kubernetes job和cronjob
Job 负责批处理任务,即仅执行一次的任务,它保证批处理任务的一个或多个 Pod 成功结束。
特殊说明:
1、spec.template 格式同 Pod
2、RestartPolicy 仅支持 Never 或 OnFailure
3、单个 Pod 时,默认 Pod 成功运行后 Job 即结束
4、spec.completions 标志 Job 结束需要成功运行的 Pod 个数,默认为 1
5、spec.parallelism 标志并行运行的 Pod 的个数,默认为 1
6、spec.activeDeadlineSeconds 标志失败 Pod 的重试最大时间,超过这个时间不会继续重试
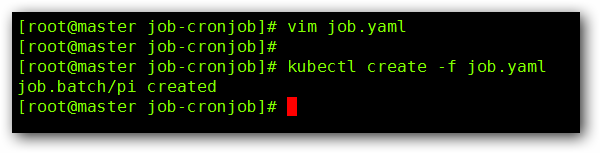
vim job.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: job
spec:
template:
metadata:
name: job
spec:
containers:
- name: job
image: docker.io/perl
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: Never
然后我们来看一下 Pod 的信息:
我们在来看下日志信息:
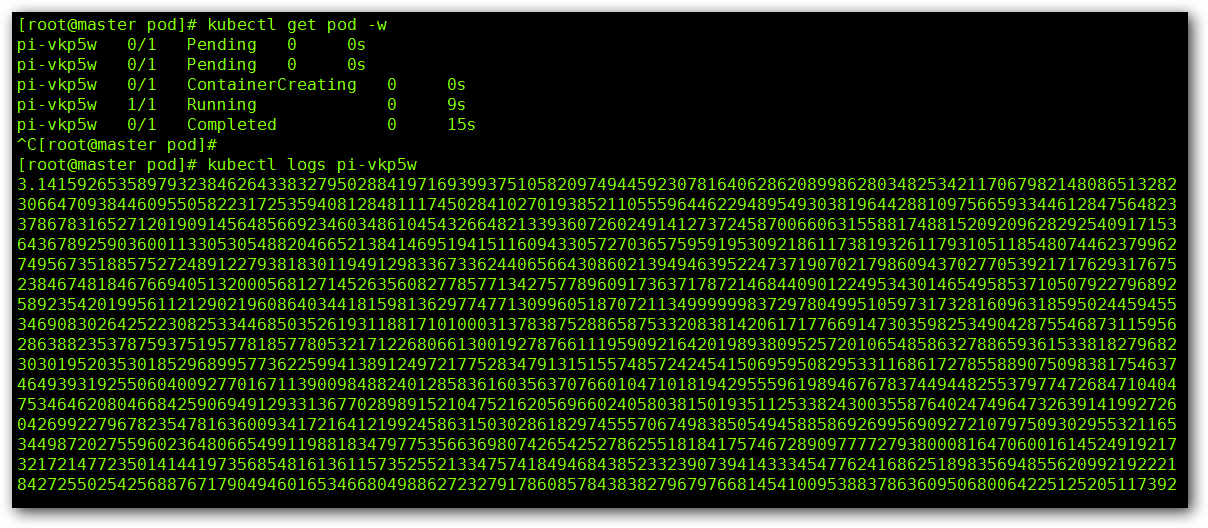
任务完成, π 的2000位信息。
二、Cronjob
Cron Job 管理基于时间的 Job,即:
在给定时间点只运行一次
周期性地在给定时间点运行
使用条件: 当前使用的 Kubernetes 集群,版本 >= 1.8
典型的用法:
在给定的时间点调度 Job 运行
创建周期性运行的 Job,例如:数据库备份、发送邮件
CronJob Spec:
spec.template 格式同 Pod
RestartPolicy 仅支持 Never 或 OnFailure
单个 Pod 时,默认 Pod 成功运行后 Job 即结束
spec.schedule: 调度,必需字段,指定任务运行周期,格式同 Cron
spec.jobTemplate: Job 模板,必需字段,指定需要运行的任务,格式同 Job
spec.startingDeadlineSeconds: 启动 Job 的期限(秒级别),该字段是可选的。如果因为任何原因而错过了被调度的时间,那么错过执行时间的 Job 将被认为是失败的。如果没有指定,则没有期限
spec.concurrencyPolicy: 并发策略,该字段也是可选的。它指定了如何处理被 Cron Job 创建的 Job 的并发执行。只允许指定下面策略中的一种:
Allow (默认): 允许并发运行 Job
Forbid : 禁止并发运行,如果前一个还没有完成,则直接跳过下一个
Replace : 取消当前正在运行的 Job,用一个新的来替换
注意,当前策略只能应用于同一个 Cron Job 创建的 Job。如果存在多个 Cron Job,它们创建的 Job 之间总是允许并发运行。
spec.suspend : 挂起,该字段也是可选的。如果设置为 true ,后续所有执行都会被挂起。它对已经开始执行的 Job 不起作用,默认值为 false
spec.successfulJobsHistoryLimit 和 spec.failedJobsHistoryLimit : 历史限制,是可选的字段。它们指定了可以保留多少完成和失败的 Job 。默认情况下,它们分别设置为 3 和 1 。设置限制的值为 0 ,相关类型的 Job 完成后将不会被保留。
Cronjob 应用示例:
vim cronjob.yaml
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: hello
spec:
schedule: "*/1 * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: docker.io/busybox
args:
- /bin/sh
- -c
- date; echo Hello from the Kubernetes cluster
restartPolicy: OnFailure
然后我们来运行我们的 Cronjob:
我们来查看一下我们的 Pod :

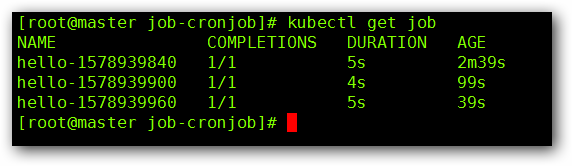
我们来查看一下我们的 Job :
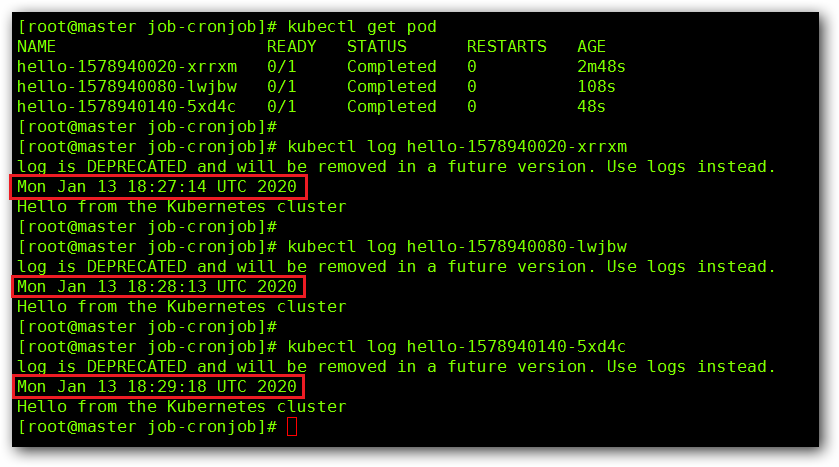
我们来查看一下我们的日志信息: