Hive优化之Spark执行引擎的参数优化(二)
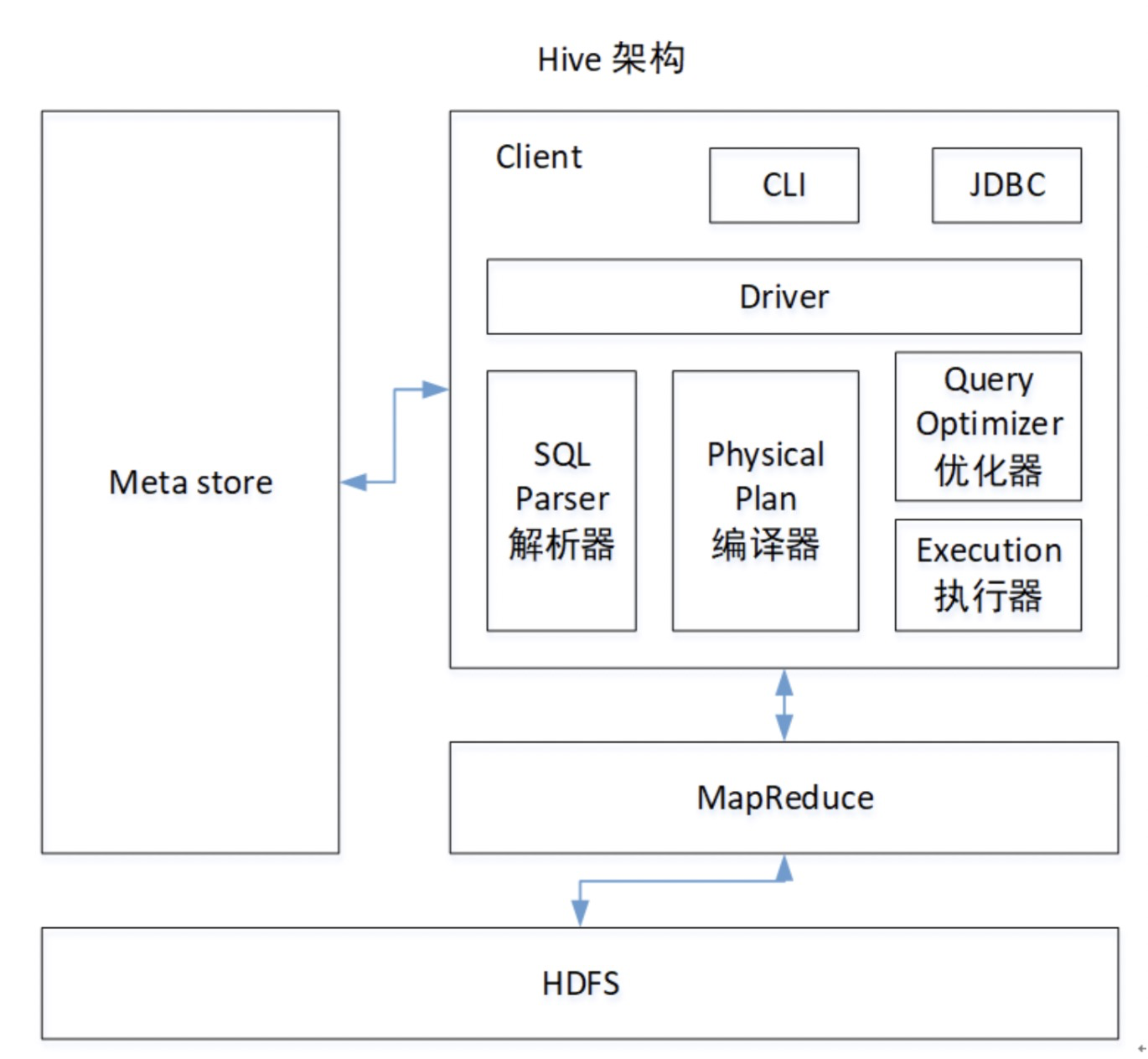
Hive是大数据领域常用的组件之一,主要是大数据离线数仓的运算,关于Hive的性能调优在日常工作和面试中是经常涉及的的一个点,因此掌握一些Hive调优是必不可少的一项技能。影响Hive效率的主要有数据倾斜、数据冗余、job的IO以及不同底层引擎配置情况和Hive本身参数和HiveSQL的执行等因素。本文主要结合实际业务情况,在底层引擎为Spark时,通过一些常见的配置参数对报错任务进行调整优化。
目前我们主要是从两个方面对复杂任务进行优化:
1、Spark资源参数优化,所谓的Spark资源参数调优,其实主要就是对Spark运行过程中各 个使用资源的地方,通过调节各种参数,来优化资源使用的效率,从而提升Spark作业的执行性能。比如说num-executors、executor-memory、executor-cores、driver-memory等。
2、Shuffle相关的参数调优,所谓shuffle参数调优,主要是针对spark运行过程中的shuffle,通过调节参数,提高shuffle的执行效率,从而提升spark作业的执行性能。比如说:spark.shuffle.memoryFraction、spark.sql.shuffle.partitions、spark.shuffle.sort.bypassMergeThreshold等。
案例1:
任务sql400行左右,较为复杂,join/聚合函数操作较多。报错后手动重试任务仍然报错。
查看任务报错日志:
.png")
关键报错信息:
Exception in thread "broadcast-exchange-0" java.lang.OutOfMemoryError: Not enough memory to build and broadcast the table to all worker nodes. As a workaround, you can either disable broadcast by setting spark.sql.autoBroadcastJoinThreshold to -1 or increase the spark driver memory by setting spark.driver.memory to a higher value
从上面可以知道,在所有的工作节点上没有足够的内存去build并且广播表,后面也设置了对应的办法:将广播置为无效或者增加spark的driver memory。我们的解决办法是excutor内存和driver内存调大,任务顺利解决,后来测试了一下只调整driver或excutor的内存,任务依然报错。
现在讲一下另一个方法将广播置为无效。官网中对于spark.sql.autoBroadcastJoinThreshold的描述如下:

由上图可知该参数默认是10M,大致意思是执行join时,这张表字节大小在10M内可以自动广播到所有工作节点。可以通过设置-1将自动广播给禁用。
将表广播到其他工作节点,会减少shuffle的过程,提升效率,如果在内存足够并且数据量过多的情况下,可以适当提高10M这个值,作为一种优化手段。如果在表都很大的情况下,建议将自动广播参数置为无效。
案例2:
某个任务已经运行了40多个小时,自动重试了3次,目前已经阻塞。查看该任务,任务中大概有10个sql语句,一个语句大概有200行左右,基本上都是union all /join /sum的操作。查看任务日志,日志中报错如下:
.png")

日志中关键报错:
org.apache.spark.shuffle.MetadataFetchFailedException: Missing an output location for shuffle 433
根据关键报错,我们一开始的方法是调大executor的内存,调大之后任务可以运行成功,耗时20分钟左右,和之前成功时耗时差不多,虽然任务执行成功,但是从耗时上看任务并没有得到很大的优化。
查看日志过程中,我们发现任务执行中形成的task数量比较多,可以通过调整分区参数进行优化。我们一开始使用spark.default.parallelism参数对分区进行调整,该参数为num- executors * executor-cores的2~3倍较为合适,设置完后重跑任务,任务运行耗时仍然20min左右,和之前差不多。因为shuffle控制分区这一块查看上面参数时,发现还有另外一个参数spark.sql.shuffle.partitions,他们两个很相似,首先是定义:
.png")
两者具体的区别:
·spark.default.parallelism只有在处理RDD时才会起作用,对Spark SQL的无效。
·spark.sql.shuffle.partitions则是对sparks SQL专用的设置。
由于task的数量是过多的,所以我们将分区设置的小一些,该参数默认是200,就调小了该参数设为50,运行成功,耗时10min,继续调小设置为10,运行成功,耗时6min,优化完成。
知识点扩展:
1.shuffle分为shuffle write和shuffle read两部分。
2.shuffle write的分区数由上一阶段的RDD分区数控制,shuffle read的分区数则是由Spark提供的一些参数控制。
3.shuffle write可以简单理解为类似于saveAsLocalDiskFile的操作,将计算的中间结果按某种规则临时放到各个executor所在的本地磁盘上。
4.shuffle read的时候数据的分区数则是由spark提供的一些参数控制。可以想到的是,如果这个参数值设置的很小,同时shuffle read的量很大,那么将会导致一个task需要处理的数据非常大,结果导致JVM crash。如果这个参数值设置的很大,造成的结果可能是task的数量过多,任务执行过慢。job和stage以及task的关系如下所示,job的划分是action操作造成的,Stage是job通过依赖关系划分出来的,一个Stage对应一个TaskSet,一个Task对应一个rdd分区。同时大量使用shuffle操作也会使task数量变多。