Hive合并小文件:hive归档(archive)
一、概述
在HDFS中数据和元数据分别由DataNode和NameNode负责,这些元数据每个对象一般占用大约150个字节。大量的小文件相对于大文件会占用大量的NameNode内存。对NameNode内存管理产生巨大挑战。
使用 Hadoop 归档是减少分区中文件数量的一种方法。Hive 内置支持将现有分区中的文件转换为 Hadoop 档案 (HAR),这样由 100 多个文件组成的分区现在只占用 ~3 个文件(取决于设置)。不过,由于从 HAR 中读取文件会产生额外开销,因此查询速度可能会变慢。请注意,归档不会压缩文件--HAR 类似于 Unix 的 tar 命令。
注意:
存档的分区不能用 INSERT OVERWRITE 覆盖。必须先取消存档分区。
如果两个进程同时尝试归档同一个分区,可能会发生问题。
当存档一个分区时,会使用该分区原始位置的文件(如/warehouse/table/ds=1)创建一个HAR。分区的父目录被指定为与原始位置相同,生成的存档名为 "data.har"。将存档移至原始目录下(如 /warehouse/table/ds=1/data.har),并更改分区的位置以指向存档
二、测试过程
#创建测试表
create table smalltable(id bigint, t bigint, uid string, keyword string,
url_rank int, click_num int, click_url string)
PARTITIONED BY (dt STRING)
row format delimited fields terminated by '\t'
STORED AS ORC
TBLPROPERTIES ("orc.compress"="ZLIB") ;
#向测试表中多次插入数据
insert into table smalltable PARTITION (dt=20231220) select id,t,uid,keyword,url_rank,click_num,click_url from smalltable_tmp where dt=xxxx;
#归档
set hive.archive.enabled = true;
alter table smalltable ARCHIVE PARTITION (dt = 20231220);
#解档
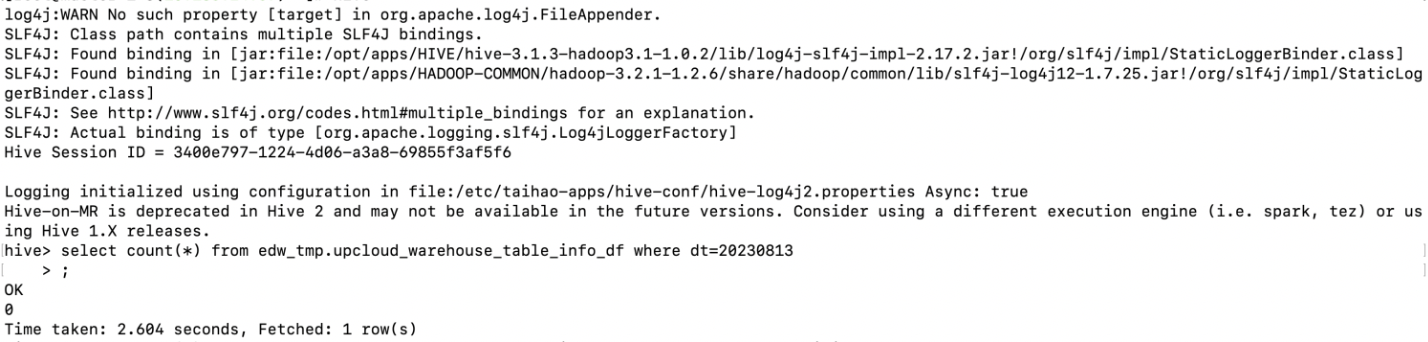
alter table smalltable UNARCHIVE PARTITION (dt = 20231220);归档操作前:


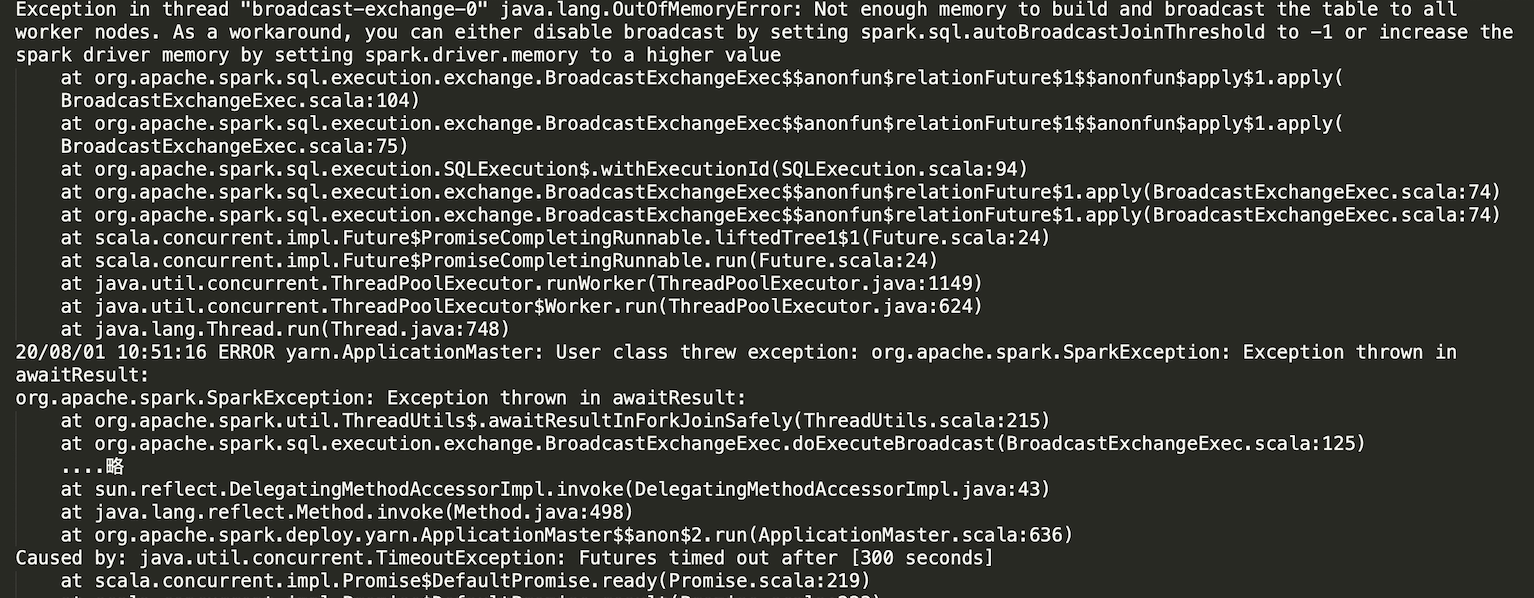
归档操作:



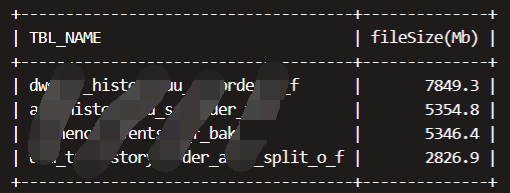
解档操作: