
相关文章
MySQL优化器特性(六)表扫描成本计算
全表扫描成本使用optimizer_trace,或者使用explain format=tree, 或者explain format=json,可以查看查询的costmysql> exp...

MySQL 复制-有数据环境搭建异步复制
前言本 SOP 介绍的是已有数据的场景下如果部署主从复制,因为是生产环境而且有数据,我们就需要先将主库的数据同步到从库再建立复制关系,还需要根据数据量来选择更适合的备份工具。一、步骤归纳单实例安装:新...
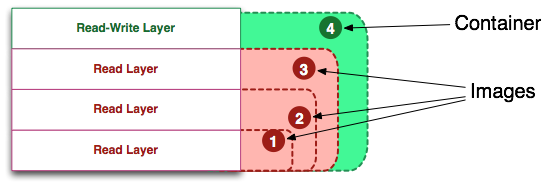
Dockerfile
一、什么是镜像?镜像可以看成是由多个镜像层叠加起来的一个文件系统(通过UnionFS与AUFS文件联合系统实现),镜像层也可以简单理解为一个基本的镜像,而每个镜像层之间通过指针的形式进行叠加。根据上图...
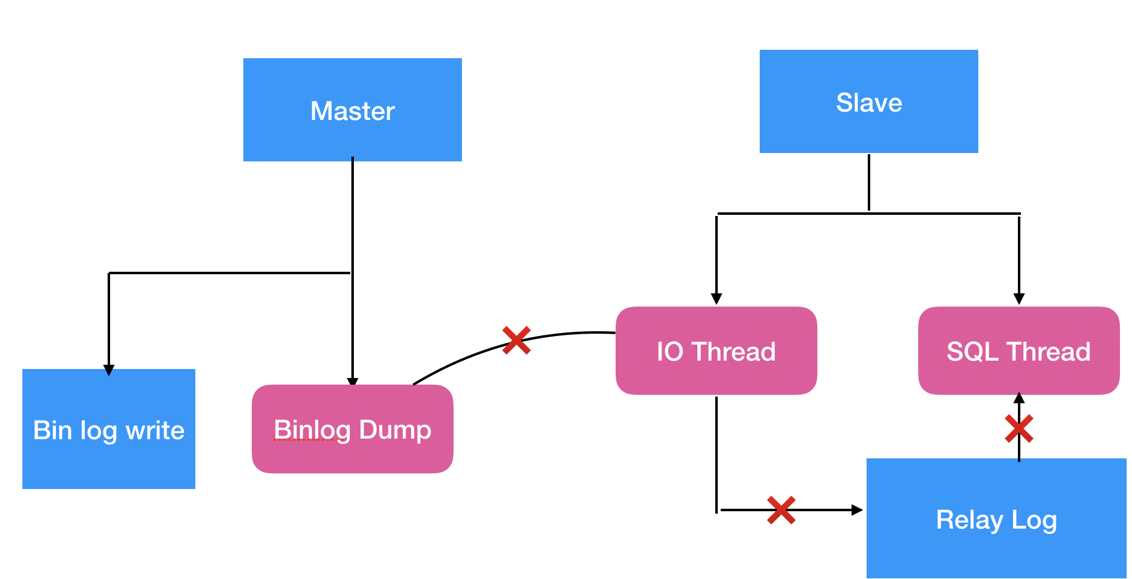
MySQL 复制延迟是如何计算的?
前言日常运维中总会收到 MySQL 备库延迟告警,一般数据库监控只读实例延迟都是采集 Seconds_Behind_Master 值,我们都知道它在某些场景下不可靠,今天一起探索 MySQL 是如何计...
dolphinscheduler单机部署
官网链接:https://dolphinscheduler.apache.org本次测试版本为:https://dolphinscheduler.apache.org/zh-cn/download/3...

Golang 垃圾回收
1、标记清除算法Golang 使用标记清除算法作为垃圾回收器的一部分。标记清除算法是一种常见的垃圾回收算法,它通过标记和清除未被引用的对象来回收内存空间。Golang 中,垃圾回收器会定期扫描堆空间,...
发表评论
