Kafak顺序写入与数据读取详解
生产者(producer)是负责向Kafka提交数据的,Kafka会把收到的消息都写入到硬盘中,它绝对不会丢失数据。为了优化写入速度Kafak采用了两个技术,顺序写入和MMFile。
1. 顺序写入
因为硬盘是机械结构,每次读写都会寻址,写入,其中寻址是一个“机械动作”,它是最耗时的。所以硬盘最“讨厌”随机I/O,最喜欢顺序I/O。为了提高读写硬盘的速度,Kafka就是使用顺序I/O。每条消息都被append到该Partition中,属于顺序写磁盘,因此效率非常高。
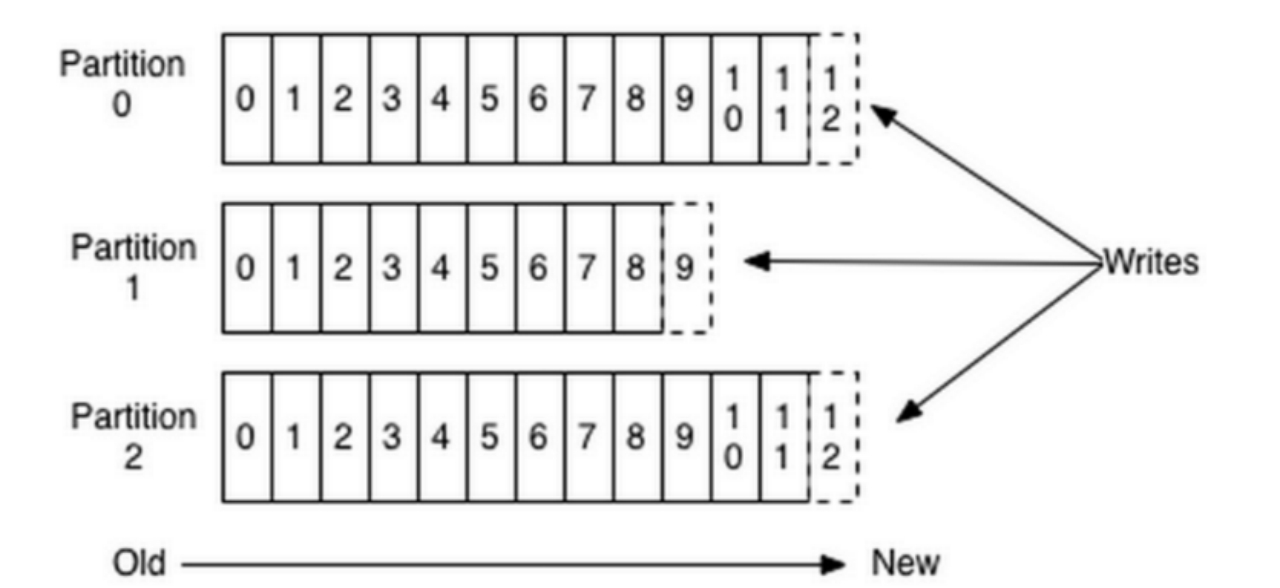
对于传统的message queue而言,一般会删除已经被消费的消息,而Kafka是不会删除数据的,它会把所有的数据都保留下来,每个消费者(Consumer)对每个Topic都有一个offset用来表示读取到了第几条数据。
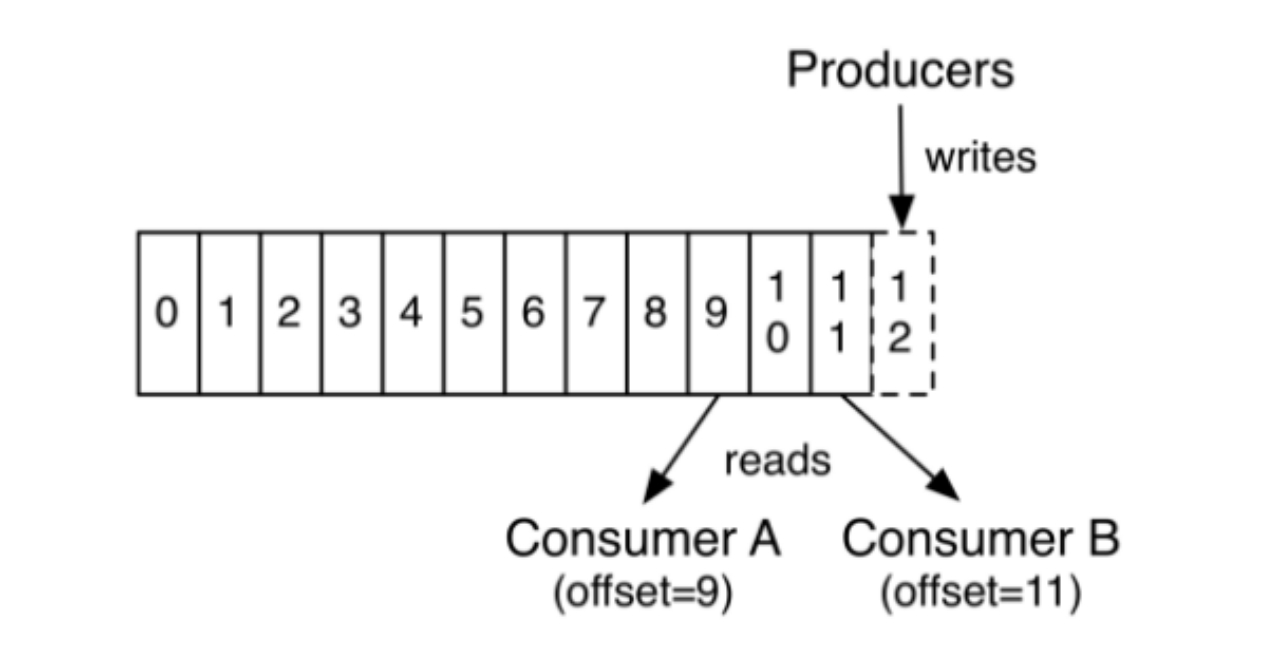
事实上,在每个消费者基础上保留的唯一元数据是消费者在日志中的偏移或位置。 这个偏移由消费者控制:通常消费者会在读取记录时线性地提高其偏移,但实际上,由于位置由消费者控制,它可以以任何顺序消耗记录。 例如,消费者可以重置为较旧的偏移量以重新处理来自过去的数据,或者跳过最近的记录,并从"现在"开始消费。
即便是顺序写入硬盘,硬盘的访问速度还是不可能追上内存。所以Kafka的数据并不是实时的写入硬盘,它充分利用了现代操作系统分页存储来利用内存提高I/O效率。
在Linux Kernal 2.2之后出现了一种叫做“零拷贝(zero-copy)”系统调用机制,就是跳过“用户缓冲区”的拷贝,建立一个磁盘空间和内存空间的直接映射,数据不再复制到“用户态缓冲区”系统上下文切换减少2次,可以提升一倍性能。

传统模式下我们从硬盘读取一个文件是这样的。
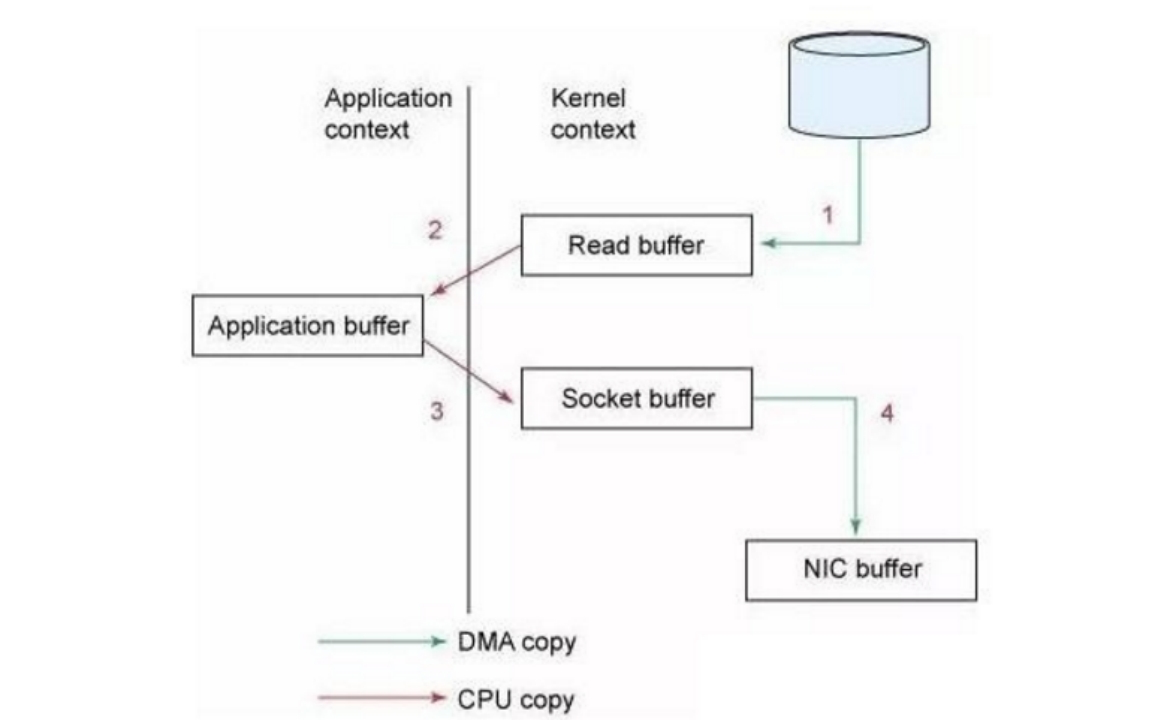
先复制到内核空间(read是系统调用,放到了DMA,所以用内核空间),然后复制到用户空间(1、2);从用户空间重新复制到内核空间(你用的socket是系统调用,所以它也有自己的内核空间),最后发送给网卡(3、4)。