Apache hive 对接达梦数据库
1、背景
由于国产化需求,客户需要使用dm数据库作为hive的元数据库。需要进行对应适配
2、配置
本次使用的环境
hive 3.1.3 hadoop 3.2.4 ranger 2.3.0 Spark 3.2.2
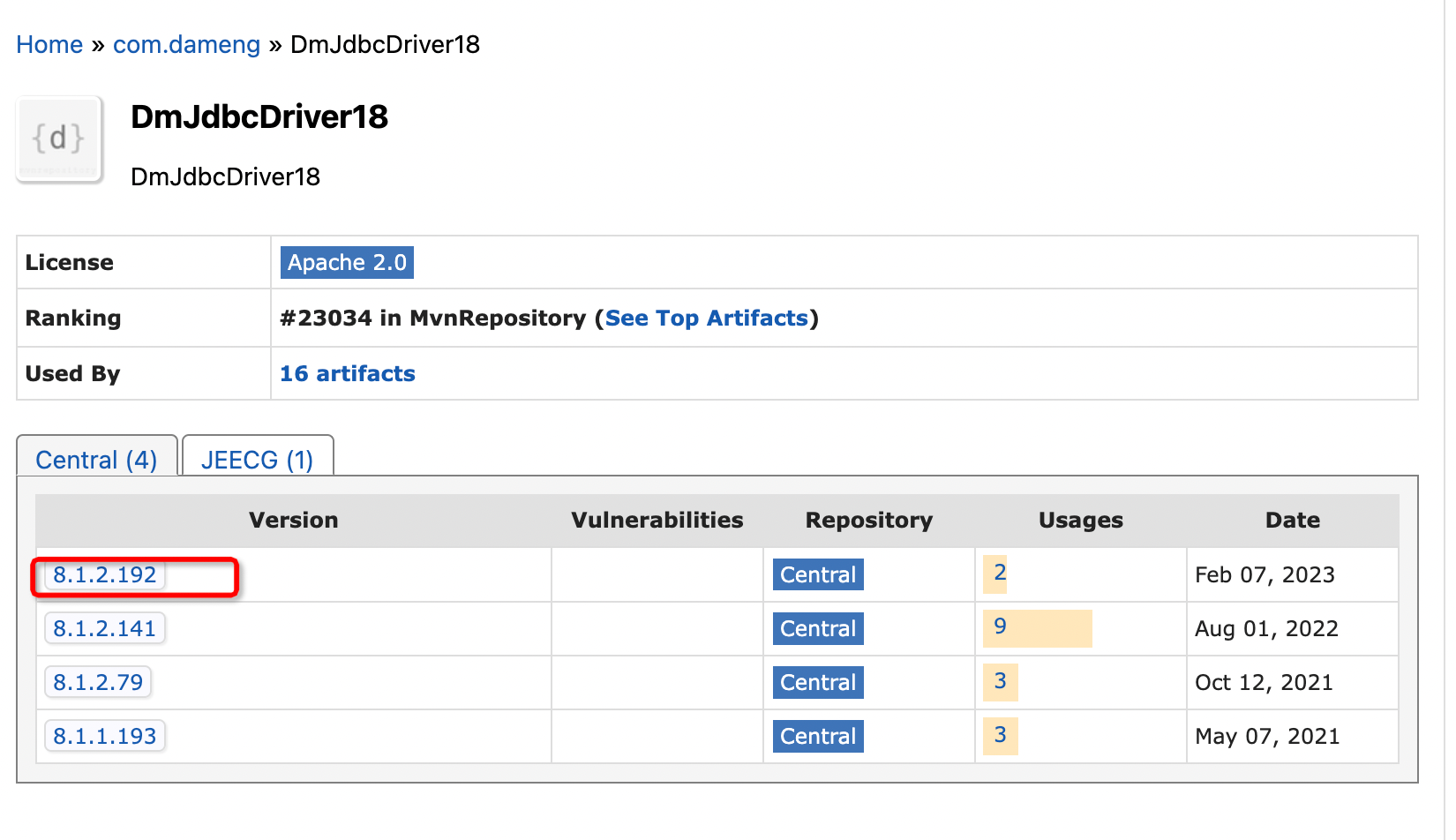
下载dm的jdbc 包放置在HIVE_HOME/lib和/usr/share/java下
下载地址
https://mvnrepository.com/artifact/com.dameng/DmJdbcDriver18

注释以下hive-site.xml配置
<property> <name>datanucleus.schema.autoCreateAll</name> <value>true</value> </property> <property> <name>hive.txn.manager</name> <value>org.apache.hadoop.hive.ql.lockmgr.DbTxnManager</value> </property>
准备hive的dm数据库
create tablespace hive_meta datafile '/dm8/data/DAMENG/hive_meta.dbf' size 100 autoextend on next 1 maxsize 2048; create user hive identified by "hive12345" default tablespace hive_meta; grant RESOURCE to hive;
对hive-site.xml进行配置
准备dm的数据源连接
在$HIVE_HOME/conf下添加此配置文件
vim dm_svc.conf IME_ZONE=(480) LANGUAGE=(cn) HIVE=(172.16.104.165:5236) [HIVE] KEYWORDS=(COMMENT,comment)
修改hive-site.xml的配置参数
<property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:dm://HIVE?dmsvcconf=/opt/hive/conf/dm_svc.conf</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>dm.jdbc.driver.DmDriver</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>hive</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>hdd123456</value> </property>
其中jdbc:dm://HIVE?dmsvcconf=/opt/hive/conf/dm_svc.conf 中的HIVE 指的是dm_svc.conf中HIVE=(172.16.104.165:5236)
进行元数据初始化
cd $HIVE_HOME ./bin/schematool -dbType dm -initSchema
出现如下提示,即元数据库初始化完成

3、启动hive
cd $HIVE_HOME #开启debug。启动metastore sudo -u hive /opt/hive/bin/hive --service metastore --hiveconf hive.root.logger=DEBUG,console #启动hive server2 sudo -u hive /opt/hive/bin/hive --service hiveserver2
通过beeline进行连接验证