Flinksql Kafka 接收流数据并打印到控制台
本文目的
使用Flink SQL创建一个流处理作业,将来自Kafka主题"dahua_picrecord"的数据写入到另一个表”print_table”控制台中。
使用sql-client前 需要启动yarn-session哦
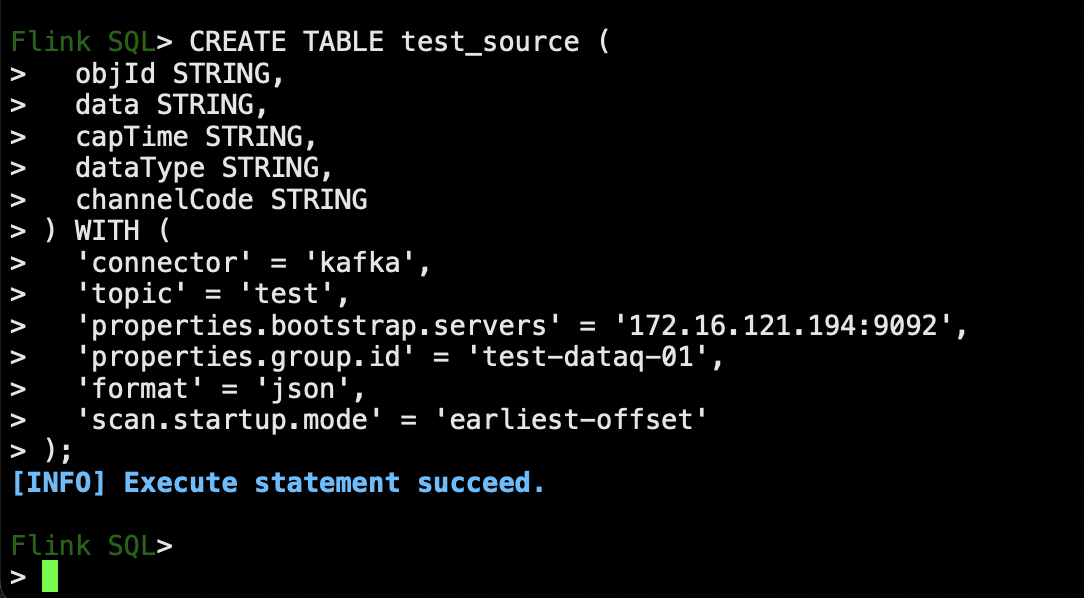
首先需要在CREATE TABLE
CREATE TABLE test_source (
objId STRING,
data STRING,
capTime STRING,
dataType STRING,
channelCode STRING
) WITH (
'connector' = 'kafka',
'topic' = 'test',
'properties.bootstrap.servers' = '172.16.121.194:9092',
'properties.group.id' = 'test-dataq-01',
'format' = 'json',
'scan.startup.mode' = 'earliest-offset'
);
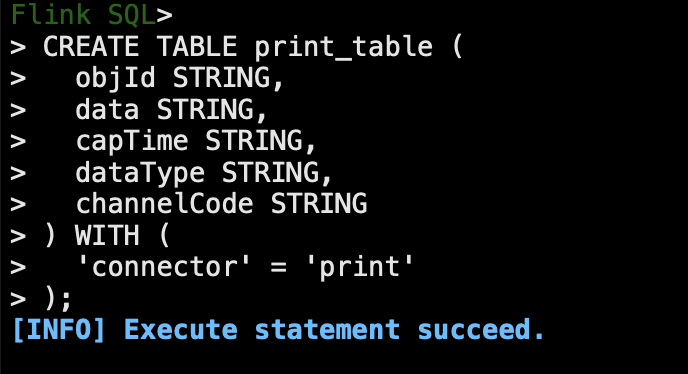
创建”print_table"
CREATE TABLE print_table (
objId STRING,
data STRING,
capTime STRING,
dataType STRING,
channelCode STRING
) WITH (
'connector' = 'print'
);
将数据从test_source 插入到 print_table 中
INSERT INTO print_table
SELECT objId, data, capTime, dataType, channelCode
FROM test_source;
接下来我们去查看yarn任务
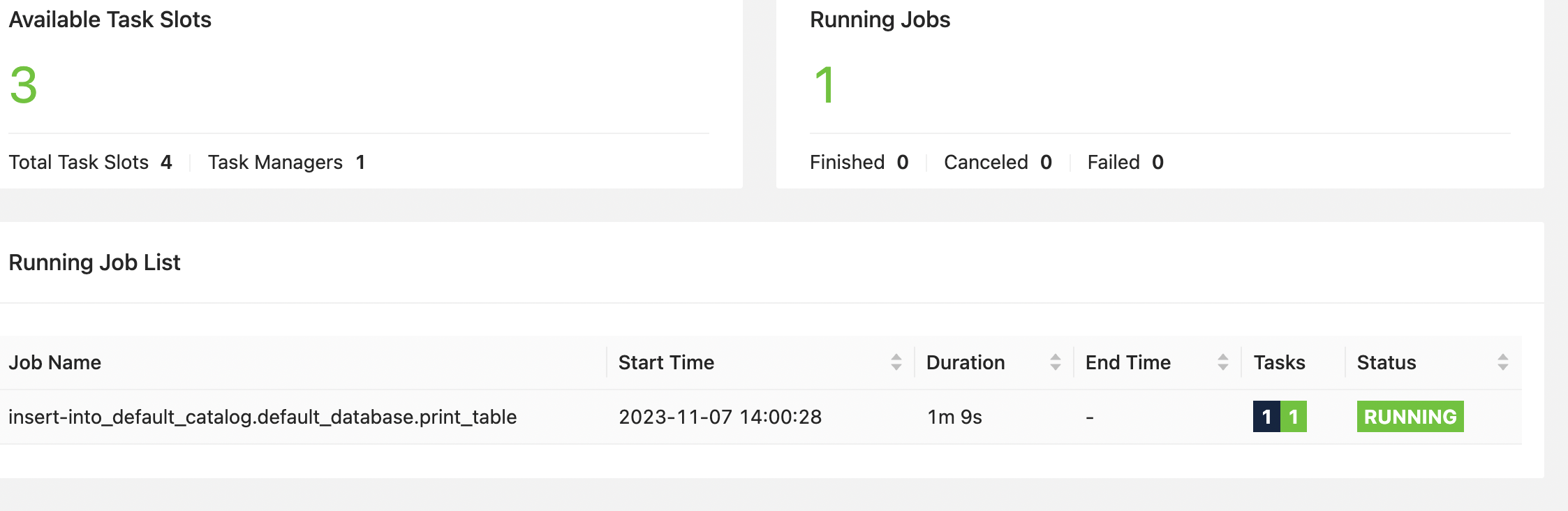
点进去看看
开始向test写一些json数据
/opt/kafka/bin/kafka-console-producer.sh --bootstrap-server 172.16.121.194:9092 --topic test
{"objId":"12345","data":"example data 1","capTime":"2023-11-07T08:00:00","dataType":"exampleType","channelCode":"ABCDEF"}
{"objId":"54321","data":"example data 2","capTime":"2023-11-07T08:15:00","dataType":"anotherType","channelCode":"GHIJKL"}
{"objId":"99999","data":"more example data","capTime":"2023-11-07T08:30:00","dataType":"additionalType","channelCode":"ZYXWVU"}
{"objId":"11111","data":"extra data","capTime":"2023-11-07T08:45:00","dataType":"extraType","channelCode":"QRSTUV"}
{"objId":"77777","data":"additional example data","capTime":"2023-11-07T09:00:00","dataType":"moreType","channelCode":"MNBVCX"}
{"objId":"88888","data":"more and more data","capTime":"2023-11-07T09:15:00","dataType":"typeX","channelCode":"POIUYT"}
{"objId":"22222","data":"different data","capTime":"2023-11-07T09:30:00","dataType":"typeY","channelCode":"LAKSDJ"}
{"objId":"66666","data":"sample data","capTime":"2023-11-07T09:45:00","dataType":"testType","channelCode":"QWERTY"}
{"objId":"44444","data":"new data","capTime":"2023-11-07T10:00:00","dataType":"newType","channelCode":"ZXCVBN"}
{"objId":"55555","data":"fresh data","capTime":"2023-11-07T10:15:00","dataType":"freshType","channelCode":"EDCRFV"}

查看flinkweb看数据过来了
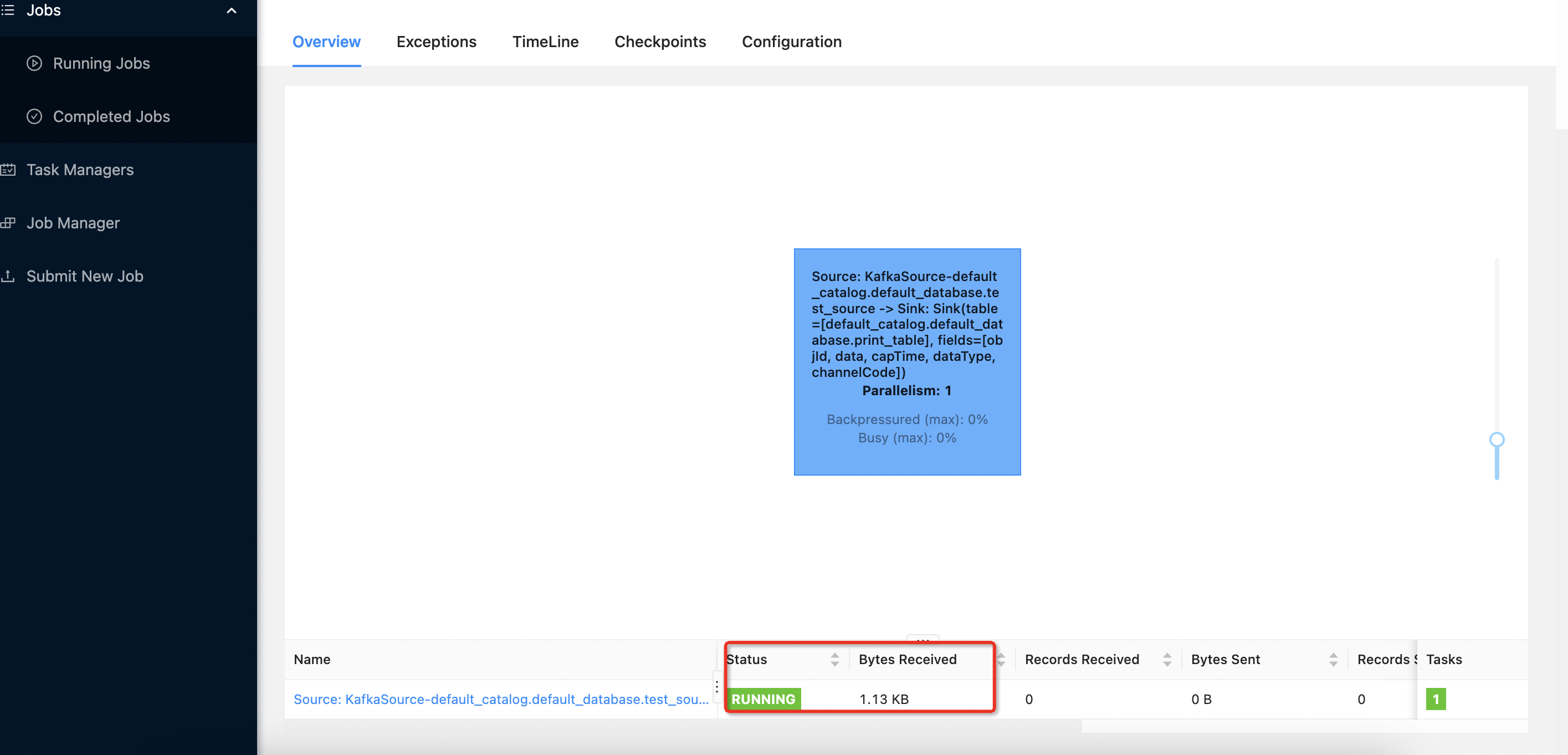
输出到了控制台
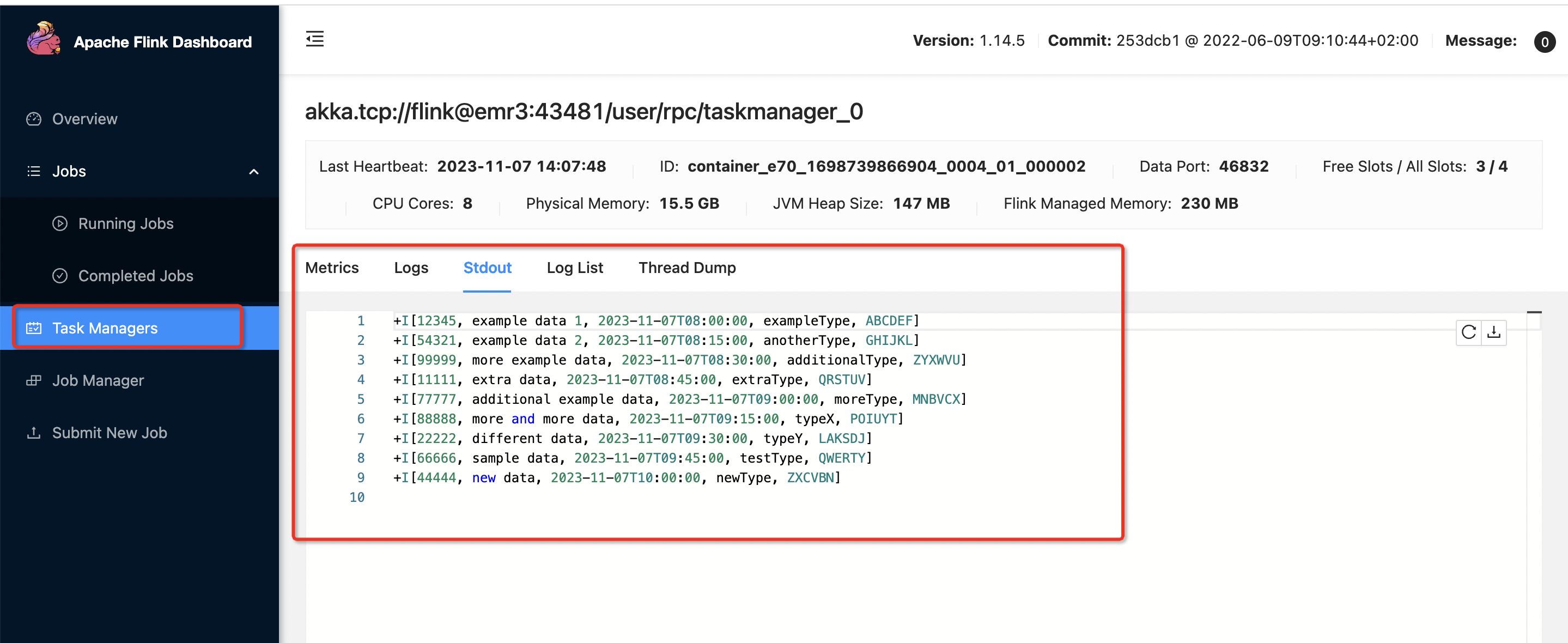
完成