Kubernetes原理分析--Kube-controller list&watch原理解析
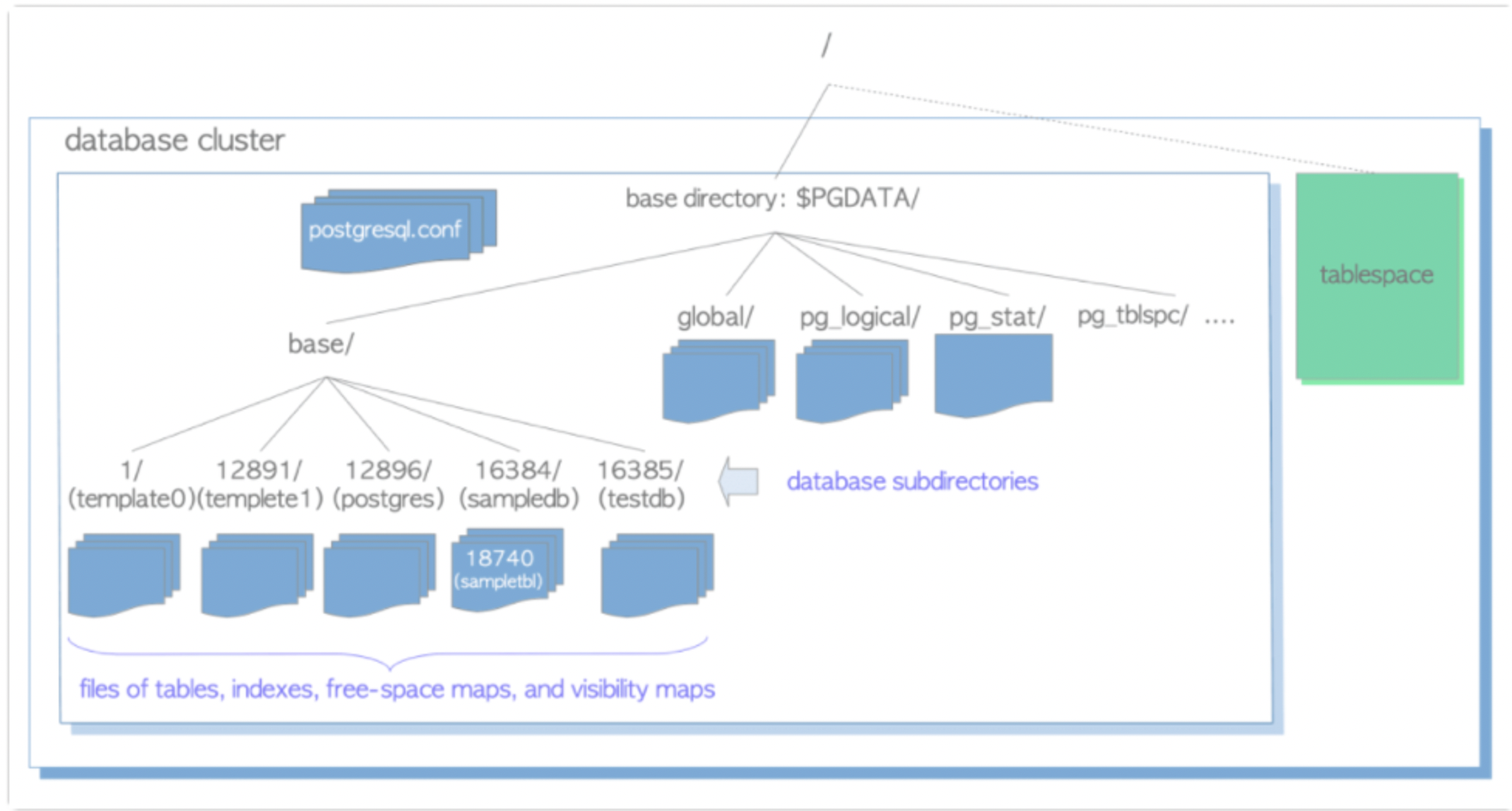
1.list&watch流程:

这里有三个 List-Watch,分别是 Controller Manager(运行在 Master),Scheduler(运行在Master),kubelet(运行在 Node)。他们在进程已启动就会监听(Watch)APIServer 发出来的事件。
用户通过 kubectl 或其他 API 客户端提交请求给 APIServer 来建立一个 Pod 对象副本。
APIServer 尝试着将 Pod 对象的相关元信息存入 etcd 中,待写入操作执行完成,APIServer即会返回确认信息至客户端;
当 etcd 接受创建 Pod 信息以后,会发送一个 Create 事件给 APIServer;
由于 Controller Manager 一直在监听APIServer 中的事件。此时APIServer 接受到了 Create 事件,又会发送给 Controller Manager,Controller Manager 在接到 Create 事件以后,调用其中的 Replication Controller 来保证Node 上面需要创建的副本数量。一旦副本数量少于 RC 中定义的数量,RC 会自动创建副本。总之它是保证副本数量的Controller(PS:扩容缩容的担当);
在 Controller Manager 创建 Pod 副本以后,APIServer 会在 etcd 中记录这个 Pod的详细信息。例如 Pod 的副本数,Container 的内容是什么;
同样的 etcd 会将创建 Pod 的信息通过事件发送给 APIServer;
由于 Scheduler 在监听(Watch)APIServer,并且它在系统中起到了“承上启下”的作用,“承上”是指它负责接收创建的Pod 事件,为其安排 Node;“启下”是指安置工作完成后,Node 上的 kubelet 进程会接管后继工作,负责 Pod生命周期中的“下半生”。 换句话说,Scheduler 的作用是将待调度的 Pod 按照调度算法和策略绑定到集群中 Node 上;
Scheduler 调度完毕以后会更新 Pod 的信息,此时的信息更加丰富了。除了知道 Pod 的副本数量,副本内容。还知道部署到哪个Node 上面了。并将上面的 Pod 信息更新至 API Server,由 APIServer 更新至 etcd 中,保存起来;
etcd 将更新成功的事件发送给 APIServer,APIServer 也开始反映此 Pod 对象的调度结果;
kubelet 是在 Node 上面运行的进程,它也通过 List-Watch的方式监听(Watch,通过https的6443端口)APIServer 发送的 Pod 更新的事件。kubelet会尝试在当前节点上调用 Docker 启动容器,并将 Pod 以及容器的结果状态回送至 APIServer。
2.list&watch架构:


1)、底层数据队列的维护和实现:
Reflector:reflector用来watch特定的k8s API资源并将变化同步到本地是cache中。Reflector只会放置指定的expectedType类型的资源到store中,除非expectedType为nil。如果resyncPeriod不为零,那么Reflector以resyncPeriod为周期定期执行list的操作,这样就可以使用Reflector来定期处理所有的对象,也可以逐步处理变化的对象。具体的实现是通过ListAndWatch的方法,watch可以是k8s内建的资源或者是自定义的资源。当reflector通过 watch API 接收到有关新资源实例存在的通知时,它使用相应的 list API 获取新创建的对象,并将其放入watchHandler 函数内的Delta Fifo队列中(充当生产者角色);
ListAndWatch第一次会从apiserver端列出所有的对象,并获取资源对象的版本号,然后watch资源对象的版本号来查看是否有被变更。首先会将资源版本号设置为0,list()可能会导致本地的缓存相对于etcd里面的内容存在延迟,Reflector会通过watch的方法将延迟的部分补充上,使得本地的缓存数据与etcd的数据保持一致。
DeltaFIFO:DeltaFIFO中存储着一个map和一个queue,即map[object key]Deltas以及object key的queue,Deltas为Delta的切片类型,Delta装有对象及对象的变化类型(Added/Updated/Deleted/Sync) ,Reflector负责DeltaFIFO的输入,Controller负责处理DeltaFIFO的输出;
Controller:Controller从DeltaFIFO的queue中pop一个object key出来,并获取其关联的 Deltas出来进行处理,遍历Deltas,根据对象的变化更新Indexer中的本地内存缓存,并通知Processor,相关对象有变化事件发生;
Processor:Processor根据对象的变化事件类型,调用相应的ResourceEventHandler来处理对象的变化;
ResourceEventHandler:用户根据自身处理逻辑需要,注册自定义的的ResourceEventHandler,当对象发生变化时,将触发调用对应类型的ResourceEventHandler来做处理;
Informer:informer从Delta Fifo队列中弹出对象。执行此操作的功能是processLoop。base controller的作用是保存对象以供以后检索,并调用我们的控制器将对象传递给它。informer封装了上面的Controller(充当消费者角色);
Indexer:索引器提供对象的索引功能。典型的索引用例是基于对象标签创建索引。 Indexer可以根据多个索引函数维护索引。Indexer使用线程安全的数据存储来存储对象及其键;
Informer 只会调用 Kubernetes List 和 Watch 两种类型的 API。 通过Lister()对象来List/Get对象时,Informer不会去请求Kubernetes API,而是直接查询本地缓存,减少对Kubernetes API的直接调用。客户端先到server端全量list一把,然后存到cache中,剩下的事情就是从server端不断watch新的变化并加入到队列中,这个队列的消费者那里除了将变化更新到indexer中之外,还会对这个变化做出相应的处理。
Informer 在初始化时,调用 Kubernetes List API 获得某种 resource 的全部 Object,缓存在内存中;
接下来,Informer 调用 Watch API 去 watch 这种 resource,去维护这份缓存;
最后,Informer 就不再调用 Kubernetes 的任何 API。
我们以 Pod 为例,详细说明一下 Informer 的关键逻辑:
Informer 在初始化时,Reflector 会先 List API 获得所有的 Pod;
Reflector 拿到全部 Pod 后,会将全部 Pod 放到 Store(即实现了Storage接口的indexer底层是threadSafeMap结构体) 中;
如果有人调用 Lister (informer为对应资源对象封装的client用于查询本地缓存资源)的 List/Get 方法获取 Pod, 那么 Lister 会直接从 Store 中拿数据;
Informer 初始化完成之后,Reflector 开始 Watch Pod,监听 Pod 相关 的所有事件。如果此时 pod_1 被删除,那么 Reflector 会监听到这个事件;
Reflector 将 pod_1 被删除 的这个事件发送到 DeltaFIFO;
DeltaFIFO 首先会将这个事件存储在自己的数据结构中(实际上是一个 queue),然后会直接操作 Store 中的数据,删除 Store 中的 pod_1;
DeltaFIFO 再 Pop 这个事件到 Controller 中;
Controller 收到这个事件,会触发 Processor 的回调函数;