Ambari集群Spark3.x动态资源分配
| 环境 | 节点 | hdp01 | |
| HDP | 3.1.5 | hdp02 | |
| Spark | 3.2.4 | hdp03 |
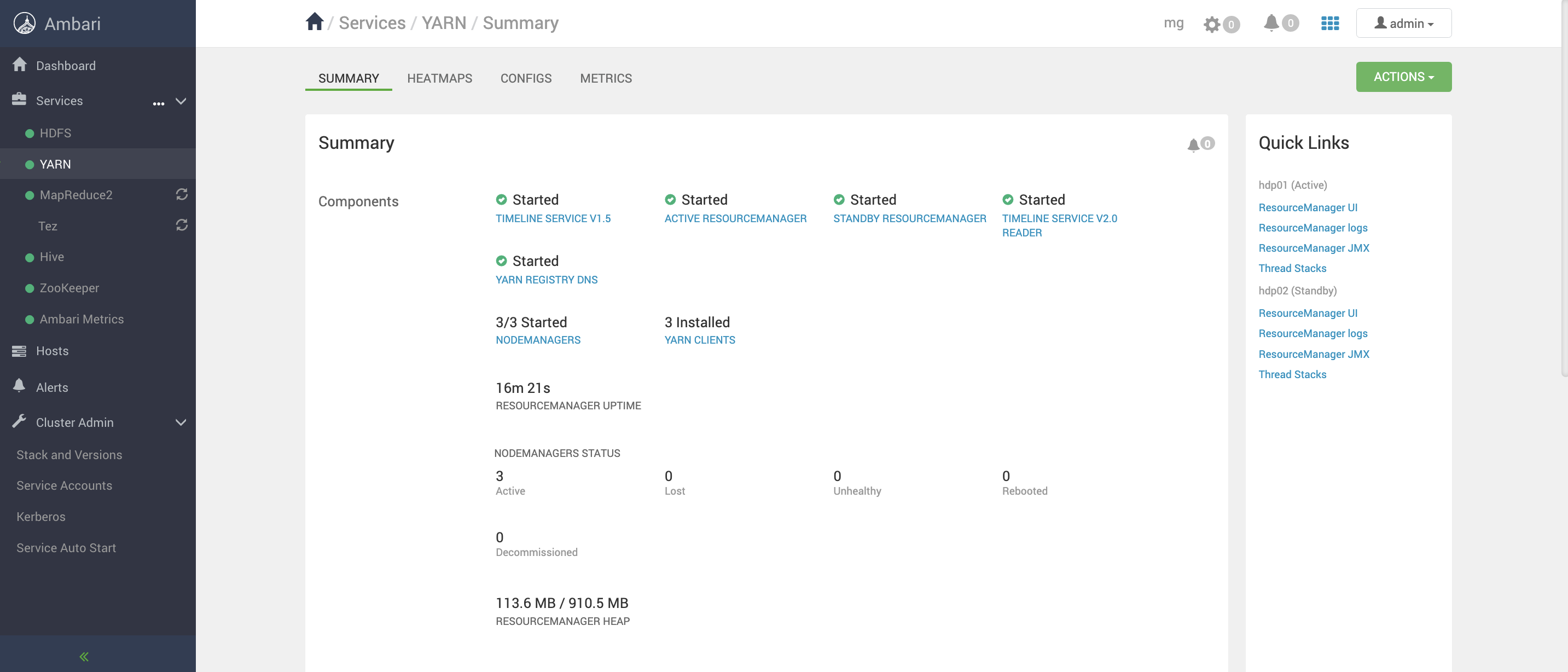
首先Spark配置History服务
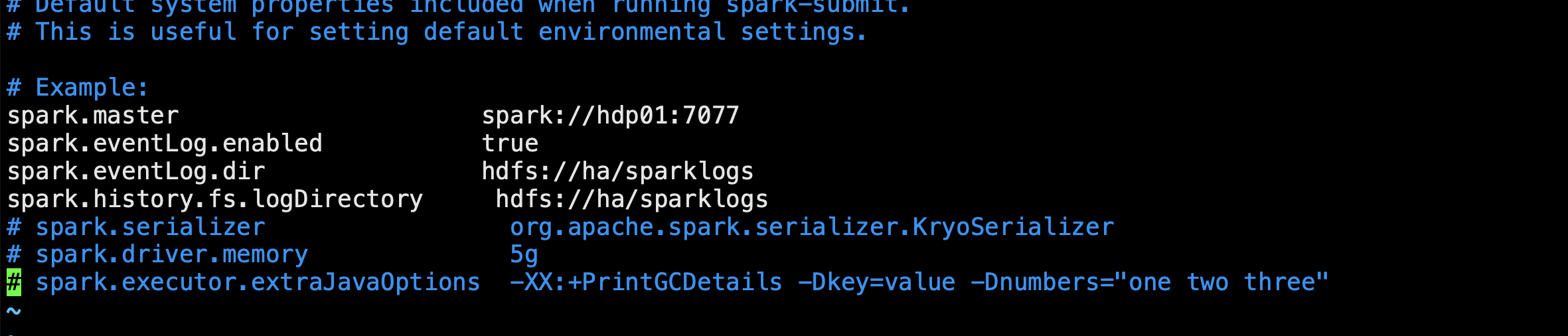
配置spark-defaults.conf
spark.master spark://hdp01:7077
spark.eventLog.enabled true
spark.eventLog.dir hdfs://ha/sparklogs
spark.history.fs.logDirectory hdfs://ha/sparklogs
去hdfs创建对应目录
hdfs dfs -mkdir hdfs://ha/sparklogs
开启start-history-server.sh服务
sbin/start-history-server.sh
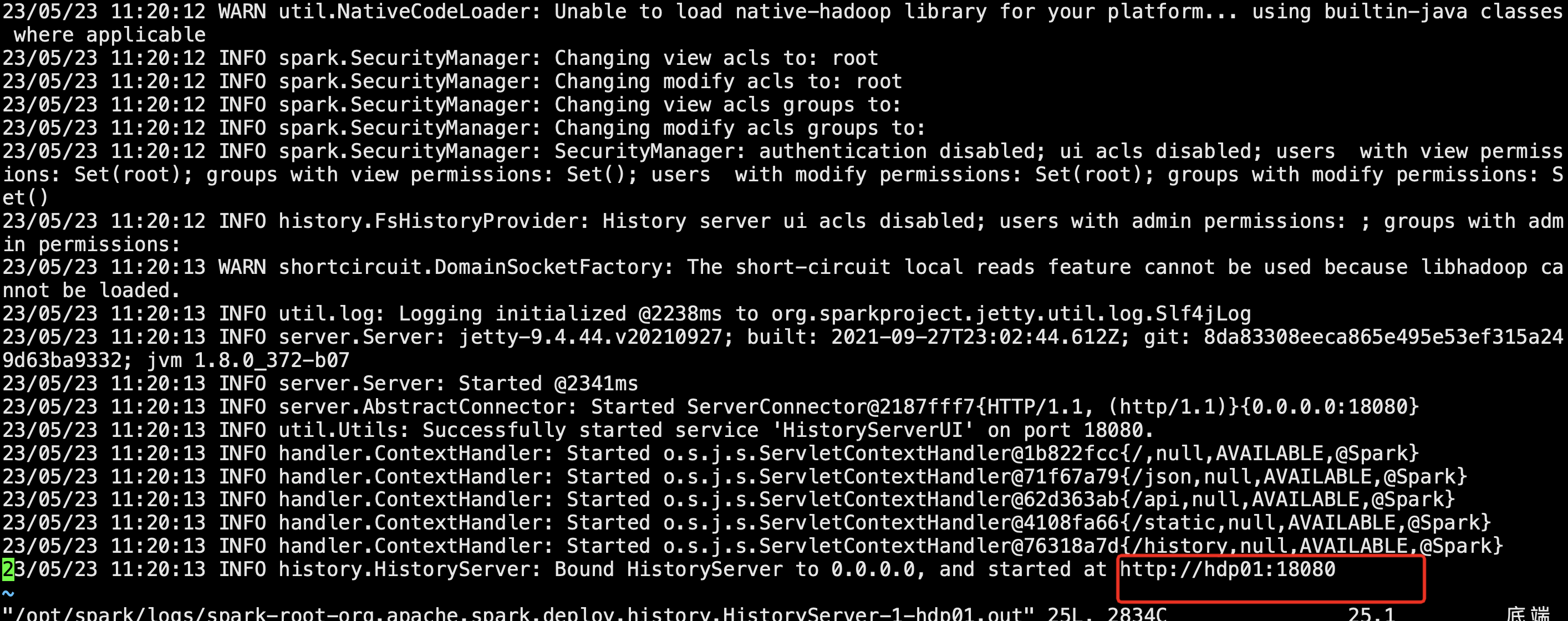
查看日志情况:
vim /opt/spark/logs/spark-root-org.apache.spark.deploy.history.HistoryServer-1-hdp01.out
启动成功
查看History Server WEB
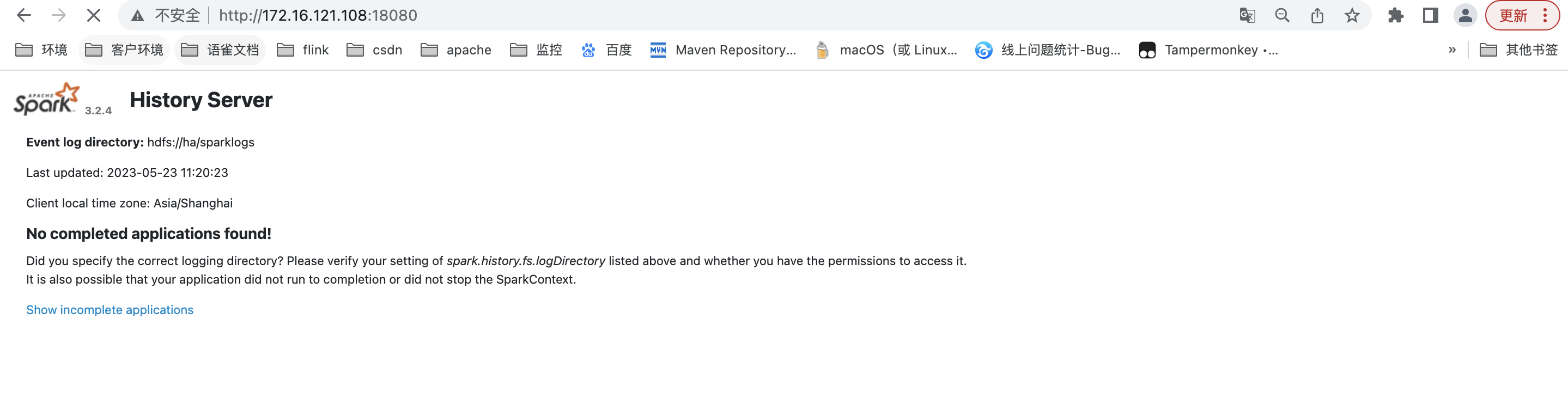
开启动态资源分配前:
提交一个spark任务
bin/spark-shell --master yarn
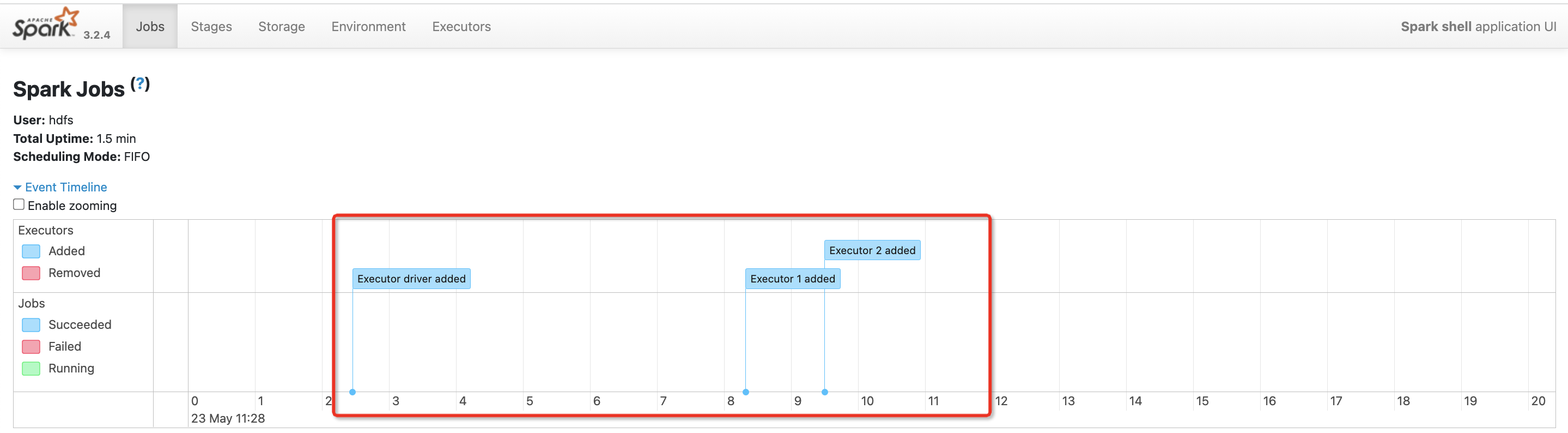
可以看到启动后 已经分配了资源
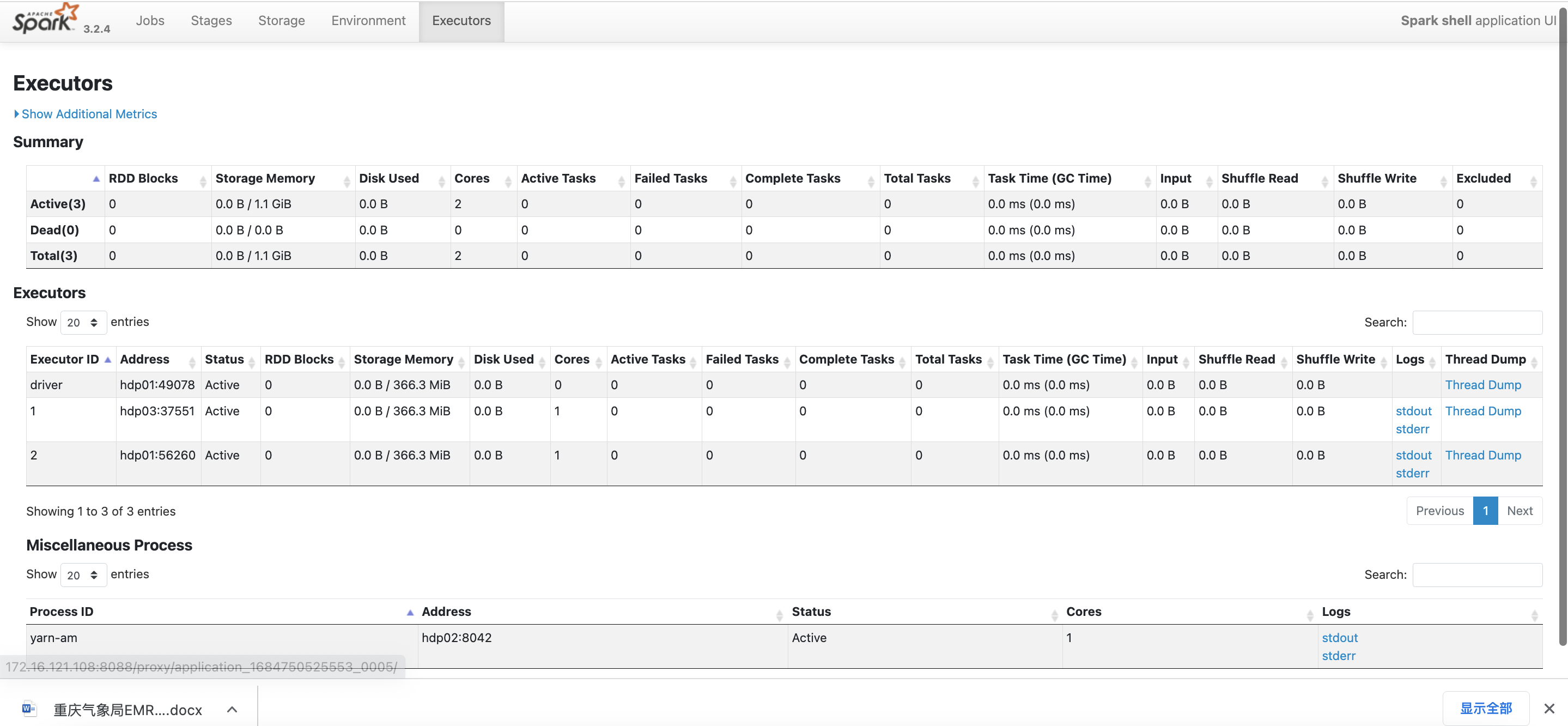
首先配置动态资源分配参数
拷贝spark-version-yarn-shuffle.jar(包含了external shuffle的spark实现)到yarn的lib下
cp /opt/spark/yarn/spark-3.2.4-yarn-shuffle.jar /usr/hdp/3.1.5.0-152/hadoop-yarn/lib/
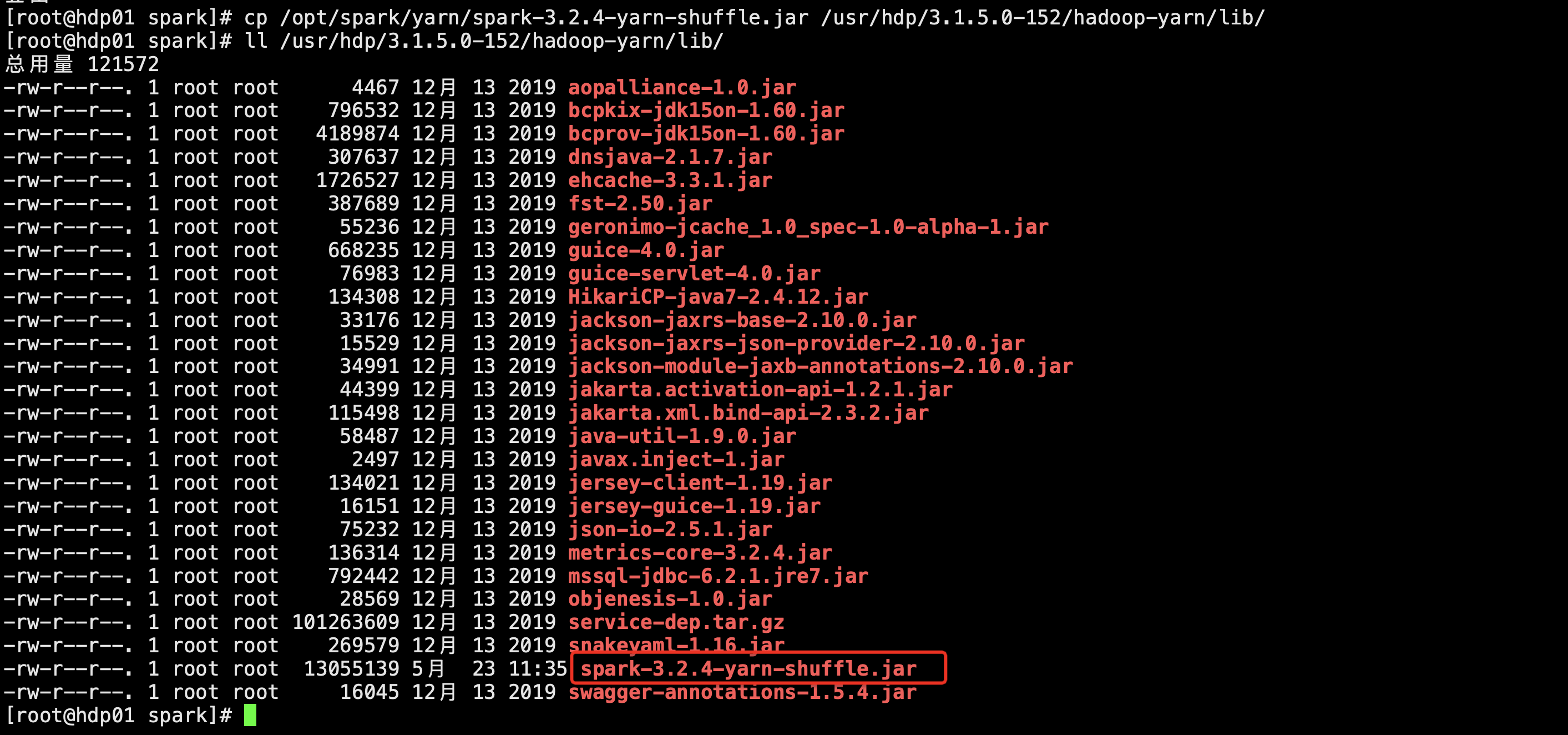
分发其他节点
[root@hdp01 lib]# scp spark-3.2.4-yarn-shuffle.jar hdp02:$PWD
spark-3.2.4-yarn-shuffle.jar 100% 12MB 12.5MB/s 00:01
[root@hdp01 lib]# scp spark-3.2.4-yarn-shuffle.jar hdp03:$PWD
spark-3.2.4-yarn-shuffle.jar 100% 12MB 12.5MB/s 00:00
[root@hdp01 lib]#
修改yarn-site.xml配置文件,增加spark shuffle相关的配置:(Ambari界面修改)
<property>
<name>yarn.nodemanager.aux-services</name>
<value>spark_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.spark_shuffle.class</name>
<value>org.apache.spark.network.yarn.YarnShuffleService</value>
</property>
<property>
<name>spark.shuffle.service.port</name>
<value>7337</value>
</property>
spark.shuffle.service.enabled=true
yarn.nodemanager.aux-services.spark_shuffle.classpath=/opt/spark/yarn/*
yarn.nodemanager.aux-services.spark2_shuffle.classpath=/opt/spark/yarn/*
重启yarn集群
测试动态资源分配
bin/spark-shell \
--master yarn --executor-memory 1g --total-executor-cores 1 \
--conf spark.shuffle.service.enabled=true \
--conf yarn.nodemanager.aux-services.spark_shuffle.classpath=/opt/spark/yarn/* \
--conf spark.dynamicAllocation.enabled=true \
--conf spark.dynamicAllocation.executorIdleTimeout=60s \
--conf spark.shuffle.service.port=7337
查看spark webui
可以看到没有执行action操作==没有分配Executor
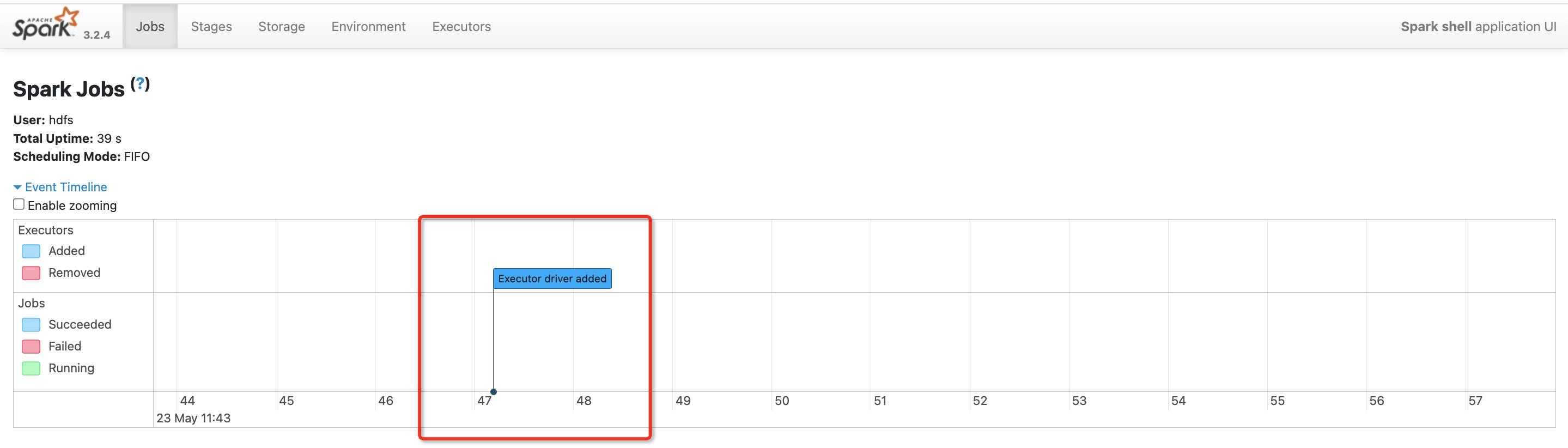
在spark-shell执行操作
val lineText=sc.textFile("hdfs://ha/spark.txt")
lineText.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).foreach(println)
执行后我们可以看到 执行的时候分配了Executor
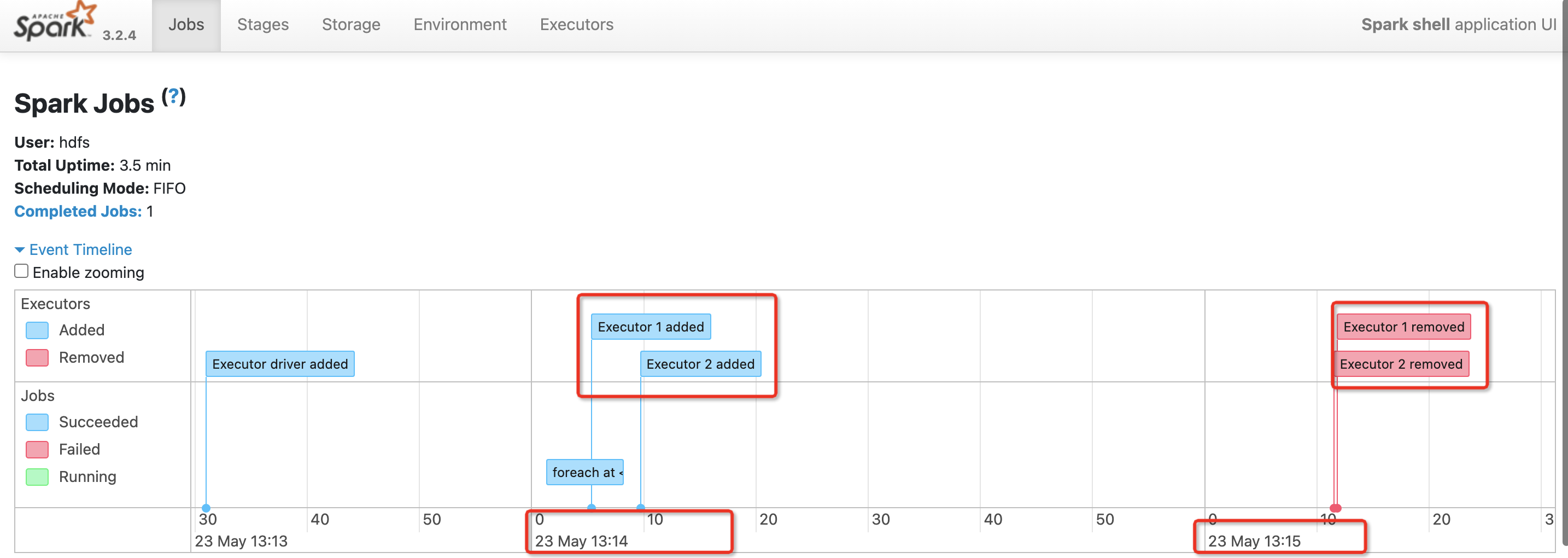
但是过了60s之后Executor没有任务运行 就会remove Executor释放资源。
再次运行
lineText.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).foreach(println)