Kafka副本策略
Kafka的高可靠性的保障来源于其健壮的副本(replication)策略。
1. 数据同步
kafka在0.8版本前没有提供Partition的Replication机制,一旦Broker宕机,其上的所有Partition就都无法提供服务,而Partition又没有备份数据,数据的可用性就大大降低了。所以0.8后提供了Replication机制来保证Broker的failover。
引入Replication之后,同一个Partition可能会有多个Replica,而这时需要在这些Replication之间选出一个Leader,Producer和Consumer只与这个Leader交互,其它Replica作为Follower从Leader中复制数据。
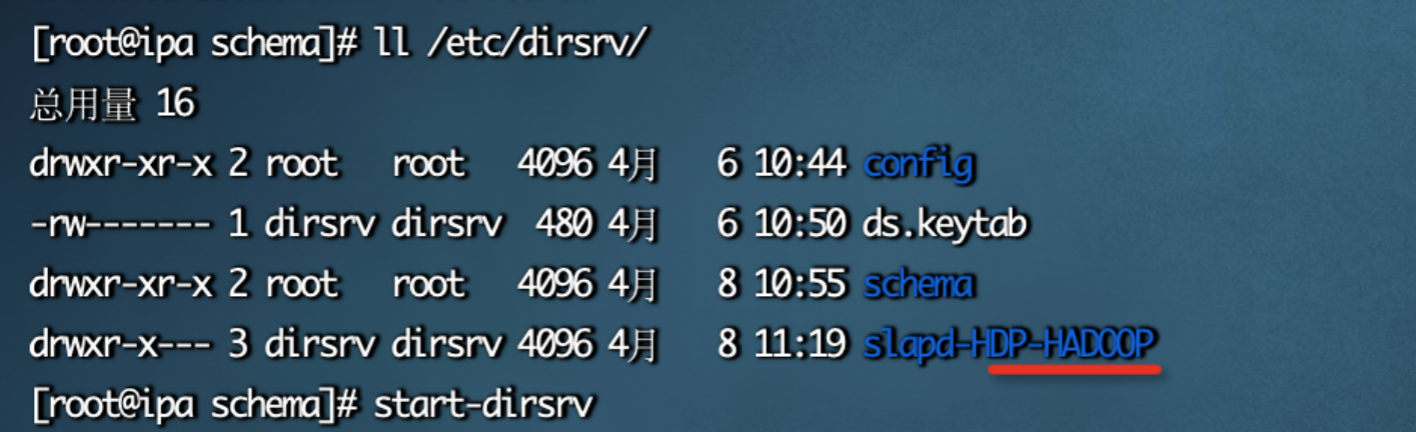
[root@tourbis kafka_2.10-0.8.2.1]# bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic test
Topic:test PartitionCount:3 ReplicationFactor:3 Configs:
Topic: test Partition: 0 Leader: 1 Replicas: 1,3,2 Isr: 1,3,2
Topic: test Partition: 1 Leader: 2 Replicas: 2,1,3 Isr: 2,1,3
Topic: test Partition: 2 Leader: 3 Replicas: 3,2,1 Isr: 3,2,1
1个Topic,3个分区,每个分区有3个副本。
2. 副本放置策略
为了更好的做负载均衡,Kafka尽量将所有的Partition均匀分配到整个集群上。Kafka分配Replica的算法如下:
将所有存活的N个Brokers和待分配的Partition排序
将第i个Partition分配到第(i mod n)个Broker上,这个Partition的第一个Replica存在于这个分配的Broker上,并且会作为partition的优先副本
将第i个Partition的第j个Replica分配到第((i + j) mod n)个Broker上
假设集群一共有4个brokers,一个topic有4个partition,每个Partition有3个副本。下图是每个Broker上的副本分配情况。
3. 同步策略
Producer在发布消息到某个Partition时,先通过ZooKeeper找到该Partition的Leader,然后无论该Topic的Replication Factor为多少,Producer只将该消息发送到该Partition的Leader。Leader会将该消息写入其本地Log。每个Follower都从Leader pull数据。这种方式上,Follower存储的数据顺序与Leader保持一致。Follower在收到该消息并写入其Log后,向Leader发送ACK。一旦Leader收到了ISR中的所有Replica的ACK,该消息就被认为已经commit了,Leader将增加HW并且向Producer发送ACK。
为了提高性能,每个Follower在接收到数据后就立马向Leader发送ACK,而非等到数据写入Log中。因此,对于已经commit的消息,Kafka只能保证它被存于多个Replica的内存中,而不能保证它们被持久化到磁盘中,也就不能完全保证异常发生后该条消息一定能被Consumer消费。Consumer读消息也是从Leader读取,只有被commit过的消息才会暴露给Consumer。
对于Kafka而言,定义一个Broker是否“活着”包含两个条件:
一是它必须维护与ZooKeeper的session(这个通过ZooKeeper的Heartbeat机制来实现)。
二是Follower必须能够及时将Leader的消息复制过来,不能“落后太多”。
Leader会跟踪与其保持同步的Replica列表,该列表称为ISR(即in-sync Replica)。如果一个Follower宕机,或者落后太多,Leader将把它从ISR中移除。这里所描述的“落后太多”指Follower复制的消息落后于Leader后的条数超过预定值或者Follower超过一定时间未向Leader发送fetch请求。
Kafka只解决fail/recover,一条消息只有被ISR里的所有Follower都从Leader复制过去才会被认为已提交。这样就避免了部分数据被写进了Leader,还没来得及被任何Follower复制就宕机了,而造成数据丢失(Consumer无法消费这些数据)。而对于Producer而言,它可以选择是否等待消息commit。这种机制确保了只要ISR有一个或以上的Follower,一条被commit的消息就不会丢失。
4. leader选举
Leader选举本质上是一个分布式锁,有两种方式实现基于ZooKeeper的分布式锁:
节点名称唯一性:多个客户端创建一个节点,只有成功创建节点的客户端才能获得锁
临时顺序节点:所有客户端在某个目录下创建自己的临时顺序节点,只有序号最小的才获得锁
Majority Vote的选举策略和ZooKeeper中的Zab选举是类似的,实际上ZooKeeper内部本身就实现了少数服从多数的选举策略。kafka中对于Partition的leader副本的选举采用了第一种方法:为Partition分配副本,指定一个ZNode临时节点,第一个成功创建节点的副本就是Leader节点,其他副本会在这个ZNode节点上注册Watcher监听器,一旦Leader宕机,对应的临时节点就会被自动删除,这时注册在该节点上的所有Follower都会收到监听器事件,它们都会尝试创建该节点,只有创建成功的那个follower才会成为Leader(ZooKeeper保证对于一个节点只有一个客户端能创建成功),其他follower继续重新注册监听事件。