Atlas集成Hive
1 集成原理

2 验证Hive元数据采集效果
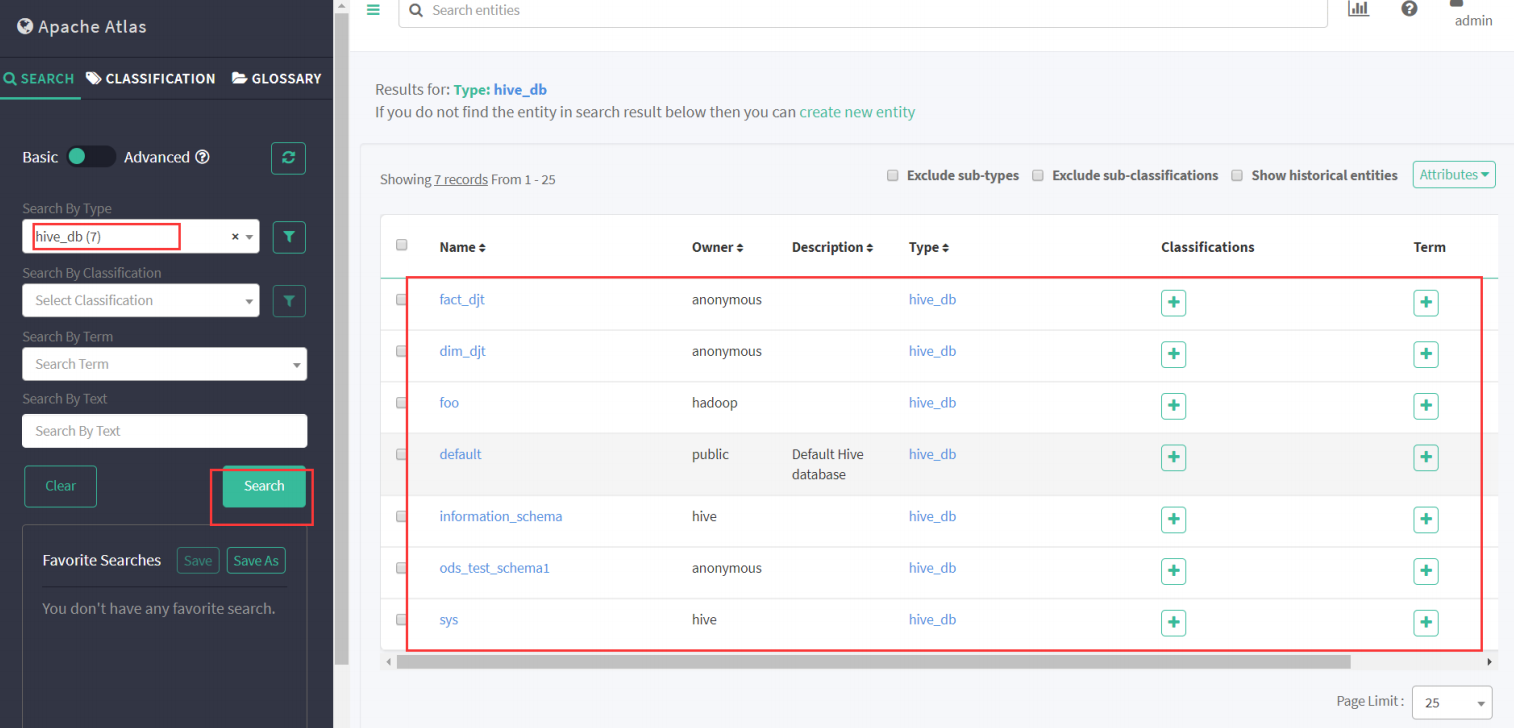
(1) 查看Atlas里是否有Hive元数据
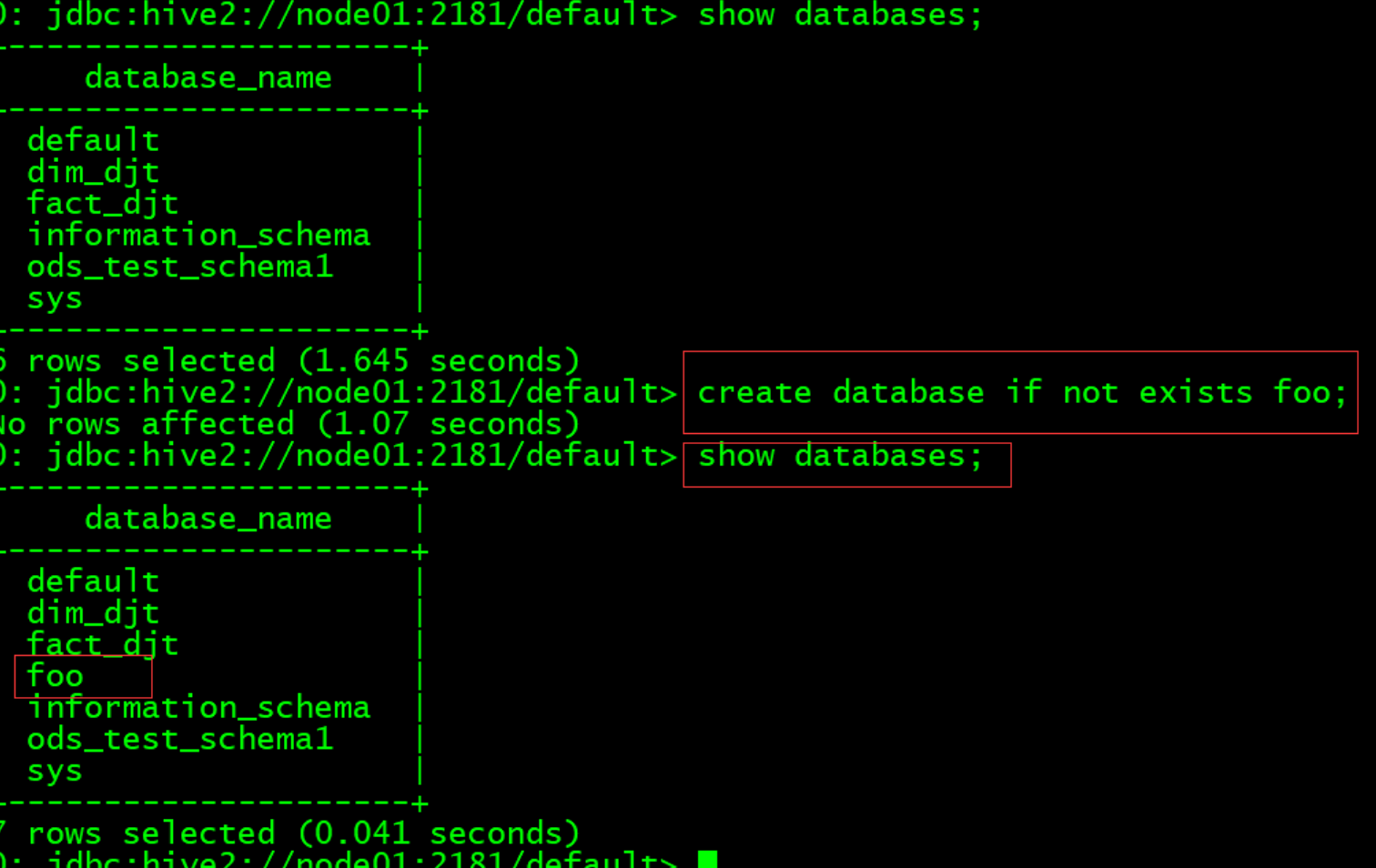
(2) 进入Hive创建一个库表
create database if not exists foo;
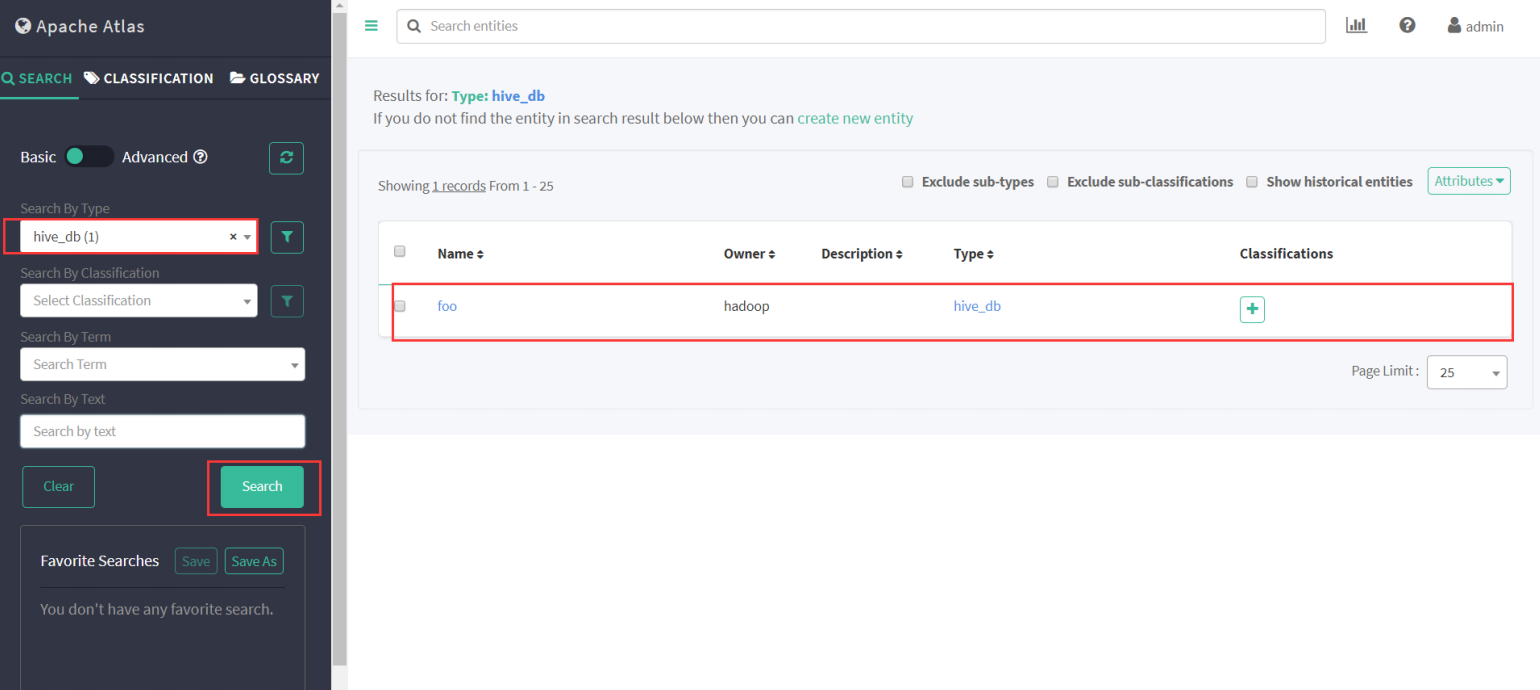
(3) 进入Atlas查看元数据
3 历史元数据处理
在上线Atlas之前Hive可能运行很久了,所以历史上的元数据无法触发hook,因此需要一个工具来做初 始化导入。 Apache Atlas提供了一个命令行脚本 import-hive.sh ,用于将Apache Hive数据库和表的元数据导入 Apache Atlas。该脚本可用于使用Apache Hive中的数据库/表初始化Apache Atlas。此脚本支持导入特 定表的元数据,特定数据库中的表或所有数据库和表。
Usage 1: <atlas package>/hook-bin/import-hive.sh
Usage 2: <atlas package>/hook-bin/import-hive.sh [-d <database regex> OR -- database <database regex>] [-t <table regex> OR --table <table regex>]
Usage 3: <atlas package>/hook-bin/import-hive.sh [-f <filename>]
File Format:
database1:tbl1
database1:tbl2
database2:tbl1
导入工具调用的是对应的Bridge:org.apache.atlas.hive.bridge.HiveMetaStoreBridge
(1) 执行导入脚本
任意找一台安装过Atlas client的节点,执行如下命令:
sudo su - atlas /usr/hdp/current/atlas-client/hook-bin/import-hive.sh
注意:一定要进入atlas用户,因为Atlas的Linux管理账户是atlas,其他账户下可能会报没有权限的错 误。 脚本执行过程中会要求输入Atlas的管理员账号/密码,看到如下信息就成功了
Hive Meta Data imported successfully!!!
(2) 查看元数据