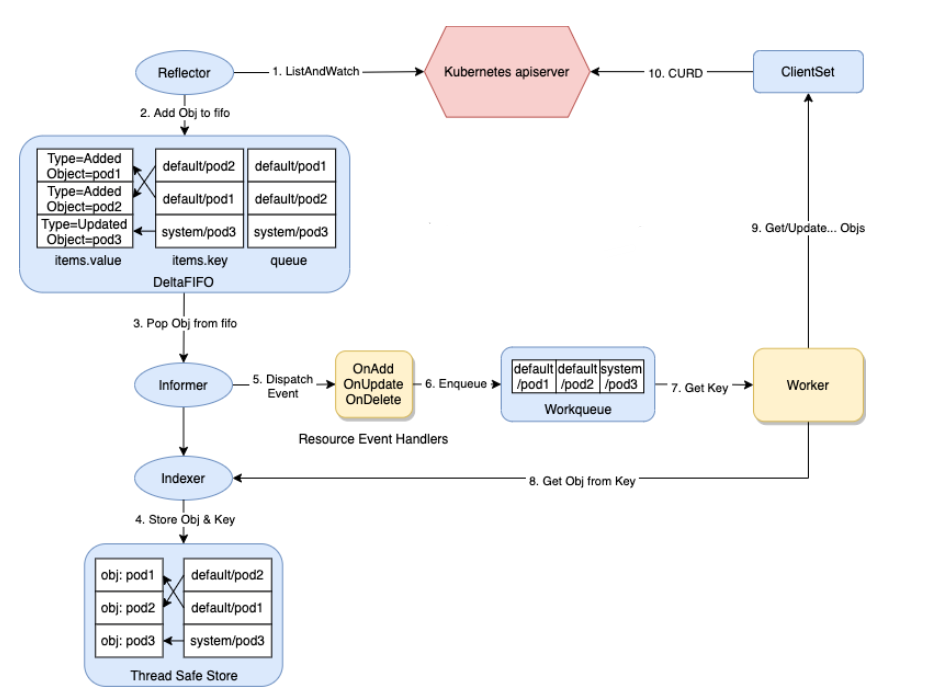
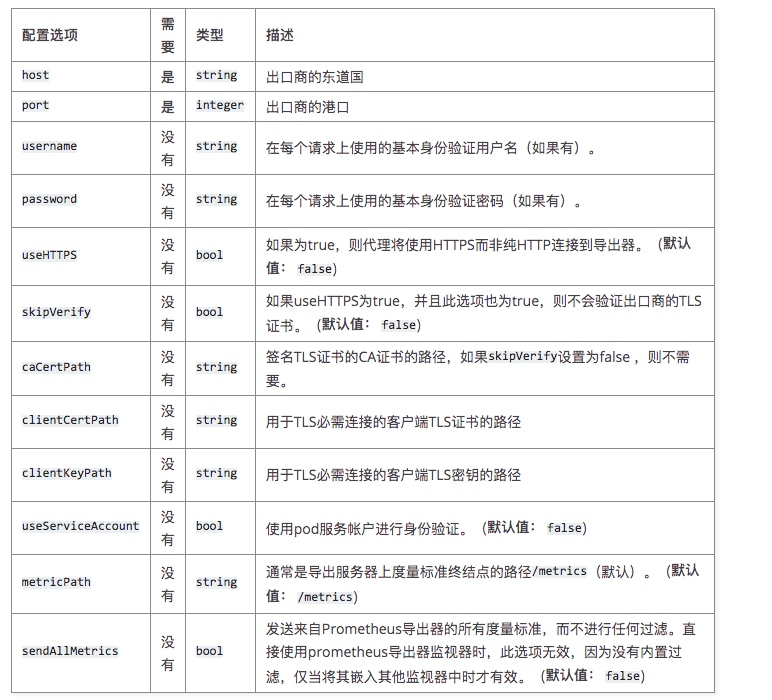
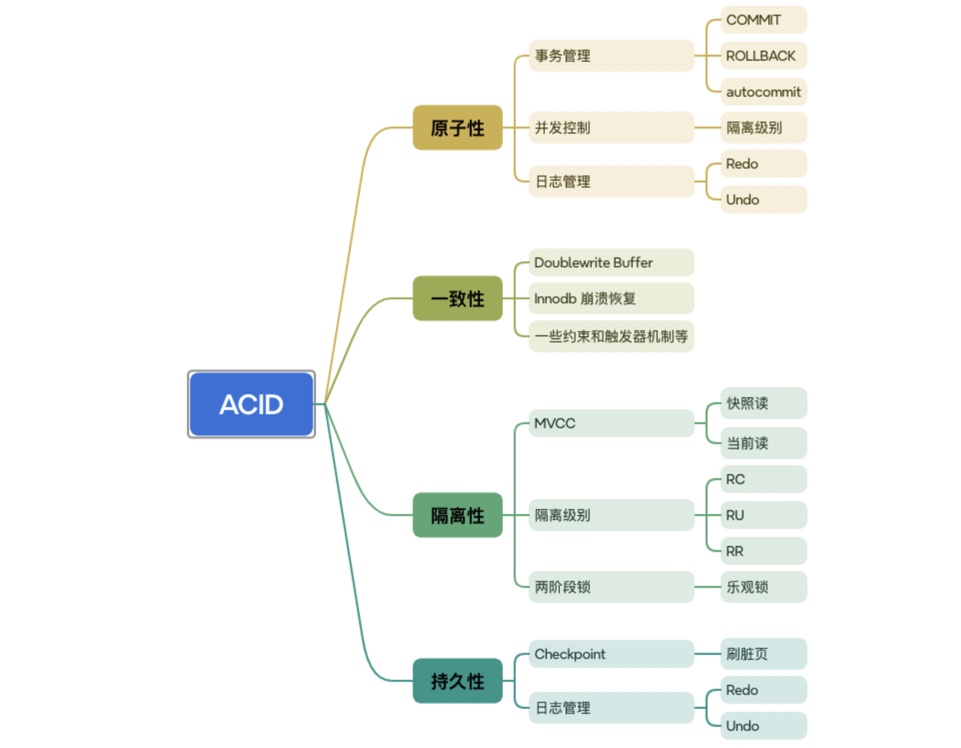
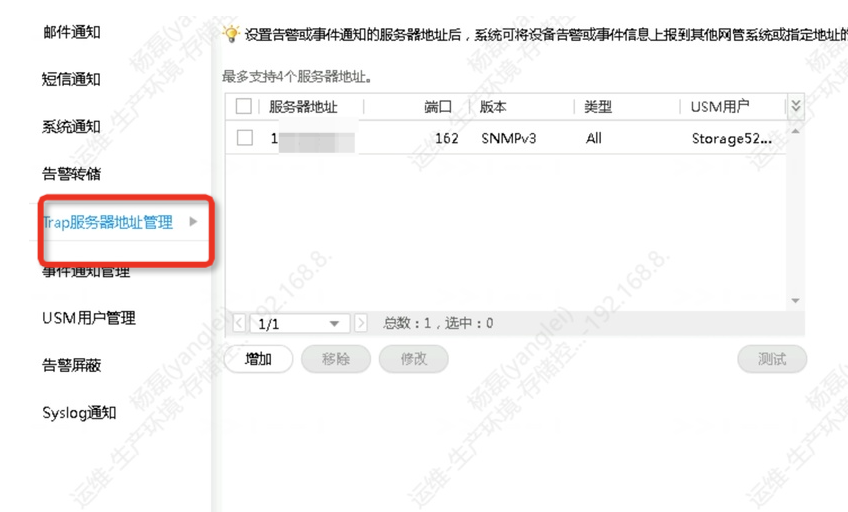
如何使用
1.把以上程序打包成AddDoublesUDF.jar,并上传到HDFS指定目录下(如“/user/hive_examples_jars/”)且创建函数的用户与使用函数的用户有该文件的可读权限。示例语句:
hdfs dfs -put ./hive_examples_jars /user/hive_examples_jars
hdfs dfs -chmod 777 /user/hive_examples_jars
2.需要使用一个具有admin权限的用户登录beeline客户端,执行如下命令:
kinit Hive业务用户
beeline
set role admin;
3.在Hive Server中定义该函数,以下语句用于创建永久函数:
CREATE FUNCTION addDoubles AS 'com.huawei.bigdata.hive.example.udf.AddDoublesUDF' using jar 'hdfs://hacluster/user/hive_examples_jars/AddDoublesUDF.jar';
其中addDoubles是该函数的别名,用于SELECT查询中使用。
以下语句用于创建临时函数:
CREATE TEMPORARY FUNCTION addDoubles AS 'com.huawei.bigdata.hive.example.udf.AddDoublesUDF' using jar 'hdfs://hacluster/user/hive_examples_jars/AddDoublesUDF.jar';
•addDoubles是该函数的别名,用于SELECT查询中使用。
•关键字TEMPORARY说明该函数只在当前这个Hive Server的会话过程中定义使用。
4.在Hive Server中使用该函数,执行SQL语句:
SELECT addDoubles(1,2,3);
若重新连接客户端再使用函数出现[Error 10011]的错误,可执行reload function;命令后再使用该函数。
5.在Hive Server中删除该函数,执行SQL语句:
DROP FUNCTION addDoubles;