hive执行count和spark执行count结果不一致
【组件版本】hive on mr、spark
【问题现象】hive 执行count语句,结果条数为0,spark执行count语句能正常显示count数
【详细描述】
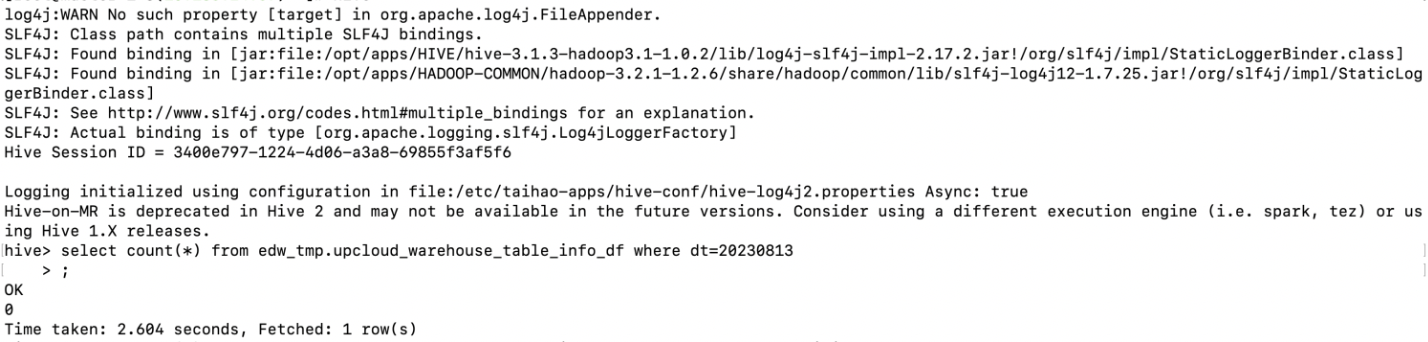
hive 执行count语句:显示count数为0.
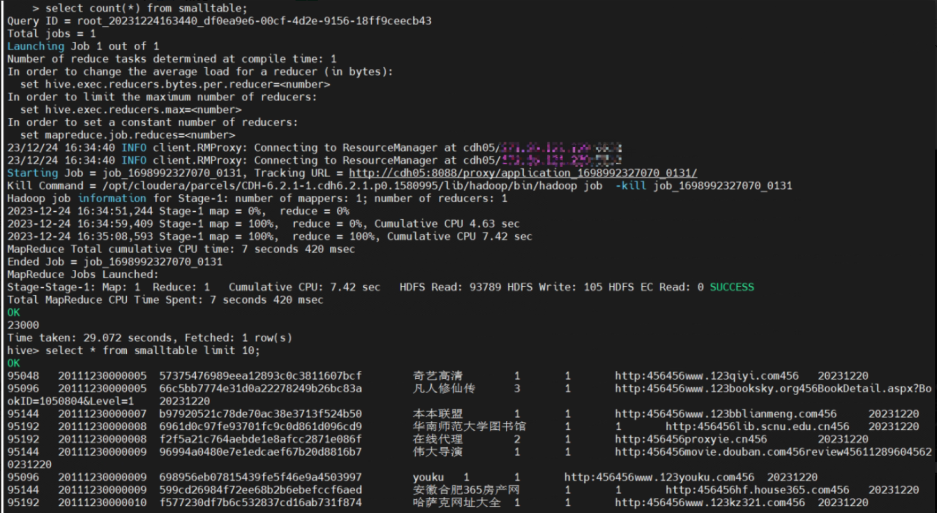
select count(*) from edw_tmp.upcloud_warehouse_table_info_df where dt=20230813;
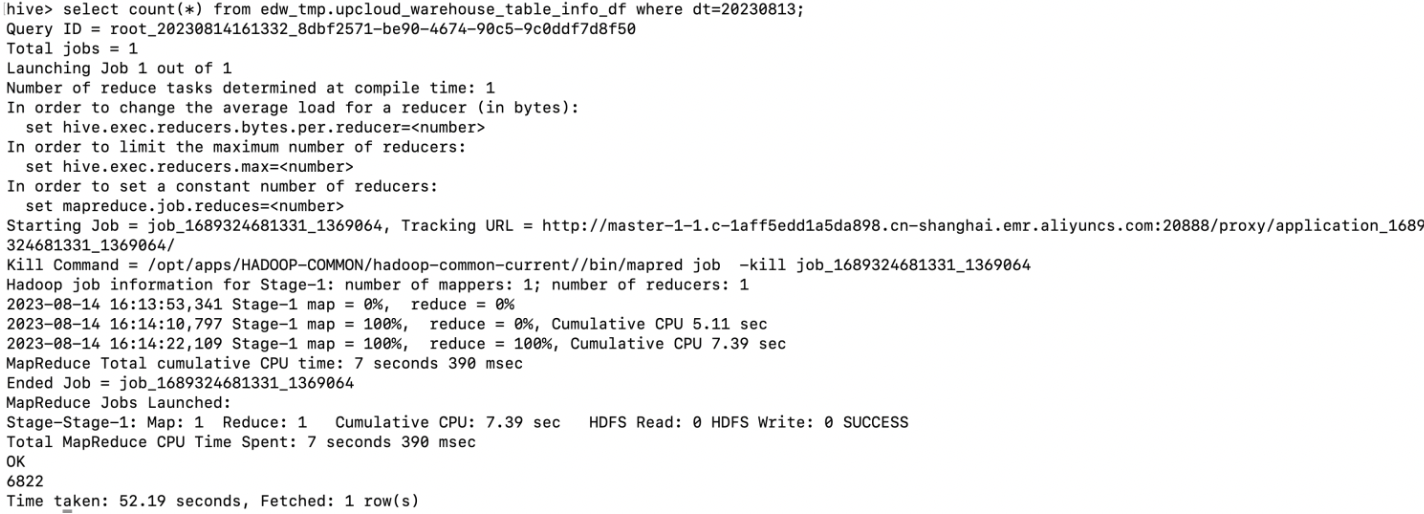
如果使用hive执行count语句,底层设置limit 限制条数的条件,可以正常显示出count数:
select count(*) from edw_tmp.upcloud_warehouse_table_info_df where dt=20230813 limit 10;

两者日志差别在于一个启动了底层mr程序,另一个没有启动。
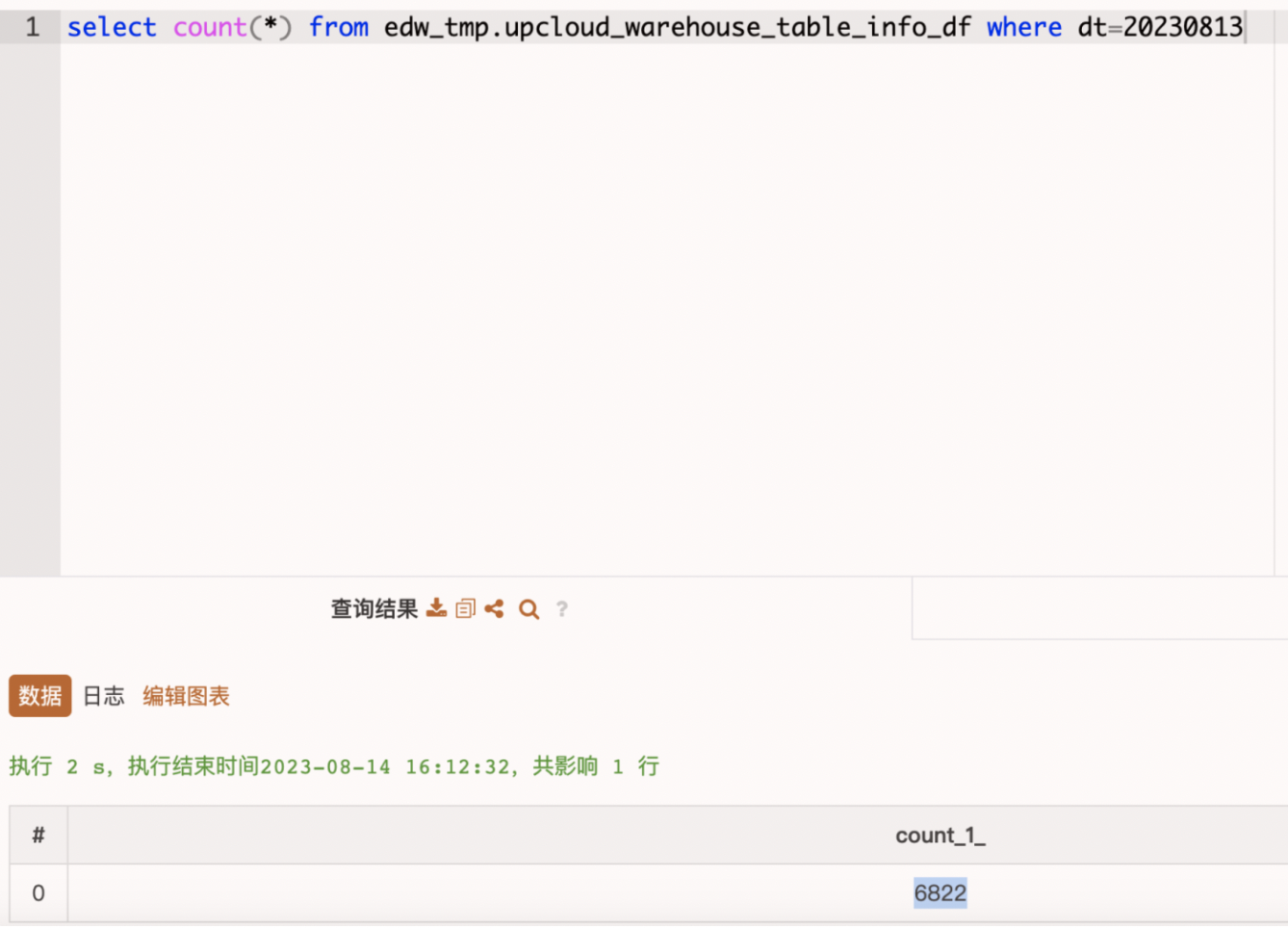
正常客户是使用的spark进行的建表和查询
spark执行
spark 客户端thriftserver创建表和hive创建表,涉及到的元数据更新不一致,并且集群底层对count查询进行了优化,默认情况下,Hive会尝试使用表的统计信息(如表的行数、列统计等)来优化查询的执行计划,但是,在某些情况下,统计信息可能不准确或过时,这可能导致Hive做出不恰当的优化决策,影响查询性能和结果。
【解决方法】
方法1:设置如下参数,先禁用查询优化,走底层数据查询。
set hive.compute.query.using.stats=false;
方法2:
hive使用analyze收集元数据信息后再进行查询。
ANALYZE TABLE edw_tmp.upcloud_warehouse_table_info_df COMPUTE STATISTICS;