副本集的同步、心跳、选举、回滚
一、副本集同步过程
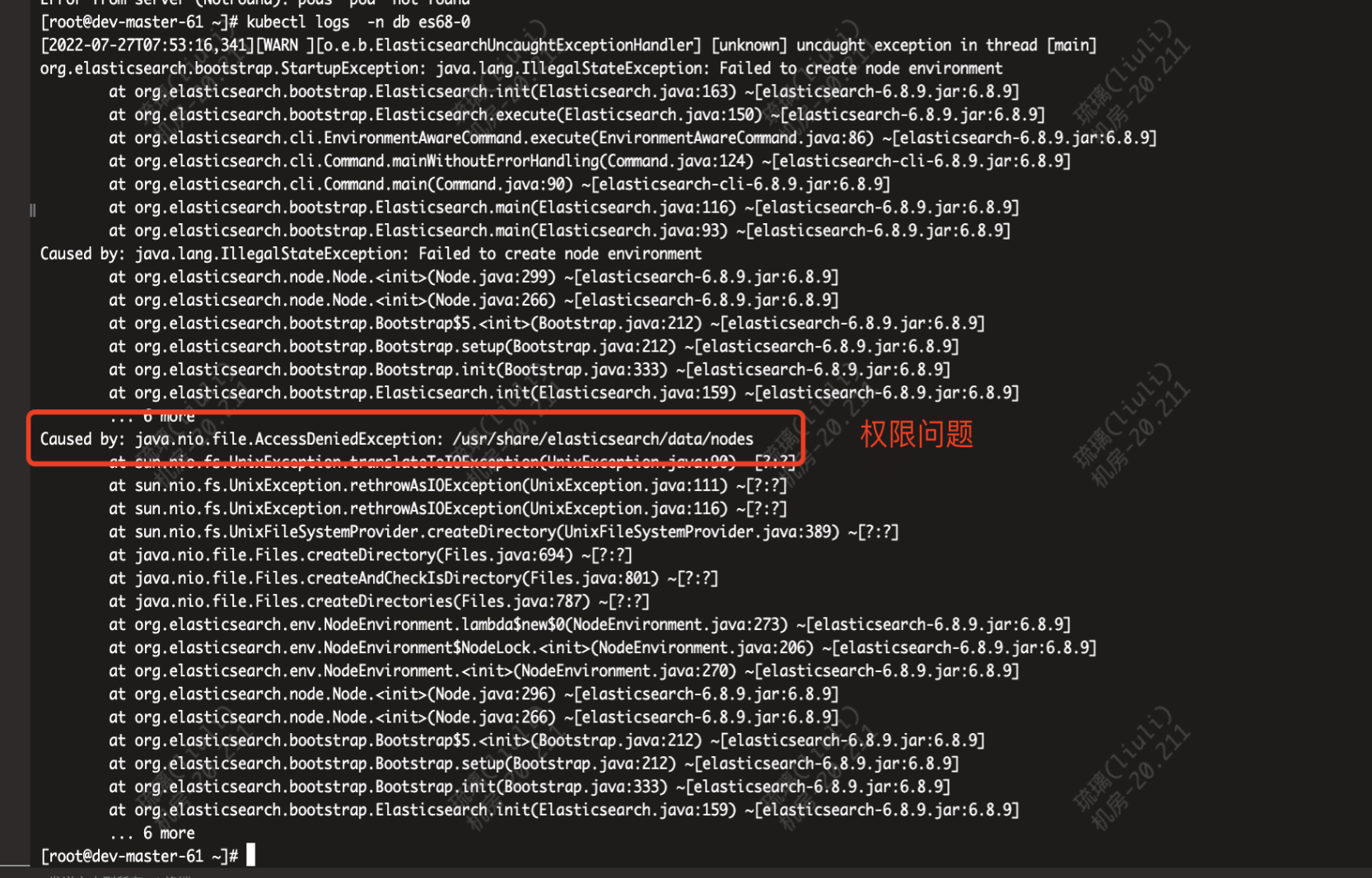
MongoDB的复制功能是依赖与oplog来实现的。
1.数据写入主节点同时在local.oplog.rs集合写入对应的oplog
2.备份节点第一次同步数据时,会先进行init sync,然后从主节点同步全量数据
3.随后,备份节点不断通过tailable cursor从主节点的local.oplog.rs集合中查询最新的oplog并应用到自身,这个过程叫做replication
二、初始化同步过程
1、什么情况下secondary节点会进行初始化同步?
1.oplog为空
主要针对新加入的节点
2.local.replset.minvalid集合里的_initialSyncFlag字段设置为true
当进行初始化同步开始时,mongodb会自动将_initialSyncFlag字段标记为true,初始化同步成功后再设置为false。再初始化期间,若secondary节点意外宕机重启,初始化同步失败,mongodb会优先检查_initialSyncFlag字段标记,若标记为true,表示初始化未完成,重新进行初始化操作。
3.内存标记initialSyncRequested设置为true
2、 初始化同步的过程
1.全量同步开始,设置minvalid集合的_initialSyncFlag 2.获取同步源上最新oplog时间戳为t1 3.全量同步集合数据 (耗时) 4.获取同步源上最新oplog时间戳为t2 5.重放[t1, t2]范围内的所有oplog 6.获取同步源上最新oplog时间戳为t3 7.重放[t2, t3]范围内所有的oplog 8.建立集合所有索引 (耗时) 9.获取同步源上最新oplog时间戳为t4 10.重放[t3, t4]范围内所有的oplog 11.全量同步结束,清除minvalid集合的_initialSyncFlag
三、同步
初始化同步完成后,secondary通过tailable cursor不断拉取primary节点的oplog进行重放的过程成为同步。
1、同步的三个线程
1)producer thread
这个线程不断的从同步源上拉取oplog,并加入到一个BlockQueue的队列里保存着。
2)replBatcher thread
这个线程负责逐个从BlockQueue队列里取出oplog,并放到自己维护的队列replBatcher thread里。
3)sync thread
将replBatcher thread的队列分发到默认16个replWriter线程,由replWriter thread来最终重放每条oplog。
2、注意点
1)为什么一个简单的『拉取oplog并重放』的动作要搞得这么复杂?
性能考虑,拉取oplog是单线程进行,如果把重放也放到拉取的线程里,同步势必会很慢;所以设计上producer thread只干一件事。
2)为什么不将拉取的oplog直接分发给replWriter thread,而要多一个replBatcher线程来中转?
oplog重放时,要保持顺序性,而且遇到createCollection、dropCollection等DDL命令时,这些命令与其他的增删改查命令是不能并行执行的,而这些控制就是由replBatcher来完成的。
3)新加入节点时,最好通过备份集来做,尽量避免初始化同步
4)生产环境,通过db.printSlaveReplicationInfo()来监控主备同步滞后的情况
5)当Secondary同步滞后是因为主上并发写入太高导致,(db.serverStatus().metrics.repl.buffer.sizeBytes持续接近db.serverStatus().metrics.repl.buffer.maxSizeBytes),可通过调整Secondary上replWriter并发线程数来提升。
四、对于延迟很大的备份节点的处理
由于主节点和备份节点之前的复制是依赖于oplog的,但是主节点的oplog可以存储数据的大小是固定的,如果在记录还没有被删除之前进行复制备份,那么该节点就无法从主节点上继续进行同步,这中情况下MongoDB是如何做处理的呢?
1、在副本集中寻找oplog更详细,可以继续为当前节点提供复制的节点,如果存在就把该节点当作同步源进行同步
2、如果不存在可以继续进行同步的节点,Secondary的同步将无法正常进行,会进入RECOVERING的状态,需向Secondary主动发送resyc命令重新同步
五、心跳
心跳用于检查每个成员的状态,每个成员每隔2秒就会向其他成员发送一个心跳请求。心跳的一个重要功能是让主节点知道自己是否满足“大多数”原则。
成员的各种状态:
1.STARTUP:成员刚启动时的状态,在这个状态下,该节点会尝试去加载成员的副本集信息,加载成功过后状态变为STARTUP2
2.STARTUP2:初始化同步过程中都会处于这个状态。对于普通的节点,该状态只会持续几秒;对于副本集中的成员,在该状态下会创建几个线程用于复制和选举。之后状态就转为RECOVERING。
3.RECOVERING:该状态表明该节点运行正常但是暂时不能提供读请求。 //可能会造成轻微的系统过载
1)成为备份节点前
2)处理非常耗时的操作时
3)同步复制延迟比较大时
4.ARBITER:仲裁者所属的状态
---出现以下状态表示系统出现了问题
5.DOWN:如果一个正常运行的成员变为不可达(可能是因为网络原因),就会状态DOWN的状态。
6.UNKONWN:一个成员与副本集其它成员变得不可达时(可能是因为宕机也可能是因为网络原因),该成员的状态就为UNKNOWN。
7.REMOVED:当成员被移除副本集的时候,该成员的状态会变为REMOVED。如果被移出成员重新添加到副本集,它就会回到正常状态。
8.ROLLBACK:正在回滚数据时的状态。回滚结束后,状态会变为RECOVERING,然后成为备份节点。
9.FATAL:如果一个成员发生了不可挽回的错误,也不再尝试恢复正常的话,它的状态就是FATAL。
六、选举
当一个节点无法达到主节点的时候,它就会申请被选举为主节点。希望被选举成为主节点的成员会向它能达到的所有节点发送通知,如果得到副本集“大多数”的支持,就会被提升为主节点;如果没有得到副本集“大多数”的支持,它就仍处于备份节点,但是仍然可以向可以达到的各个成员发送选举的通知。
七、回滚
模拟一种回滚场景:
1.主节点与备份节点之间的延迟比较大;
2.主节点宕机,提升一个备份节点为新的主节点;
3.主节点恢复正常,成为备份节点,向同步源中检查oplog查找自身执行的最后一条记录,发现没有匹配记录;
4.该备份节点在自身的oplog和同步源的oplog中找到一个共同的点,将该点到最后一条记录进行回滚;
5.回滚完成后开始正常同步。
需要注意的点:
如果主从之间延迟非常大,需要回滚的数据量大于300MB或者需要回滚的时间超过30分钟以上,则会回滚失败。
对于回滚失败的节点,必须要重新同步。