大数据组件Apache NiFi
概述
NiFi是美国国家安全局开发并使用了8年的可视化数据集成产品,2014年NAS将其贡献给了Apache社区,2015年成为Apache顶级项目。是一个基于Web图形界面,通过拖拽、连接、配置完成基于流程的编程,实现数据采集等功能的数据处理与分发系统。
说明:
Apache NiFi 是为数据流设计
支持高度可配置指示图的数据路由、转换和系统中介逻辑
支持从多种数据源动态拉取数据
NiFi是基于Java的,使用Maven支持包的构建管理
NiFi基于Web方式工作,后台在服务器上进行调度
用户可以为数据处理定义为一个流程,然后进行处理,后台具有数据处理引擎、任务调度等组件。
NiFi架构
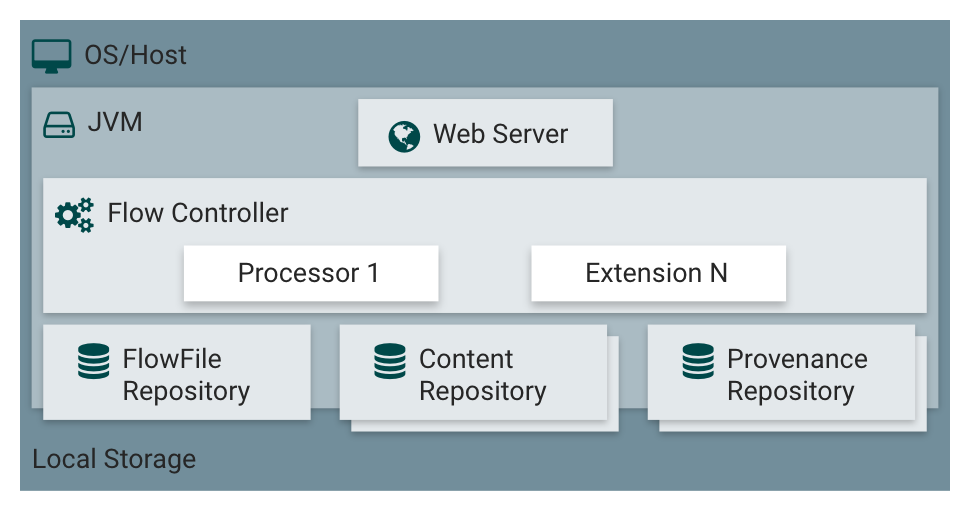
JVM上NiFi的主要组件
(1)FlowFile(信息流) FlowFile代表每个被系统处理的数据对象。每个FlowFile由两部分组成:属性和内容。内容是数据本身,属性是与数据相关的key-value键值对,用于描述数据
(2)Processor(黑盒) FlowFile Processor数据流处理器是nifi中真正处理工作的,例可以用来创建、发送、接受、转换、路由、分割、合并、处理 FlowFiles,数据流处理器可以接收上游的flow的attribute,以及content。数据流处理器可以处理0至多个流,并给出相应的反馈,比如提交或者回滚。Processor可以访问给定的FlowFile
(3)Connection(有界缓冲区) 提供Processors之间的连接,作为Processors之间的缓冲队列。用来定义Processors之间的执行关系,并允许不同Processors之间以不同的速度进行交互
(4)Process Group(子网) 一个特定集合的Processors与他们之间的连接关系形成一个ProcessGroup
(5)Flow Controller(调度) 流量控制器负责管理有多少处理器的连接和管理线程以及分配资源,他作为不同处理器之间的数据流交换代理
(6)Reporting Task Reporting Task是一种后台运行的组件,可将Metrics指标、监控信息、内部NiFi状态发送到外部
(7)Funnel 漏斗是一个NiFi组件,用于将来自多个连接的数据组合成单个连接
4. NiFi的参数配置和目录结构
(1)bin目录下放置了 整个系统的控制脚本
(2)lib目录下放置的Nifi自带的一个个nar程序包(其实就是Nifi内置的一个个组件)和它本身的程序所需要的加载编译等等的底层包
(3)state是运行期间的一些数据
(4)docs和work 是Nifi的一些官方文档和学习样例
5. Apache NiFi处理器的类别介绍
NiFi包含许多不同的处理器。这些处理器提供了可从众多不同系统中提取数据、路由、转换、处理、拆分和聚合数据以及将数据分发到多个系统的功能。
(1)数据转换
CompressContent:压缩或解压
ConvertCharacterSet:将用于编码内容的字符集从一个字符集转换为另一个字符集
EncryptContent:加密或解密
ReplaceText:使用正则表达式修改文本内容
TransformXml:应用XSLT转换XML内容
JoltTransformJSON:应用JOLT规范来转换JSON内容
(2)路由和调解
ControlRate:限制流程中数据流经某部分的速率
DetectDuplicate:根据一些用户定义的标准去监视发现重复的FlowFiles。通常与HashContent一起使用
DistributeLoad:通过只将一部分数据分发给每个用户定义的关系来实现负载平衡或数据抽样
MonitorActivity:当用户定义的时间段过去而没有任何数据流经此节点时发送通知。(可选)在数据流恢复时发送通知。
RouteOnAttribute:根据FlowFile包含的属性路由FlowFile。
(3)数据库访问
ConvertJSONToSQL:将JSON文档转换为SQL INSERT或UPDATE命令,然后将其传递给PutSQL处理器
ExecuteSQL:执行用户定义的SQL SELECT命令,将结果写入Avro格式的FlowFile
PutSQL:通过执行FlowFile内容定义的SQL DDM语句来更新数据库
SelectHiveQL:针对Apache Hive数据库执行用户定义的HiveQL SELECT命令,将结果以Avro或CSV格式写入FlowFile
PutHiveQL:通过执行由FlowFile的内容定义的HiveQL DDM语句来更新Hive数据库
(4)属性提取
EvaluateJsonPath:用户提供JSONPath表达式(与用于XML解析/提取的XPath类似),然后根据JSON内容评估这些表达式,以替换FlowFile内容或将该值提取到用户命名的属性中。
EvaluateXPath:用户提供XPath表达式,然后根据XML内容评估这些表达式,以替换FlowFile内容,或将该值提取到用户命名的属性中。
EvaluateXQuery:用户提供XQuery查询,然后根据XML内容评估此查询,以替换FlowFile内容或将该值提取到用户命名的属性中。
ExtractText:用户提供一个或多个正则表达式,然后根据FlowFile的文本内容进行评估,然后将提取的值作为用户命名的属性添加。
HashAttribute:对用户定义的现有属性列表的并置执行散列函数。
(5)系统交互
ExecuteProcess:运行用户定义的Operating System命令。进程的StdOut被重定向,使得写入StdOut的内容成为出站FlowFile的内容。该处理器是源处理器 - 其输出预计将生成一个新的FlowFile,并且系统调用预期不会接收输入。为了向进程提供输入,请使用ExecuteStreamCommand处理器。
ExecuteStreamCommand:运行用户定义的Operating System命令。FlowFile的内容可选地流式传输到进程的StdIn。写入StdOut的内容成为hte出站FlowFile的内容。该处理器不能使用源处理器 - 它必须被馈送进入FlowFiles才能执行其工作。要使用源处理器执行相同类型的功能,请参阅ExecuteProcess Processor。(6)数据接入
GetFile:将文件的内容从本地磁盘(或网络连接的磁盘)流入NiFi。
GetFTP:通过FTP将远程文件的内容下载到NiFi中。
GetSFTP:通过SFTP将远程文件的内容下载到NiFi中。
GetJMSQueue:从JMS队列中下载消息,并根据JMS消息的内容创建一个FlowFile。也可以将JMS属性复制为属性。
GetJMSTopic:从JMS主题下载消息,并根据JMS消息的内容创建一个FlowFile。也可以将JMS属性复制为属性。此处理器支持持久和非持久订阅。
GetHTTP:将基于HTTP或HTTPS的远程URL的内容下载到NiFi中。处理器将记住ETag和Last-Modified Date,以确保数据不会持续摄取。
(7)数据出口/发送数据
PutEmail:向配置的收件人发送电子邮件。FlowFile的内容可选择作为附件发送。
PutFile:将 FlowFile的内容写入本地(或网络连接)文件系统上的目录。
PutFTP:将 FlowFile的内容复制到远程FTP服务器。
PutSFTP:将 FlowFile的内容复制到远程SFTP服务器。
(8)分割和聚合
SplitText:SplitText采用单个FlowFile,其内容为文本,并根据配置的行数将其拆分为1个或更多个FlowFiles。例如,处理器可以配置为将FlowFile拆分成许多FlowFiles,每个FlowFiles只有1行。
SplitJson:允许用户将由数组或许多子对象组成的JSON对象拆分为每个JSON元素的FlowFile。
SplitXml:允许用户将XML消息拆分成许多FlowFiles,每个FlowFiles都包含原始的段。当通过“包装”元素连接几个XML元素时,通常使用这种方法。然后,该处理器允许将这些元素分割成单独的XML元素。
(9)HTTP
GetHTTP:将基于HTTP或HTTPS的远程URL的内容下载到NiFi中。处理器将记住ETag和Last-Modified Date,以确保数据不会持续摄取。
ListenHTTP:启动HTTP(或HTTPS)服务器并监听传入连接。对于任何传入的POST请求,请求的内容将作为FlowFile写出,并返回200个响应。