一、安装prometheus-webhook-dingtalk插件
wget https://github.com/timonwong/prometheus-webhook-dingtalk/releases/download/v0.3.0/prometheus-webhook-dingtalk-0.3.0.linux-amd64.tar.gz
tar -zxf prometheus-webhook-dingtalk-0.3.0.linux-amd64.tar.gz -C /opt/
mv /opt/prometheus-webhook-dingtalk-0.3.0.linux-amd64 /opt/prometheus-webhook-dingtalk
二、钉钉创建机器人自定义告警关键词并获取token
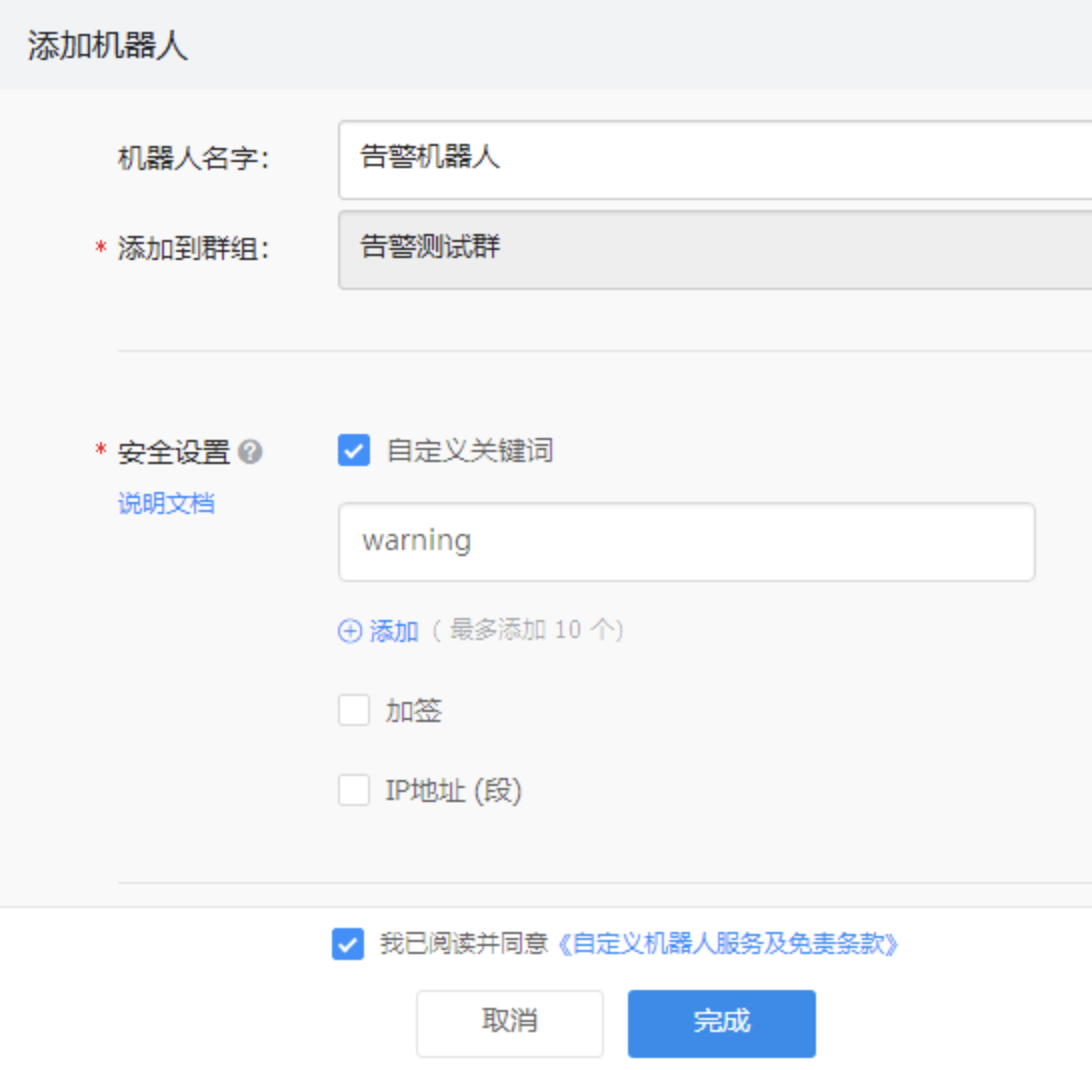
选择群组—>群设置–>添加智能群助手–>添加机器人
注意:选择过程中会有三种安全设置(这里我们只用第一种)
1.第一个自定义关键字是说你在以后发送的文字中必须要有这个关键字,否则发送不成功。
2.加签是一种特殊的加密方式,第一步,把timestamp+"\n"+密钥当做签名字符串,使用HmacSHA256算法计算签名,然后进行Base64 encode,最后再把签名参数再进行urlEncode,得到最终的签名(需要使用UTF-8字符集)。
3.IP地址就是说你在发送时会获取你的IP地址,如果不匹配就发送不成功。这个加密的方式可以自己选择,我们选择加签。如果你想使用IP的话,可以访问https://ip.cn/
三、启动钉钉插件dingtalk
vim /etc/systemd/system/prometheus-webhook-dingtalk.service
#添加如下内容
[Unit]
Description=prometheus-webhook-dingtalk
After=network-online.target
[Service]
Restart=on-failure
ExecStart=/opt/prometheus-webhook-dingtalk/prometheus-webhook-dingtalk --ding.profile=ops_dingding=自己钉钉机器人的Webhook地址
[Install]
WantedBy=multi-user.target
#命令行启动
systemctl daemon-reload
systemctl start prometheus-webhook-dingtalk
ss -tnl | grep 8060
#测试
curl -H "Content-Type: application/json" -d '{ "version": "4", "status": "firing", "description":"description_content"}' http://localhost:8060/dingtalk/ops_dingding/send四、配置Alertmanager
cat /opt/alertmanager/alertmanager.yml
global:
#每一分钟检查一次是否恢复
resolve_timeout: 1m
route:
#设置默认接收人
receiver: 'webhook'
#组告警等待时间。也就是告警产生后等待10s,如果有同组告警一起发出
group_wait: 10s
#两组告警的间隔时间
group_interval: 10s
#重复告警的间隔时间,减少相同微信告警的发送频率
repeat_interval: 1h
#采用哪个标签来作为分组依据
group_by: [alertname]
routes:
- receiver: webhook
group_wait: 10s
match:
team: node
receivers:
- name: 'webhook'
webhook_configs:
- url: http://localhost:8060/dingtalk/ops_dingding/send
#警报被解决之后是否通知
send_resolved: true
#命令行启动
cd /opt/alertmanager/
./alertmanager --config.file=alertmanager.yml &
netstat -anput | grep 9093
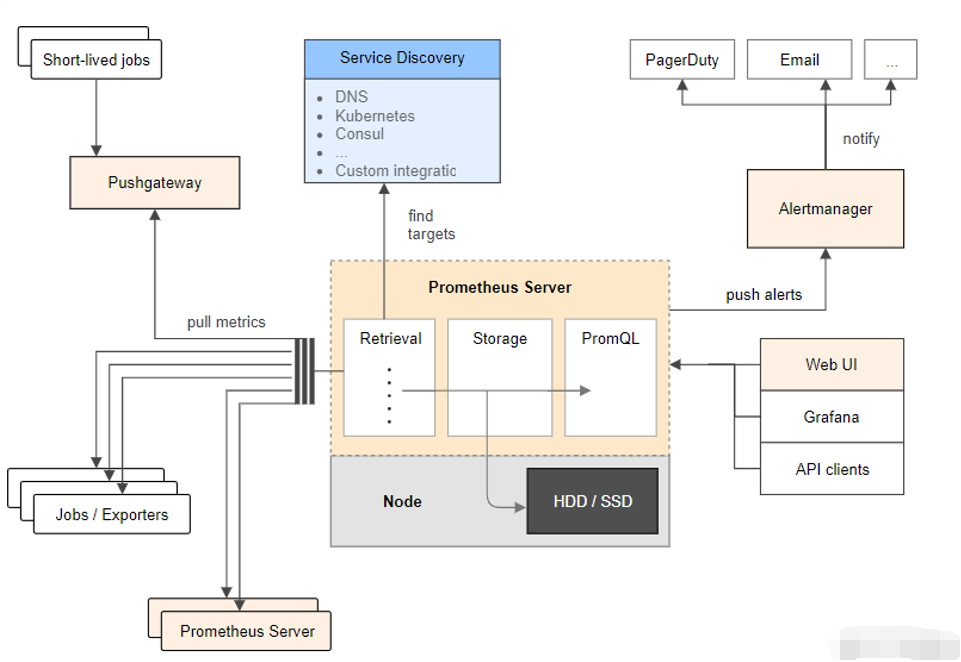
五、关联Prometheus并配置报警规则
cat /opt/prometheus/rules/node_down.yml
groups:
- name: Node_Down
rules:
- alert: Node实例宕机
expr: up == 0
for: 10s
labels:
user: prometheus
severity: Warning
annotations:
summary: "{{ $labels.instance }} 服务宕机"
description: "{{ $labels.instance }} of job {{ $labels.job }} has been Down."
修改Prometheus配置文件
cat /opt/prometheus/prometheus.yml
# 修改以下内容
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets: ["localhost:9093"]
rule_files:
- "/opt/prometheus/rules/node_down.yml" # 实例存活报警规则文件
#重启
systemctl restart prometheus