Hadoop3.2.4纠删码介绍(一)
1、介绍
纠删码是Hadoop3新加入的功能,之前的HDFS都是采用副本方式容错,默认情况下,一个文件有3个副本,可以容忍任意2个副本(DataNode)不可用,这样提高了数据的可用性,但也带来了2倍的冗余开销。例如3TB的空间,只能存储1TB的有效数据。而纠删码则可以在同等可用性的情况下,节省更多的空间,以rs-6-3-1024K这种纠删码策略为例子,6份原始数据,编码后生成3份校验数据,一共9份数据,只要最终有6份数据存在,就可以得到原始数据,它可以容忍任意3份数据不可用,而冗余的空间只有原始空间的0.5倍,只有副本方式的1/4,因此,可以大大节约成本。
2、启用纠删码
1.通过修改配置文件hdfs-site.xml,保存后退出需要重启HDFS服务。
<!-- 启用 EC 编码 --> <property> <name>dfs.namenode.ec.enabled</name> <value>true</value> </property> <!-- 设置 EC 编码方案,例如 RS-6-3 表示 6 数据块和 3 编码块 --> <property> <name>dfs.namenode.ec.system.default.policy</name> <value>XOR-2-1-1024k</value> </property>

备注:
参数:dfs.namenode.ec.system.default.policy 描述:默认的纠删码编码策略,这里可以看到是XOR-2-1-1024k。在后台依旧还是可以单独对目录进行设置。
3、纠删码策略介绍
首先我们查看一下系统中具体支持的纠删码策略类型。
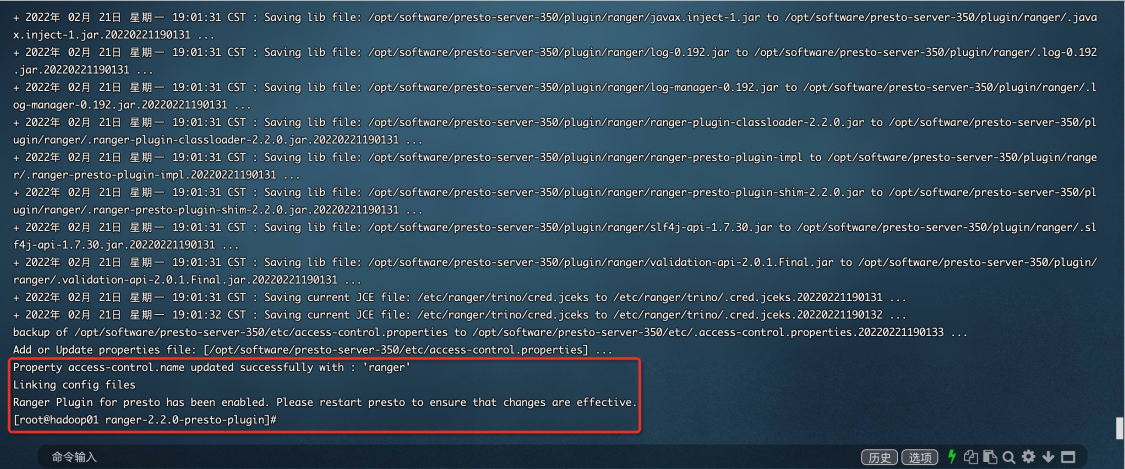
[root@hd2 hadoop]# hdfs ec -listPolicies SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/opt/hadoop-3.2.4/share/hadoop/common/lib/slf4j-reload4j-1.7.35.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/opt/apache-tez-0.10.2-bin/lib/slf4j-reload4j-1.7.36.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.slf4j.impl.Reload4jLoggerFactory] Erasure Coding Policies: ErasureCodingPolicy=[Name=RS-10-4-1024k, Schema=[ECSchema=[Codec=rs, numDataUnits=10, numParityUnits=4]], CellSize=1048576, Id=5], State=DISABLED ErasureCodingPolicy=[Name=RS-3-2-1024k, Schema=[ECSchema=[Codec=rs, numDataUnits=3, numParityUnits=2]], CellSize=1048576, Id=2], State=ENABLED ErasureCodingPolicy=[Name=RS-6-3-1024k, Schema=[ECSchema=[Codec=rs, numDataUnits=6, numParityUnits=3]], CellSize=1048576, Id=1], State=DISABLED ErasureCodingPolicy=[Name=RS-LEGACY-6-3-1024k, Schema=[ECSchema=[Codec=rs-legacy, numDataUnits=6, numParityUnits=3]], CellSize=1048576, Id=3], State=DISABLED ErasureCodingPolicy=[Name=XOR-2-1-1024k, Schema=[ECSchema=[Codec=xor, numDataUnits=2, numParityUnits=1]], CellSize=1048576, Id=4], State=ENABLED

可以看到一共有5种纠删码策略,这里具体解释一下:
1.RS-10-4-1024k:使用RS编码,每10个数据单元(cell),生成4个校验单元,共14个单元,也就是说:这14个单元中,只要有任意的10个单元存在(不管是数据单元还是校验单元,只要总数=10),就可以得到原始数据。每个单元的大小是1024k=1024*1024=1048576B。 2.RS-3-2-1024k:使用RS编码,每3个数据单元,生成2个校验单元,共5个单元,也就是说:这5个单元中,只要有任意的3个单元存在(不管是数据单元还是校验单元,只要总数=3),就可以得到原始数据。每个单元的大小是1024k=1024*1024=1048576B。 3.RS-6-3-1024k:使用RS编码,每6个数据单元,生成3个校验单元,共9个单元,也就是说:这9个单元中,只要有任意的6个单元存在(不管是数据单元还是校验单元,只要总数=6),就可以得到原始数据。每个单元的大小是1024k=1024*1024=1048576B。 4.RS-LEGACY-6-3-1024k:策略和上面的RS-6-3-1024k一样,只是编码的算法用的是rs-legacy,应该是之前遗留的rs算法。 5.XOR-2-1-1024k:使用XOR编码(速度比RS编码快),每2个数据单元,生成1个校验单元,共3个单元,也就是说:这3个单元中,只要有任意的2个单元存在(不管是数据单元还是校验单元,只要总数=2),就可以得到原始数据。每个单元的大小是1024k=1024*1024=1048576B。 以RS-6-3-1024k为例,6个数据单元+3个校验单元,可以容忍任意的3个单元丢失,冗余的数据是50%。而采用副本方式,3个副本,冗余200%,却还不能容忍任意的3个单元丢失。因此,RS编码在相同冗余度的情况下,会大大提升数据的可用性,而在相同可用性的情况下,会大大节省冗余空间。