CDP实操--集群配置Auto-TLS
1.1手动创建CA证书
# mkdir -p /tls/ca # ls /tls # cd /tls/ca # openssl genrsa -out ca.key 2048 # cat ca.key # openssl rsa -check -in ca.key # openssl rsa -text -in ca.key -noout # openssl req -x509 -new -key ca.key -out ca.crt登录IPA Server在services页面里都是ipa自带的服务,集群配置完kereros后,这里会增加集群里各项hadoop服务。


1.2部署Auto-TLS
在CM控制台里从Administration > Security导航进入安全配置页面


ssh免密通信所需要的私钥文件本地路径为/home/training/.ssh/admincourse.pem,其中.ssh文件夹是隐藏目录,需要在右键菜单里选择“Show Hidden Files”




cm server重启完成后,再重启cm管理服务,浏览器登录cm控制台需要选择“Accept the Risk and Continues”


更新配置重启集群:

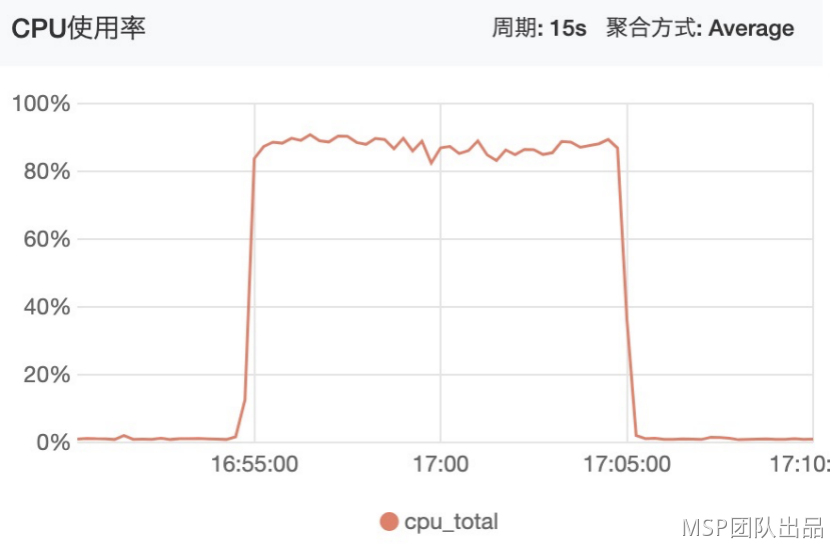
最新集群状态: