数仓主流架构简介之一
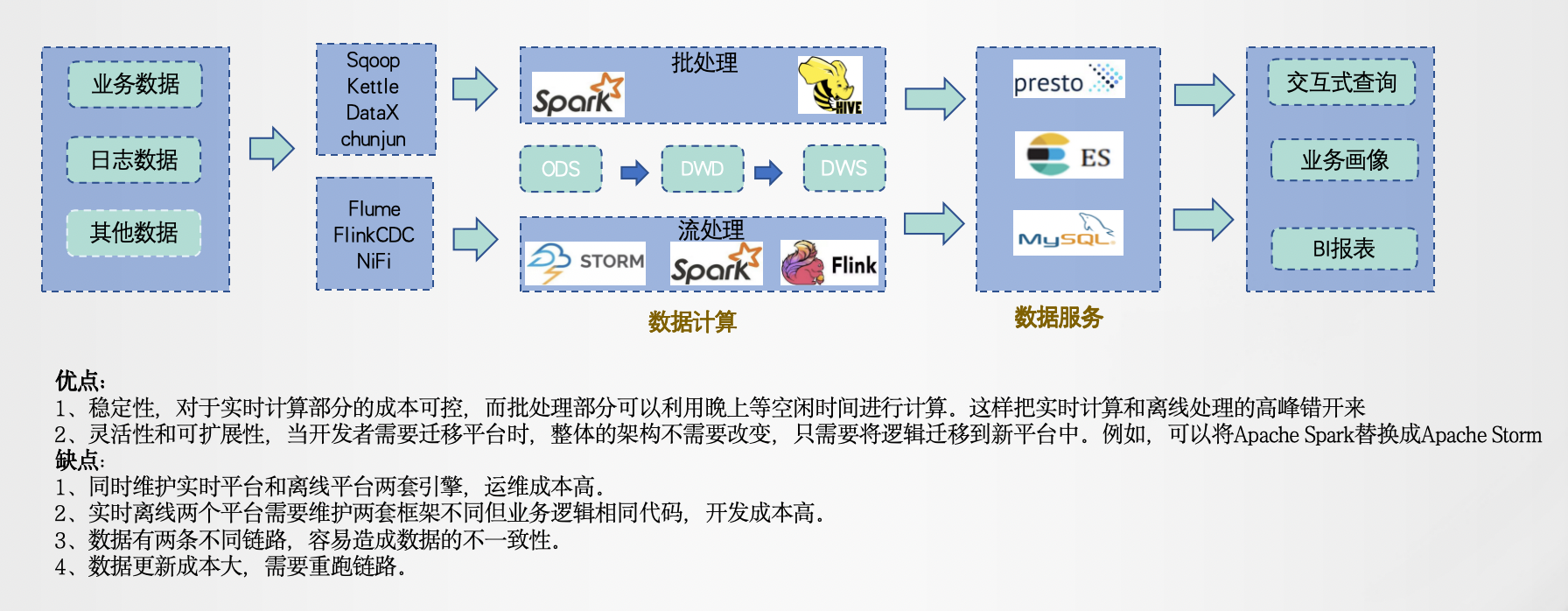
一、Lambda架构
Apache Storm的创建者Nathan Marz于 2011 年开发,旨在解决大规模实时数据处理的挑战。Lambda数据架构提供了一个可扩展、容错且灵活的系统来处理大量数据。它允许以混合方式访问批处理和流处理方法。具有:高容错、低延时和可扩展等,整合了离线计算和实时计算,融合不可变性,读写分离和复杂性隔离等一系列架构原则,可集成Hadoop,Kafka,Storm,Spark,Hbase等各类大数据组件
二、Kappa
2014年7月份由 LinkedIn 的前首席工程师杰伊·克雷普斯(Jay Kreps)提出的一种架构思想。克雷普斯是几个著名开源项目(包括 Apache Kafka 和 Apache Samza 这样的流处理系统)的作者之一。通过改进 Lambda 架构中的Speed Layer,使它既能够进行实时数据处理,同时也有能力在业务逻辑更新的情况下重新处理以前处理过的历史数据
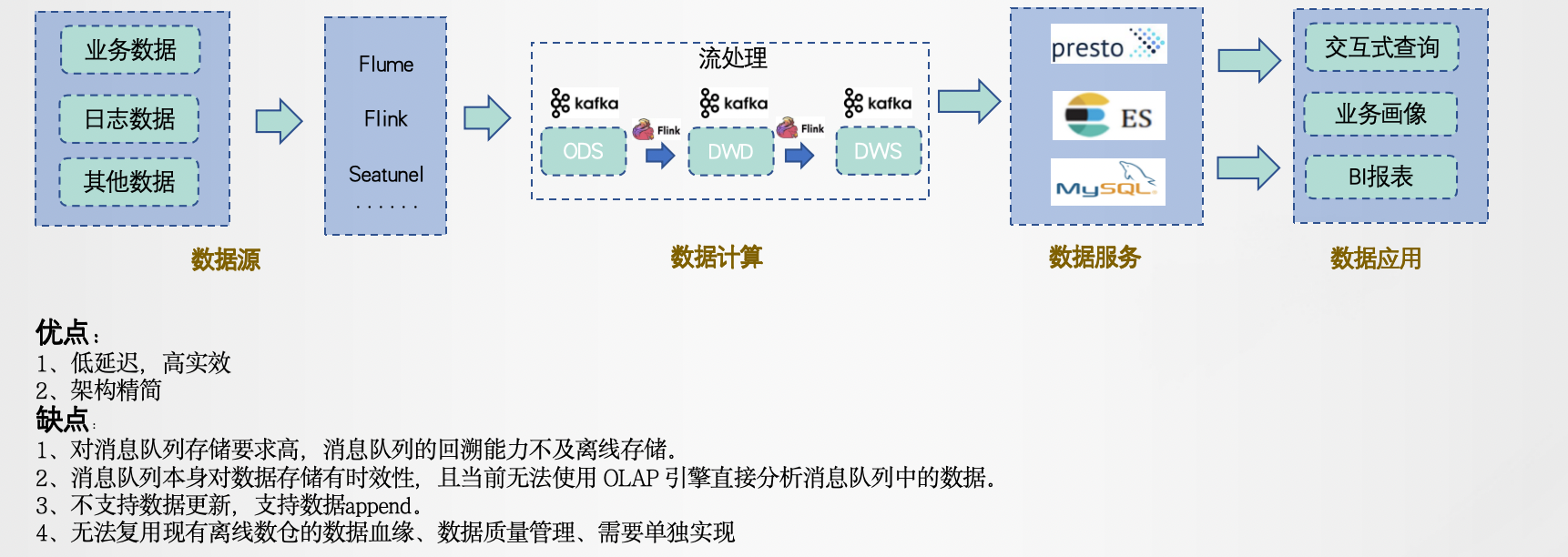
三、Dataflow Model
2015年Google的Tyler Akidau 等提出,DataFlow 模型是一种用于描述数据处理流程的计算模型,它描述了数据从源头到目的地的流动过程,并指定了数据处理的方式和顺序,可以采用混合搭建的方式根据需求自定义搭建系统。

DataFlow 模型的全流程可以分为以下几个步骤:
1、数据源输入:数据源可以是各种类型的数据,例如文件、数据库、消息队列等。在 DataFlow 模型中,数据源被视为数据处理流程的起点,数据从数据源中流入数据处理系统。
2、数据切割:在 DataFlow 模型中,数据可以被分割成多个数据块,这些数据块可以并行处理,以提高数据处理的效率。数据切割可以根据数据的大小、时间戳、键值等方式进行,以便更好地实现数据并行处理。
3、数据转换:在 DataFlow 模型中,数据可以经过一系列的数据转换操作,例如数据清洗、数据过滤、数据聚合等。数据转换操作被描述为有向图中的节点,每个节点可以执行一些特定的数据处理操作,节点之间的边表示数据的流动方向和数据处理顺序。
4、数据聚合:在 DataFlow 模型中,数据可以经过多个数据转换操作后被聚合起来,以便更好地实现数据分析和挖掘。
5、数据输出:在 DataFlow 模型中,数据输出可以是各种类型的数据目的地,例如文件、数据库、消息队列等。数据输出被视为数据处理流程的终点,数据从数据处理系统中输出到数据目的地中。