Atlas架构与原理
一、总体架构
Atlas 是一个可伸缩且功能丰富的数据管理系统,深度集成了 Hadoop 大数据组件。简单理解就是一个 跟 Hadoop 关系紧密的,可以用来做元数据管理的一个系统,整个结构图如下所示:
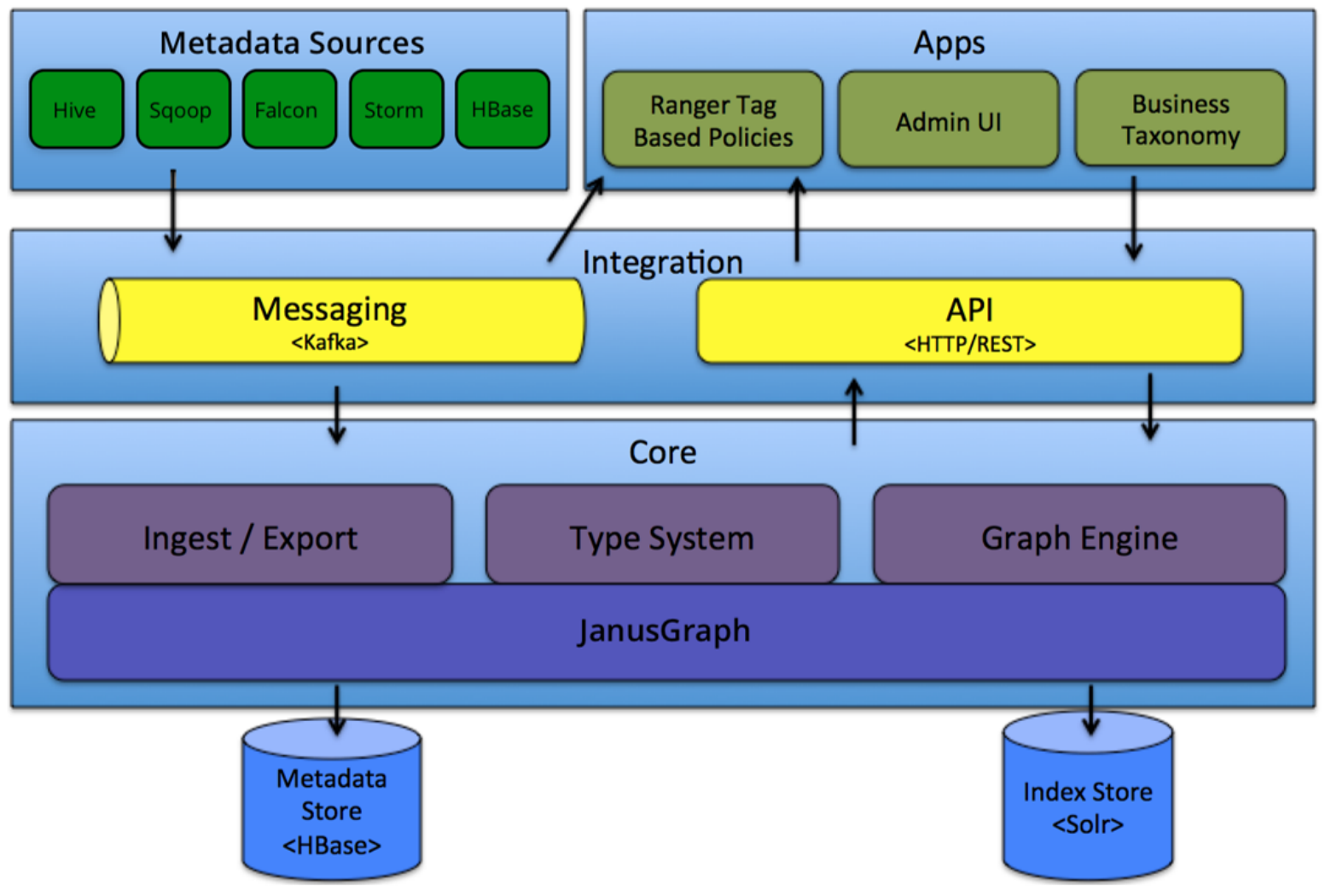
Atlas可以分为以下几层:
1. Core:Atlas 功能核心的组件(提供元数据摄取与导出、类型系统、元数据存储索引查 询等核心功能)
2. Integration:Atlas对外集成的模块(外部组件的元数据通过该模块把元数据交给Atlas来管 理),也就是说管理外部元数据的插件都得跟该模块交互。
3. Metadata source:Atlas支持的元数据数据源,以插件形式提供
4. Applications:Atlas的上层应用,可以用来查询由 Atlas 管理的元数据类型和对象
二、组件说明
1. Core核心层
(1)Type System
Atlas 允许用户为他们想要管理的元数据对象定义一个模型。该模型由称为 "types" 的定义组 成。"types" 的 实例被称为 "entities" 表示被管理的实际元数据对象。类型系统是一个组件,允许用户 定义和管理类型(types)和实体(entities)。由 Atlas 管理的所有元数据对象(例如Hive表)都使用 类型进行建模,并表示为实体。 简单理解:元数据在Atlas内部被抽象为:模型=类型-->实体来表示。
(2)Ingest/Export(导入/导出)
Ingest 组件允许将元数据添加到 Atlas。类似地,Export 组件将Atlas 检测到的元数据更改公开为事 件,消费者可以使用这些更改事件来实时响应元数据表更。
(3)Graph Engine(图计算引擎) 在内部,Atlas使用图模型来持久化和管理元数据对象。图模型提供了极大的灵活性,并可以有效处理元 数据对象之间的丰富关系。 图引擎组件负责在Atlas类型系统的类型和实体以及基础图持久性模型之间 进行转换。 除了管理图形对象之外,图形引擎还为元数据对象创建适当的索引,以便可以高效地搜索它 们。 Atlas使用JanusGraph存储元数据对象。 简单理解:元数据采用图模型来表示(传统关系模型无法表示),并存储在图存储中 (JanusGraph),Graph Engine(图引擎)是图模型(类/对象)和图存储(数据库)之间的桥梁。
(4)JanusGraph(图存储引擎/图数据库) 在Atlas 1.0之前采用Titan作为图存储引擎,从Atlas 1.0开始采用JanusGraph作为图存储引擎。 JanusGraph底层又分为两块: 1. Metadata Store:采用HBase存储Atlas管理的元数据。 2. Index Store:采用Solr来存储元数据的索引,便于高效搜索。
2. integration层
Integration提供了两种元数据集成方式供外部组件把元数据接入Atlas:
(1)API Atlas 的所有功能都可以通过 REST API 提供给最终用户,允许创建,更新和删除类型和实体。它也是查 询和发现通过 Atlas 管理的类型和实体的主要方法。 (2)Messaging 除了 API 之外,用户还可以选择使用基于 Kafka 的消息接口与 Atlas 集成。这对于将元数据对象传输到 Atlas 以及从 Atlas获取元数据更改事件都非常有用。如果希望与 Atlas 更松散耦合的集成,且希望有更 好的可扩展性,可靠性等,消息传递接口是特别有用的。 Atlas 使用 Apache Kafka 作为消息队列。事件由钩子(hook)和 Atlas 写到不同的 Kafka 主题:
a. ATLAS_HOOK: 来自各个组件的Hook的元数据通知事件通过写入到名为 ATLAS_HOOK 的 Kafka topic 发送到 Atlas(消息入口:采集外部元数据)
b. ATLAS_ENTITIES:从 Atlas 到其他集成组件(如Ranger)的事件写入到名为 ATLAS_ENTITIES 的 Kafka topic(消息出口:暴露元数据变更事件给外部组件)
3. Metadata source 层
Metadata source是一堆元数据采集的插件的统称,通过他们就可以管理外部的各种元数据了。
Atlas支持与许多现成的元数据源集成,将来还将添加更多集成。 当前Atlas支持从以下来源提取和管理 元数据: HBase Hive Sqoop Storm Kafka
Atlas集成大数据组件的元数据源需要实现以下两点:
首先,需要基于atlas的类型系统定义能够表达大数据组件元数据对象的元数据模型
然后,需要提供hook组件去从大数据组件的元数据源中提取元数据对象,实时侦听元数据的变更 并反馈给Atlas(也可能是批处理);
4. Applications层
Atlas管理的元数据被各种应用程序使用,以满足许多治理场景。Applications就是Atlas提供的各种应 用,当然我们也可以在Atlas提供的REST API上开发自己的应用。Atlas目前提供的APP有:
Admin UI(管理界面) 此组件是一个基于Web的应用程序,允许数据管理员和科学家发现和注释元数据。 这里最重要的是搜 索界面和类似SQL的查询语言,可用于查询Atlas管理的元数据类型和对象。 Admin UI使用Atlas的REST API来构建其功能。
Ranger Tag Based Policies Apache Ranger是针对Hadoop生态系统的高级安全管理解决方案,与各种Hadoop组件广泛集成。 通 过与Atlas集成,Ranger使安全管理员可以定义元数据驱动的安全策略以进行有效的管理。 Ranger是 Atlas通知的元数据更改事件的使用者。
Business Taxonomy(业务分类界面) 从元数据源获取到 Atlas 的元数据对象主要是一种技术形式的元数据。为了增强可发现性和治理能力, Atlas 提供了一个业务分类界面,允许用户首先定义一组代表其业务域的业务术语,并将其与 Atlas 管 理的元数据实体相关联。Business Taxonomy是一个 Web 应用程序,目前是 Atlas Admin UI 的一部 分,并且使用 REST API 与 Atlas 集成。