trino组件对接alluxio(三)
本文是基于已经部署了trino和alluxio的基础上,进行的trino与alluxio的组件对接,alluxio已经开启了高可用模式。
安装部署
1、增加alluxio配置
在core-site.xml和hdfs-site.xml中增加alluxio相关配置信息。
core-site.xml:
<property> <name>alluxio.master.rpc.addresses</name> <value>hadoop001:19998,hadoop002:19998,hadoop003:19998</value> </property>
hdfs-site.xml:
<property> <name>alluxio.master.nameservices</name> <value>my-alluxio-cluster</value> </property> <property> <!-- 配置alluxio 的名称,多个用逗号分割 --> <name>alluxio.master.nameservices.my-alluxio-cluster</name> <value>master1,master2,master3</value> </property> <property> <name>alluxio.master.rpc.address.my-alluxio-cluster.master1</name> <value>hadoop001:19998</value> </property> <property> <name>alluxio.master.rpc.address.my-alluxio-cluster.master2</name> <value>hadoop002:19998</value> </property> <property> <name>alluxio.master.rpc.address.my-alluxio-cluster.master3</name> <value>hadoop003:19998</value> </property>
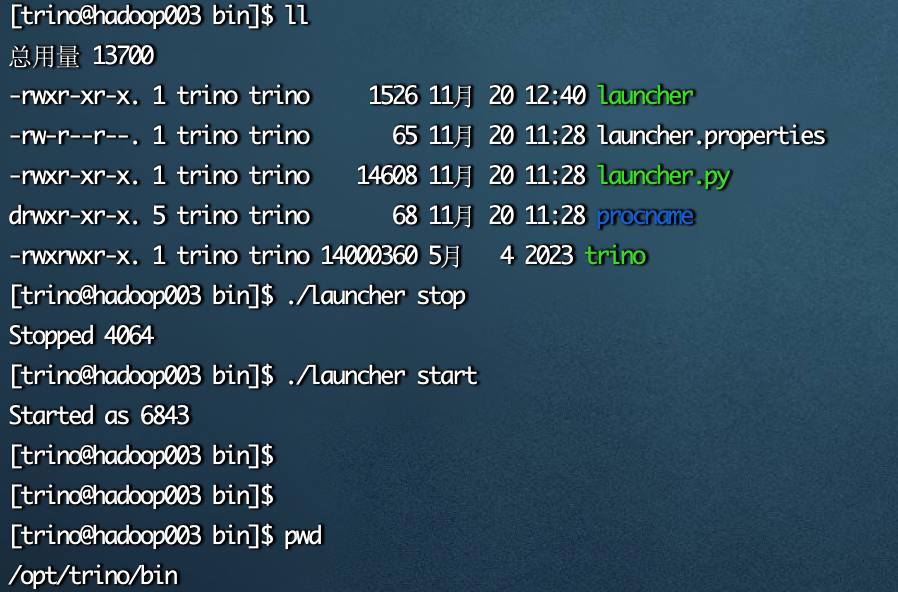
2、重启trino
/opt/trino/bin/launcher stop /opt/trino/bin/launcher start
冒烟测试
1、hive客户端创建alluxio表。
首先使用官方文档上的数据文件ml-100k.zip,将u.user数据上传到hdfs路径中


hive 客户端执行建表语句 use test; CREATE TABLE alluxio_user5 ( userid INT, age INT, gender CHAR(1), occupation STRING, zipcode STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY '|' STORED AS TEXTFILE LOCATION 'alluxio://ebj@my-alluxio-cluster/ml-100k';
2、trino客户端进行测试
/opt/trino/trino-cli --server https://172.16.121.0:8443 --keystore-path /opt/trino/etc/trino.jks --keystore-password admin@123 --catalog hive --user test --password --debug #进入test库 trino:test> show tables; Table ---------------------- alluxio_user2 alluxio_user3 alluxio_user4 alluxio_user5 alluxio_user6 alluxio_user7 alluxiotest fare_adjustment hive_student hive_student1 hudi_table merge_source student test test_hive_alluxio test_hive_hdfs test_spark_alluxio test_spark_alluxio33 test_spark_hdfs test_spark_hudi testcc u_user u_user2 (23 rows) Query 20231123_062033_00019_qew3a, FINISHED, 3 nodes https://172.16.121.0:8443/ui/query.html?20231123_062033_00019_qew3a Splits: 53 total, 53 done (100.00%) CPU Time: 0.0s total, 1.04K rows/s, 26.7KB/s, 32% active Per Node: 0.0 parallelism, 36 rows/s, 957B/s Parallelism: 0.1 Peak Memory: 2.92KB 0.21 [23 rows, 602B] [110 rows/s, 2.81KB/s] #可以看到test库下有alluxio_user5这张表,对该表进行测试 trino:test> select * from alluxio_user5 limit 10; userid | age | gender | occupation | zipcode --------+-----+--------+---------------+--------- 1 | 24 | M | technician | 85711 2 | 53 | F | other | 94043 3 | 23 | M | writer | 32067 4 | 24 | M | technician | 43537 5 | 33 | F | other | 15213 6 | 42 | M | executive | 98101 7 | 57 | M | administrator | 91344 8 | 36 | M | administrator | 05201 9 | 29 | M | student | 01002 10 | 53 | M | lawyer | 90703 (10 rows) Query 20231123_062330_00020_qew3a, FINISHED, 3 nodes https://172.16.121.0:8443/ui/query.html?20231123_062330_00020_qew3a Splits: 22 total, 18 done (81.82%) CPU Time: 0.1s total, 10.4K rows/s, 243KB/s, 18% active Per Node: 0.1 parallelism, 1.31K rows/s, 30.7KB/s Parallelism: 0.4 Peak Memory: 2.2KB 0.24 [943 rows, 22.1KB] [3.93K rows/s, 92.1KB/s] trino:test> select count(*) from alluxio_user5; _col0 ------- 947 (1 row) Query 20231123_062400_00021_qew3a, FINISHED, 3 nodes https://172.16.121.0:8443/ui/query.html?20231123_062400_00021_qew3a Splits: 22 total, 22 done (100.00%) CPU Time: 0.1s total, 11.4K rows/s, 267KB/s, 20% active Per Node: 0.1 parallelism, 779 rows/s, 18.3KB/s Parallelism: 0.2 Peak Memory: 1.3KB 0.41 [947 rows, 22.2KB] [2.34K rows/s, 54.8KB/s] trino:test> INSERT INTO alluxio_user5 values (110, 8888, 'F','李四','49087'); INSERT: 1 row Query 20231123_062831_00022_qew3a, FINISHED, 2 nodes https://172.16.121.0:8443/ui/query.html?20231123_062831_00022_qew3a Splits: 50 total, 50 done (100.00%) CPU Time: 0.2s total, 0 rows/s, 0B/s, 51% active Per Node: 0.1 parallelism, 0 rows/s, 0B/s Parallelism: 0.1 Peak Memory: 3.27KB 1.55 [0 rows, 0B] [0 rows/s, 0B/s] trino:test> select * from alluxio_user5 where userid = 110; userid | age | gender | occupation | zipcode --------+------+--------+------------+--------- 110 | 8888 | F | 李四 | 49087 110 | 8888 | F | zhangsan | 49087 110 | 19 | M | student | 77840 (3 rows) Query 20231123_063003_00023_qew3a, FINISHED, 3 nodes https://172.16.121.0:8443/ui/query.html?20231123_063003_00023_qew3a Splits: 6 total, 6 done (100.00%) CPU Time: 0.1s total, 8.03K rows/s, 188KB/s, 22% active Per Node: 0.1 parallelism, 972 rows/s, 22.8KB/s Parallelism: 0.4 Peak Memory: 548B 0.33 [948 rows, 22.2KB] [2.92K rows/s, 68.4KB/s] trino:test> select count(*) from alluxio_user5; _col0 ------- 948 (1 row) Query 20231123_063045_00024_qew3a, FINISHED, 3 nodes https://172.16.121.0:8443/ui/query.html?20231123_063045_00024_qew3a Splits: 23 total, 23 done (100.00%) CPU Time: 0.1s total, 15K rows/s, 353KB/s, 45% active Per Node: 0.1 parallelism, 1.33K rows/s, 31.2KB/s Parallelism: 0.3 Peak Memory: 1.41KB 0.24 [948 rows, 22.2KB] [4K rows/s, 93.7KB/s]