系统RDSCPU打满问题分析报告
1. 问题概述
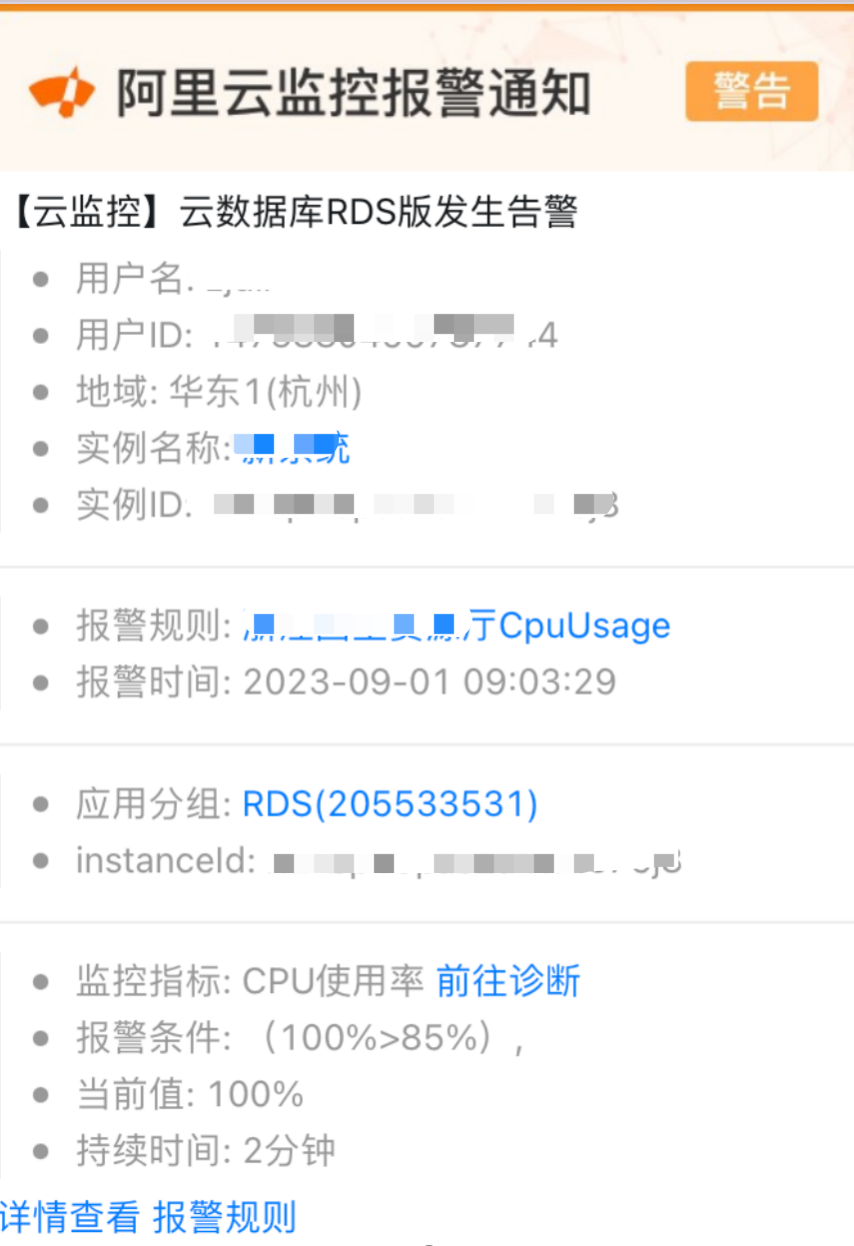
在2023年9月01日09点13分,玳数运维组侧接收到业务侧反馈系统响应缓慢,与此同时运维群内新系统RDS 发出CPU打满的告警,告警通知如下:
2. 问题分析
a. 数据库会话管理核查
玳数运维组侧登录阿里云控制台查看数据库会话管理,通过数据库自治服务的一键诊断功能,核实到活跃会话较多,现象为CPU使用率打满。
b. kill查询会话
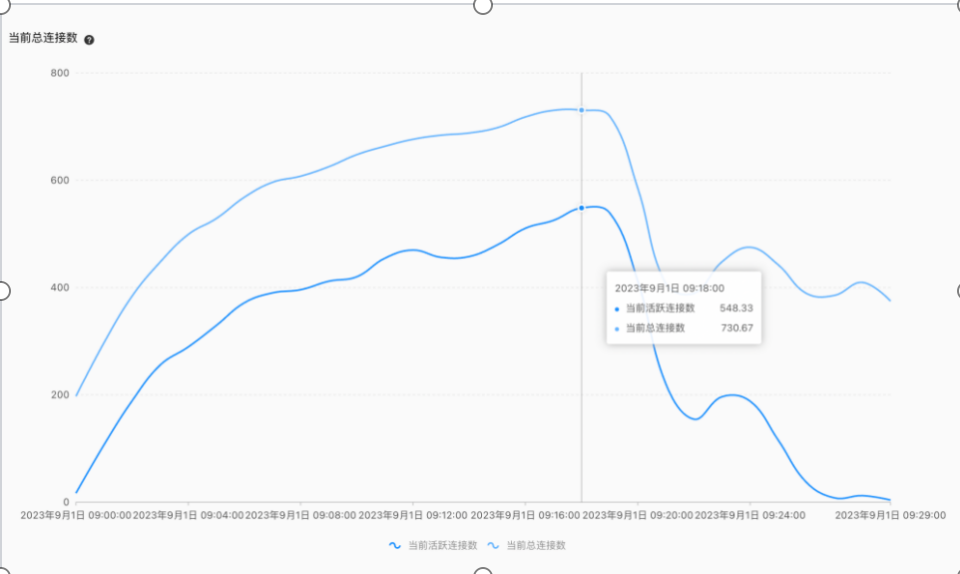
玳数运维组侧接收业务反馈,拍地业务比较紧急,可以迅速kill查询会话,保障数据库系统稳定运行。从9:00-9:30时间段内连接数迅速上升,波动较高至730左右
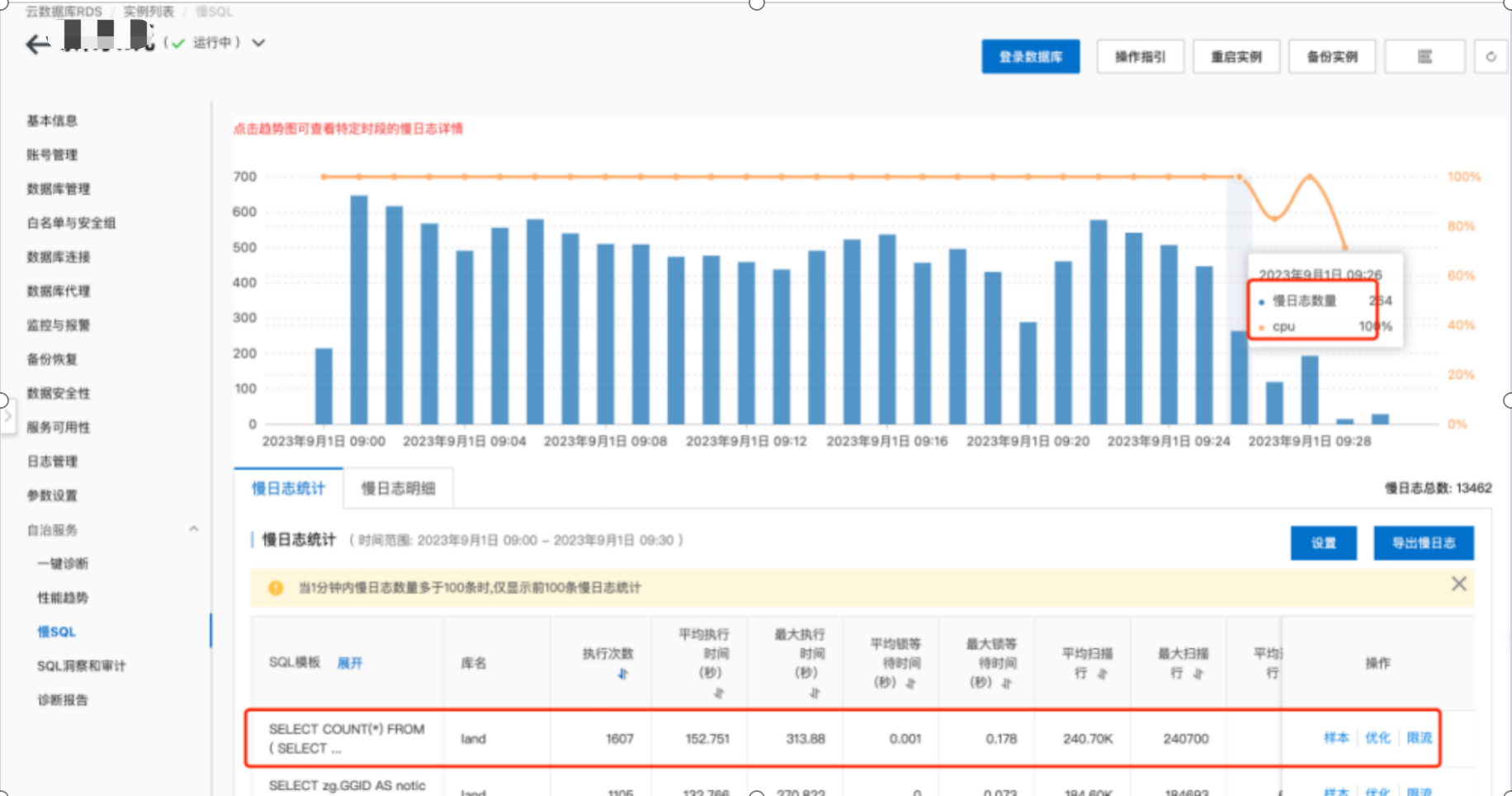
该慢SQL单次执行耗时在1.233秒左右,主要为执行次数影响。
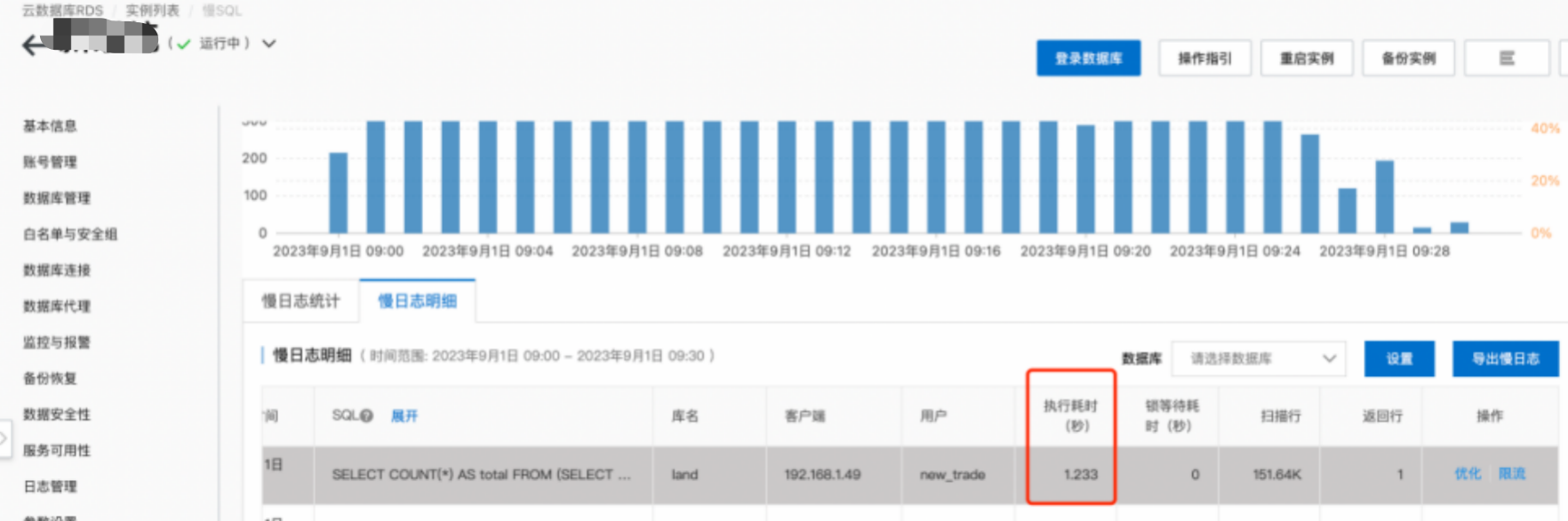
同业务侧拿到数据库账号信息,Kill查询会话后,CPU使用率逐步下降,拍地之前恢复至正常水位。

c. 核查会话增长原因
玳数运维组侧进一步核实程序侧是否有异常调用,导致数据库侧访问频次增加。程序访问通过WAF接入,再到后端SLB,由于WAF侧未开启访问日志,查看SLB访问日志,业务侧反馈对应SQL的业务访问接口:查询异常时间段内该接口的日志条数,30分钟内该接口个接口被调用了2970次
对比昨天同时间段内该接口的调用频次,昨天同时间段30min内日志是1,397条,如下图:
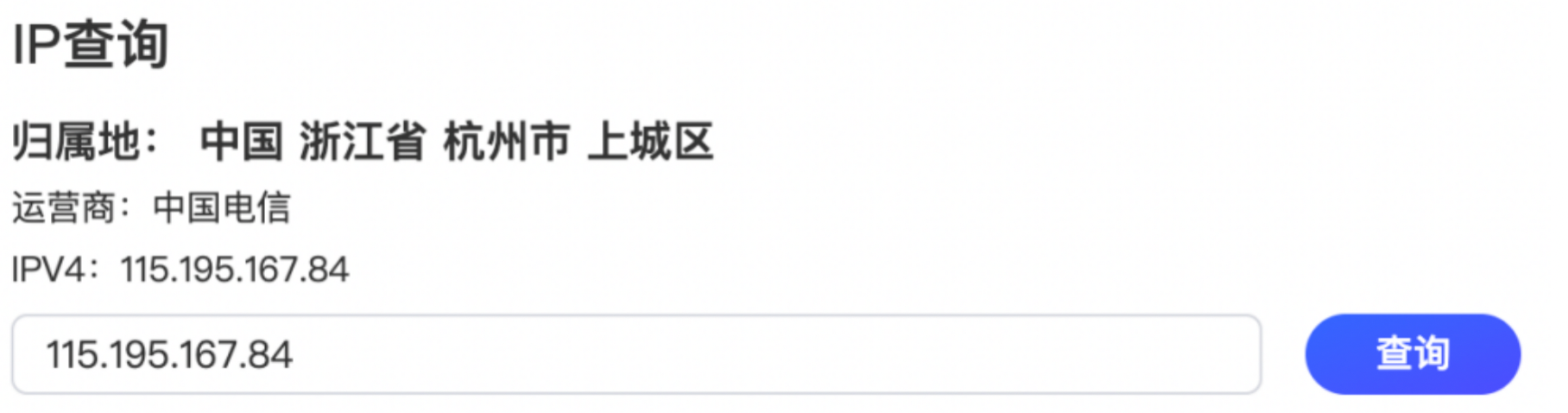
可以看到今天异常时间段内调用次数明显增多。导出该时间段内日志明细,查看访问来源IP,统计访问最多的来源ip,访问次数:102次,该来源地址在上城区,计算访问频次:一分钟内调用在三次左右。与此同时其他来源IP也在发起调用,导致总体并发量比较高,业务接口调用频繁。

3. 问题总结
结合RDS慢SQL日志、程序侧服务日志及业务侧反馈情况定位问题的根本原因在于单位时间内相应接口调用频次较高,数据库CPU打满。
a. 改进措施
为了防止类似问题再次发生,玳数科技运维组提出了以下改进措施:
1、程序侧做好对接口访问的相关限制,单位时间内限制对接口的访问频次,避免大并发下CPU资源使用完毕,导致数据库服务异常。
2、对数据库进行读写业务分离,实现读取能力的弹性扩展,分担数据库压力。
3、新系统RDS开启SQL洞察和审计,更好地获取SQL语句的具体信息、排查性能问题、识别高危风险来。
4、WAF侧开启日志功能,方便业务异常时刻能快速对采集到的日志数据进行查询与分析,定位问题原因。