TEZ常见调优参数
一、设置引擎为Tez参数:
参数 | 默认值 | 推荐值 | 参数说明 | 解释 |
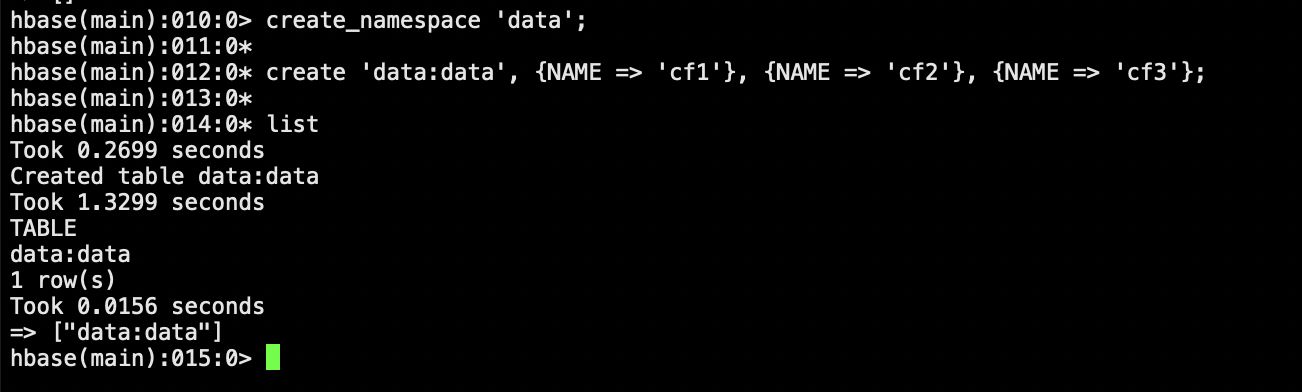
hive.execution.engine | mr | 请根据具体的业务场景进行选择 | 执行引擎选择 | 使用tez引擎时,此值设置为tez |
hive.tez.log.level | INFO | INFO | 设置Tez Task的日志级别 | 默认是INFO日志,如果为了定位问题可设置DEBUG级别,日志级别可能会对集群的性能产生影响,需要权衡日志信息的详细程度和集群的性能 |
二、内存相关调优:
参数 | 默认值 | 推荐值 | 参数说明 | 解释 |
tez.am.resource.memory.mb | 1024m | 8192m (小于或者等于yarn.scheduler.maximum-allocation-mb的值) | Application Master分配的container内存大小,单位为M,在运行大型或复杂度较高的 Tez 应用程序时,可能需要增加 tez.am.resource.memory.mb 的值,以便为 AM 进程提供更多的内存资源,避免出现内存不足的问题 | AM的内存 |
hive.tez.container.size | -1, | 8192 | Tez AppMaster向RM申请的container大小,单位M | Tez会生成一个与mapper大小相等的容器 |
tez.container.max.java.heap.fraction | 0.7 | 0.8 | 如果hive.tez.java.opts参数中没有设置Xmx/Xms的值,值的大小为0.8*hive.tez.container.size | 建议使用该值来调整opts |
tez.runtime.io.sort.mb | 100 | hive.tez.container.size的40% | 排序输出时的排序缓冲区大小,单位M | 可以将tez.runtime.io.sort.mb设置为hive.tez.container.size的40%,但该值不能超过2GB |
hive.auto.convert.join.noconditionaltask.size | 10000000 | 20000000,建议进行性能测试以确定最优的设置值 | 如果hive.auto.convert.join.noconditionaltask已关闭,则此参数不会生效。但是,如果它打开,并且n路连接的表/分区的n-1的大小总和小于此大小,连接直接转换为mapjoin(没有条件任务)。默认值为10MB | 该值能将多个Join的表的n-1个表合成一个大表,然后将该表转为mapjoin可以将该值设置为hive.tez.container.size的1/3 |
三、task调优:
参数 | 默认值 | 推荐值 | 参数说明 | 解释 |
tez.grouping.min-size | 50M | 建议进行性能测试以确定最优的设置值 | 分组拆分大小的下限,减小参数可以改善延迟,增大参数可以提高吞吐量 | 这个参数确定Map的数量 |
tez.grouping.max-size | 1G | 建议进行性能测试以确定最优的设置值 | 分组拆分大小的上限,减小参数可以改善延迟,增大参数可以提高吞吐量 | 这个参数确定Map的最大数量 |
tez.grouping.split-count | 100 | 需要根据具体的业务场景和集群资源情况进行选择 | 指定分组的数据量,指定之后忽略前两个参数 | 这个参数决定了在尝试进行数据分组时,一个任务可以被拆分多少个任务。如果数据量非常大,而集群资源又充足,可以尝试增大这个参数值 |
hive.tez.auto.reducer.parallelism | false | true | 打开Tez的reducer parallelism特性。设置true后,tez会在运行时根据数据大小动态调整reduce数量 | 最好使用TEZ提供的动态调整reduce数量功能。不要使用mapred.reduce.tasks参数去直接决定reduce的个数。只有打开该参数才能使用下面的hive.tez.min.partition.factor, |
hive.exec.reducers.max | 1009 | 1009,需要根据具体的业务场景和集群资源情况进行选择 | 任务中允许的最大reduce数量 | 任务中允许的最大reduce数量 |
hive.exec.reducer.bytes.per.reducer | 256M | 256M (如果数据量较大,集群资源充足,可以将其设置为较大的值以充分利用集群资源并提高数据处理速度) | 每个reduce处理的数据量 | 每个reduce处理的数据量 |
hive.tez.min.partition.factor | 0.25 | 需要根据具体的业务场景和集群资源情况进行选择 | 如果将其更改为较小的值,可以增加并行度;如果将其更改为较大的值,可以降低并行度 | 将其改为较小值以增加并行度通常可以提高查询性能,特别是在处理大规模数据时。但是,如果集群资源有限,或者任务之间的通信开销较大,也可以将其设置为较大的值以降低并行度。需要根据具体的业务场景和集群资源情况进行选择 |
hive.tez.max.partition.factor | 2.0 | 需要根据具体的业务场景和集群资源情况进行选择 | 如果将其更改为较大的值,可以减少并行度;如果将其更改为较小的值,可以增加并行度 | 需要根据具体的业务场景和集群资源情况进行选择。如果集群资源充足且处理的数据量较大,可以考虑将其设置为较大的值以减少并行度,从而降低集群负载并提高任务完成效率。但是,如果集群资源有限或者处理的数据量较小,可以将其设置为较小的值以增加并行度,从而更好地利用集群资源并提高数据处理速度 |
tez.shuffle-vertex-manager.min-src-fraction | 0.25 | 需要根据实际的业务场景和集群环境进行选择 | 影响reduce阶段的启动时间,增加该值则reduce stage启动晚一些。减少该值则reduce stage启动早一些 | 想让所有map都执行完才开始执行reduce,可以将这两个值都设置为1 |
tez.shuffle-vertex-manager.max-src-fraction | 2 | 需要根据实际的业务场景和集群环境进行选择 | 影响reduce阶段的启动时间,增加该值则reduce stage启动晚一些。减少该值则reduce stage启动早一些 | 想让所有map都执行完才开始执行reduce,可以将这两个值都设置为1 |
tez.shuffle-vertex-manager.desired-task-input-size | 100 MB | 需要根据具体的业务场景和集群资源情况进行选择 | 它用于控制shuffle阶段希望任务输入的大小。这个参数以字节为单位,通过设置这个参数,Tez 能够更好地管理 shuffle 阶段的任务调度, | 确定每个reduce任务所需的输入大小 |
tez.runtime.unordered.output.buffer.size-mb | 100 | 10%* hive.tez.container.size | 如果不直接写入磁盘,使用的缓冲区大小 | 如果处理的数据量较大,或者需要处理的数据较为复杂,可以考虑将其设置为较大的值以避免内存溢出等问题。但是,如果集群资源有限,或者处理的数据量较小,可以将其设置为较小的值以节省资源 |