网络抓包实战
1、为什么要学习抓包?
主要是因为碰到网络相关问题,如果不进行抓包的话,可能会很难进行定位解决,抓包可以看做是另类的日志信息收集。对于解决网络问题至关重要。
2、抓包
普通环境
tcpdump -- a powerful command-line packet analyzer
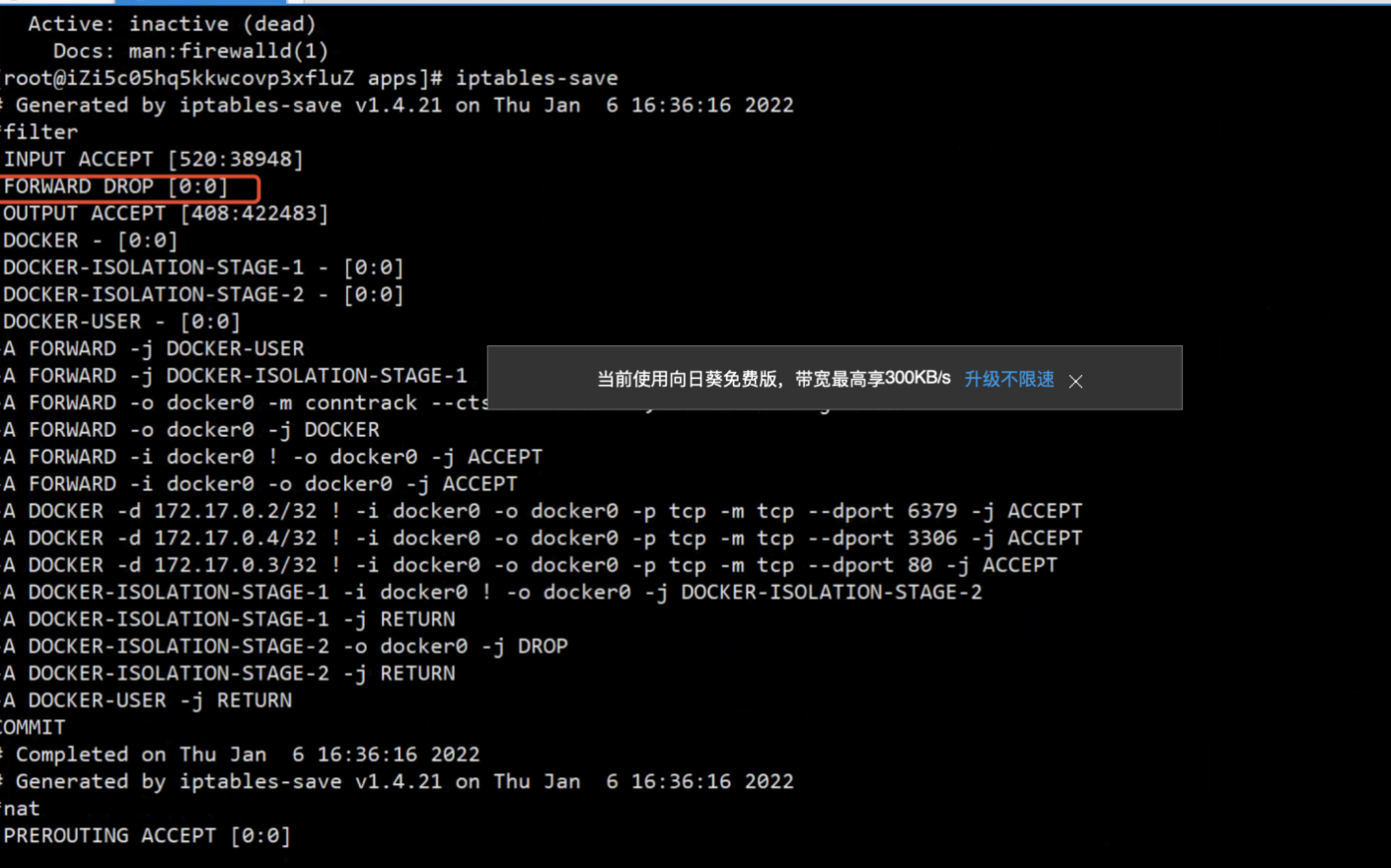
-i interface 监听指定的网卡接口 -w file 把抓取到的数据包保存到指定文件 -C FILE_SIZE 指定保存到磁盘的数据包大小,单位是MB -W filecount 指定保存数据包的文件的个数 -tt Print the timestamp, as seconds since January 1, 1970, 00:00:00, UTC, and fractions of a second since that time, on each dump line. 抓包的时候保存timestamp时间戳
容器环境
nsenter -- run program in different namespaces
-t, --target PID -n, --net[=file]
Nsenter 原理为:在宿主机上面挂载容器的网络命名空间,这样就可以使用宿主机上面的命令,对容器进行抓包。
使用方法为:
# 例如抓取MySQL 容器的网络数据包
docker ps | grep mysql
5ab958ac6c60 b05128b000dd "docker-entrypoint.s…" 7 days ago Up 7 days k8s_mysql_mysql-ffcc44677-446wh_default_846b649b-c97f-4df2-a3cd-61757cc465de_0
# 根据查询到的容器ID,查看容器进程在宿主机上面的Pid
docker inspect -f {{.State.Pid}} 5ab958ac6c60
116011
# 或者 使用 grep 进行过滤查看
docker inspect 5ab958ac6c60 | grep -i pid
"Pid": 116011,
"PidMode": "",
"PidsLimit": 0,
# 然后使用nsenter 进入MySQL 容器的网络命名空间
nsenter -n -t 116011
# 最后通过 ip a 命令可以看到我们已经进入MySQL容器的网络命名空间
ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
9: eth0@if10: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UP group default
link/ether 02:42:0a:63:28:03 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 10.99.40.3/21 brd 10.99.47.255 scope global eth0
valid_lft forever preferred_lft forever3、分析包
wireshark -- is the world’s foremost and widely-used network protocol analyzer
初始界面:

包分析界面:

4、实战案例
a、客户网络出现问题,环境是:java连接后端oracle数据库,现象是:刚开始可以Telnet通oracle的1521端口,后面过了一段时间后,无法Telnet连通oracle1521端口。
第一次抓包:

从上面的数据包,我们可以看到客户端:10.0.7.240 与数据库 172.17.3.5 建立TCP连接的时候,被拒绝了,这个一看就知道肯定不是数据库做的,应该是网络链路中存在防火墙或者数据库所在的Linux系统开启了防火墙之类的。要再在客户端和数据库两边都进行抓包,确定到底是网络链路中的设备还是数据库本身系统的配置。
第二次抓包:
这里就不上图片了,跟第一次抓包的情况是一样的,不过可以确定的是:数据库端的网络包里面,没有客户端的网络包,基于此我们可以确定网络链路中存在防火墙之类的设备,进行了拦截。但是客户反馈说:网络中确实有防火墙,但是策略是已经放开了客户端的IP,应该不是防火墙的问题。
第三次抓包:

通过上面的数据包,我们可以看到:刚开始的时候,TCP连接是正常的,到最后突然就不能进行TCP连接了,这个跟之前问题的描述也是可以对应上的。我们应该是已经接近事情的真相了。
对抓的数据包进行分析:

我们通过跟踪TCP流,可以看到应用是卡在登录认证这一步了,怀疑是账号密码存在问题,或者是JDBC驱动不兼容登录不了oracle数据库。最终跟客户排查确定:账号密码错误
b、客户连接数据库网络失败,但是Telnet一直是可以连通数据库的1521端口的,怀疑存在网络问题。

从上面的图片,我们可以看到:客户端10.0.7.239去连 172.17.2.10,完成整个TCP握手的过程之后,很快就断开TCP连接了,这需要我们进行更深一步的分析。

我们通过跟踪TCP流,可以看到:客户端去连接数据库172.17.2.10,但是数据库返回让去连接172.17.2.11。我们再通过上一个图片,可以看到:连接172.17.2.11没有反应,客户端重试了3次。怀疑存在相关的安全策略导致的丢包。
最终结果为:阿里云安全组出方向存在限制,只能访问172.17.2.10,不能访问172.17.2.11。之所以访问oracle 数据库的时候,出现这样的情况,是因为此数据库架构为RAC架构。172.17.2.10为RAC架构的虚拟IP,只放行虚拟IP是不行的,还需要放行后端的真实IP。