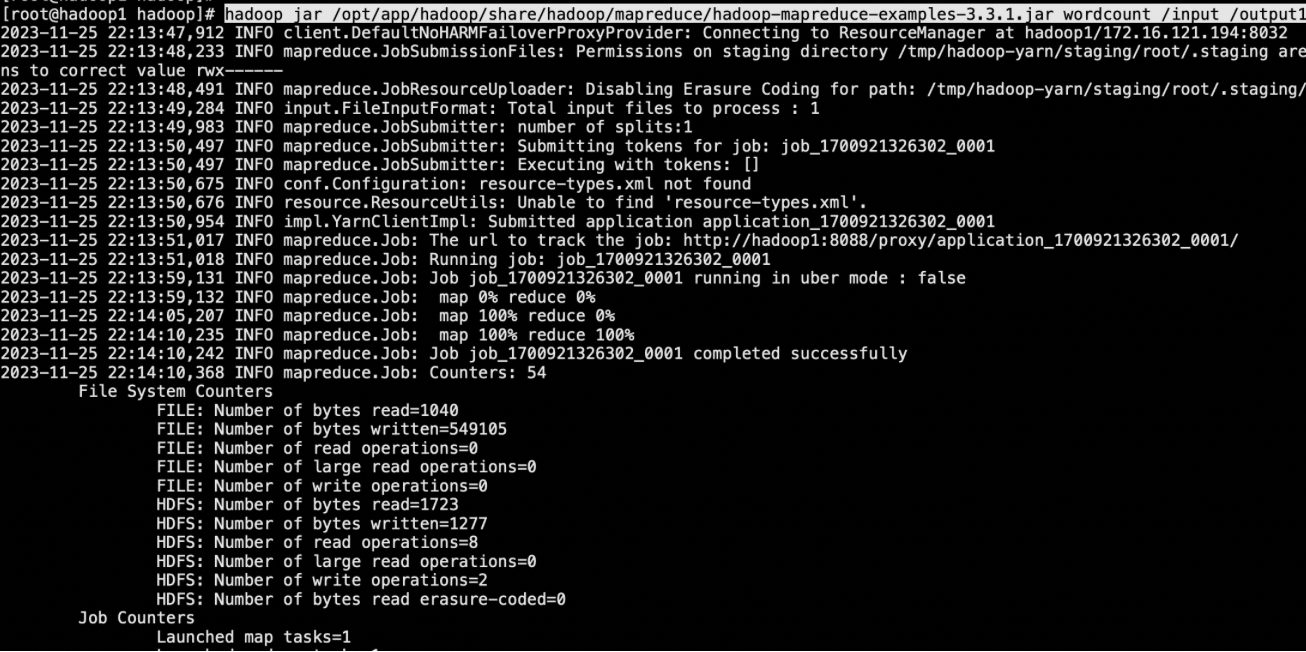
执行若成功,查看/output11目录下的文件即可
hdfs dfs -ls /output11

将hadoop-snappy-0.0.1-SNAPSHOT.jar拷贝到$HBASE_HOME/lib 目录下,同时将$HADOOP_HOME/lib/native软连接到$HBASE_HOME/lib/native/(native目录没有的话创建一个就好了)
cp /opt/hadoop-snappy/target/hadoop-snappy-0.0.1-SNAPSHOT.jar $HBASE_HOME/lib
mkdir -p /opt/app/hbase-2.1.0/lib/native
ln -s /opt/app/hadoop/lib/native /opt/app/hbase-2.1.0/lib/native/Linux-amd64-64
在每个节点上,编辑HBase的配置文件hbase-env.sh,添加以下内容:
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$HADOOP_HOME/lib/native/:/usr/local/lib/
export HBASE_LIBRARY_PATH=$HBASE_LIBRARY_PATH:$HBASE_HOME/lib/native/:/usr/local/lib/
export CLASSPATH=$CLASSPATH:$HBASE_LIBRARY_PATH
添加配置到hbase-site.xml
<property>
<name>hbase.regionserver.codecs</name>
<value>snappy</value>
</property>
重启hbase
start-hbase.sh
验证snappy压缩
在任意一个节点上,进入HBase Shell,使用CompressionTest工具验证snappy支持是否启用,并且本地库是否可以加载。例如:
hbase org.apache.hadoop.hbase.util.CompressionTest hdfs://hadoop1/hbase snappy
在HBase Shell中,创建一个使用snappy压缩的表,并查看表的描述信息。例如:
create 't1', { NAME => 'cf1', COMPRESSION => 'SNAPPY' }
describe 't1'