MySQL 复制延迟是如何计算的?
前言
日常运维中总会收到 MySQL 备库延迟告警,一般数据库监控只读实例延迟都是采集 Seconds_Behind_Master 值,我们都知道它在某些场景下不可靠,今天一起探索 MySQL 是如何计算复制延迟,可以帮助我们透过现象看到问题的本质。
一、MySQL 延迟计算方法
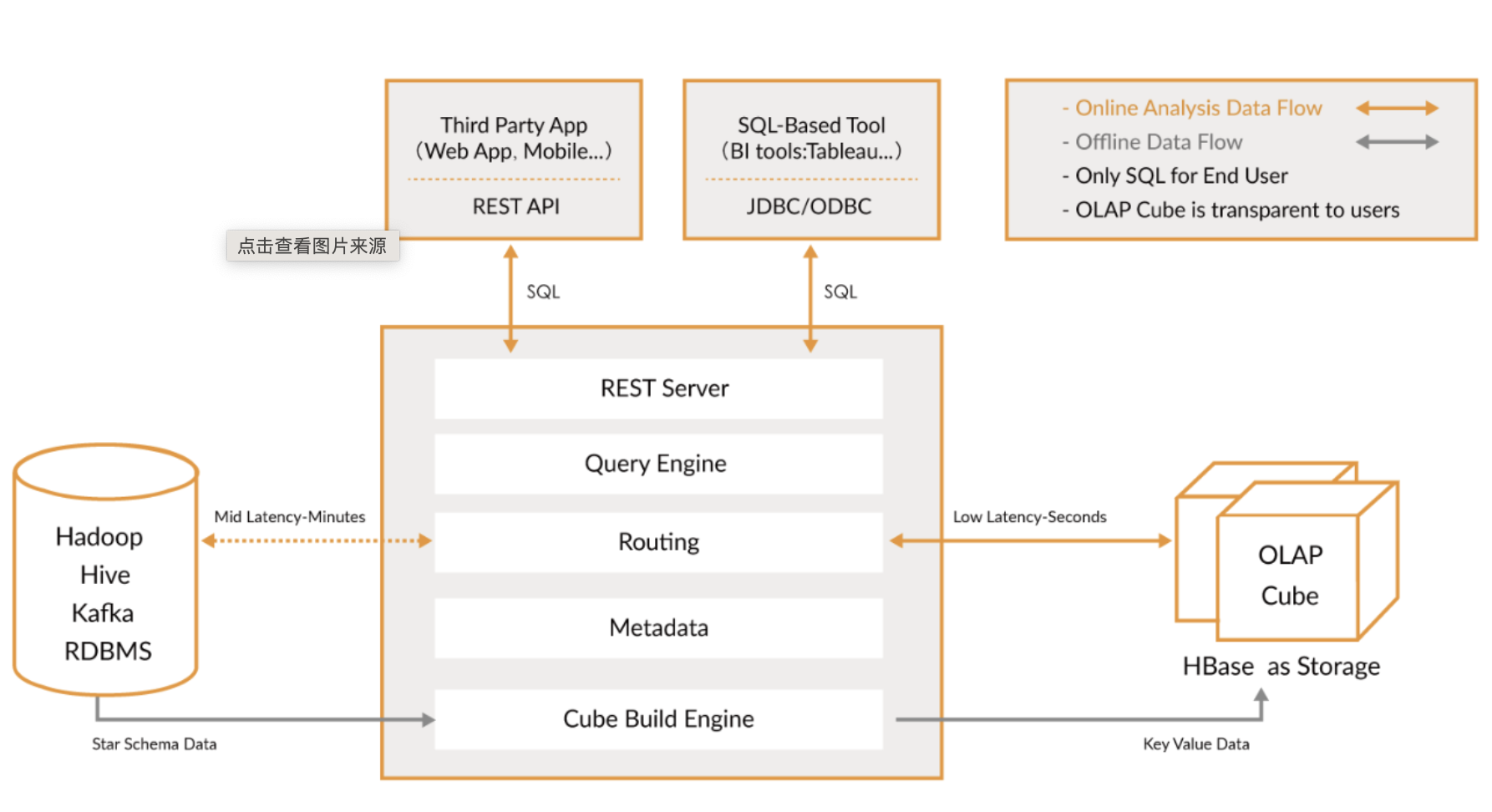
1. 主从复制中会导致延迟的环节
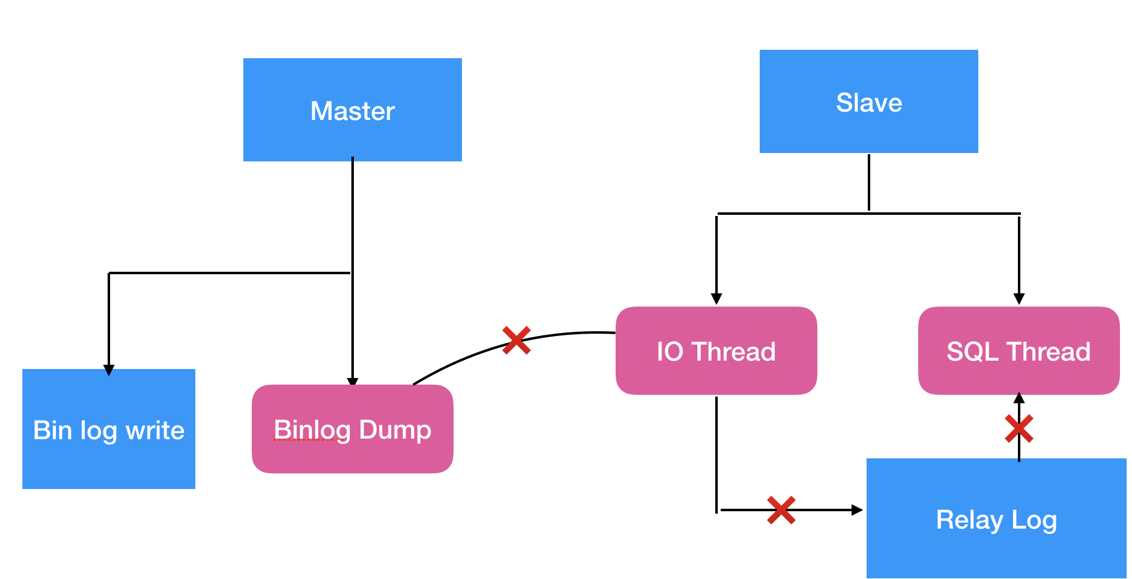
首先我们先过一遍 MySQL 复制过程,了解延迟可能会出现在哪个环节。请看上图,从图中我们可以了解到主从复制至少有三个环节是可能导致复制延迟的,比如 binlog dump 线程发送日志给从库 IO 线程网络环境不好造成延迟,从库 SQL 线程回放日志时,负载太高导致延迟,这种情况导致的延迟的现象 SBM 不会很高,但是一直持续降不下去,此时就要对从库做一个体检能否有 SQL 可以优化,扩容实例或者添加只读实例分担从库压力。
2. MySQL 源码中的计算方法
下方源码注释中提了主从延迟的计算公式: 源码中提到延迟复制的计算公式为:
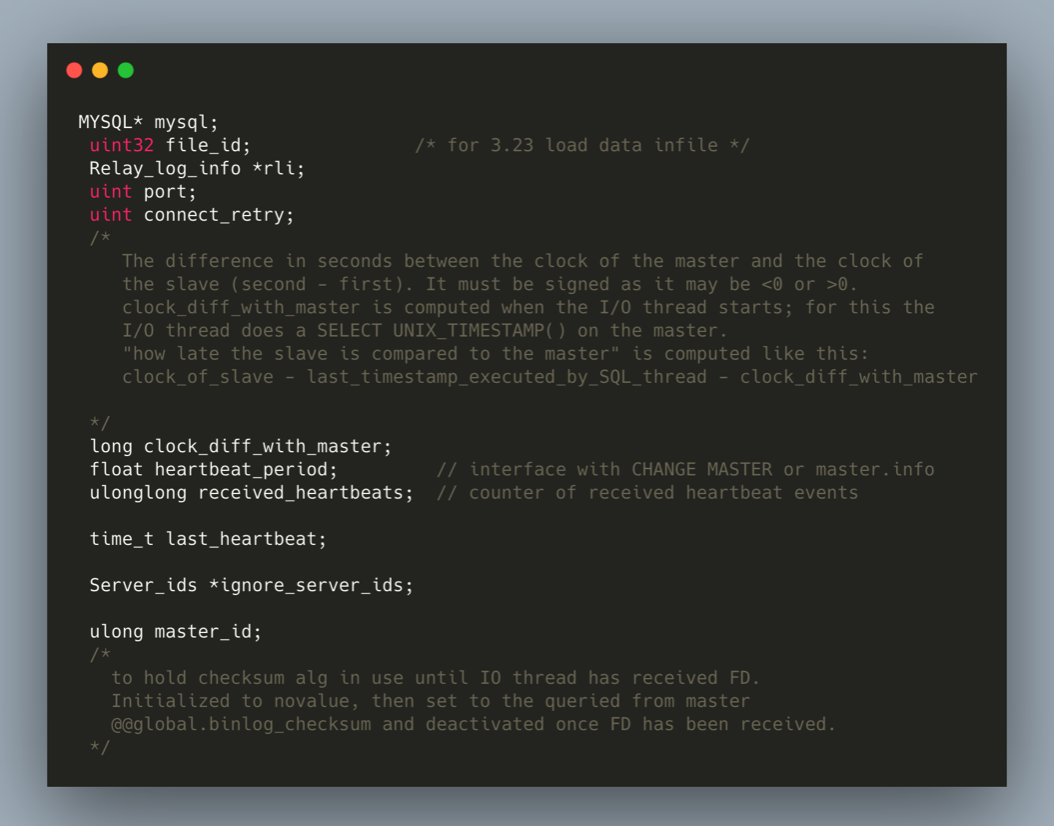
/*
从库当前系统的时间 - 从库 SQL 线程正在执行回放 Event 的时间戳 - 主从系统(主机)之间的时间差
*/
clock_of_slave - last_timestamp_executed_by_SQL_thread - clock_diff_with_masterlast_timestamp_executed_by_SQL_thread从库 SQL 线程正在回放事件的时间戳,在 binlog 每个事件的 Common Header 部分都会记录事务发生时间。clock_diff_with_master值是主从 Server 主机的时间差,在从库 IO_thread 启动时会重新计算该值,后面使用时直接复用计算结果,相当于校准值保障主从 DateTime 是一致的。从公式中我们可以了解即使主从系统时间不一致 MySQL 也会计算出正确的延迟结果,在复制进行中,如果修改了系统时间会导致延迟误差,因为
clock_diff_with_master只会在 IO 线程启动时重新计算。当计算延迟为负数时则直接为零。
当从库两个线程都为 Yes 时,且 SQL 线程没有在工作的时候 Seconds_Behind_Master 直接判定为零。
当 SQL 线程重放所有的日志后 IO 线程关闭 Seconds_Behind_Master 无法计算直接为 Null。
下方是 MySQL计算主从延迟的源代码:

long time_diff= ((long)(time(0) - mi->rli->last_master_timestamp) - mi->clock_diff_with_master);
time(0) 指的就是本地时间; mi->rli->last_master_timestamp 从库当前正在回放 SQL event 的时间戳; mi->clock_diff_with_master 时间校准值,前面提到过;
貌似看起来没得问题,其实是有一下坑的,比如:
网络环境不是很好,既 IO_thread 的同步是瓶颈,而在 Slave 端来看 sql_thread 能够很快应用掉日志,而 SBM 等于 0 这就会产生一错觉,看起来是没有延迟的,其实已经产生较大延迟。
如果 1 分钟内产生大量的 binlog 如果此时以 timestamp 做计算延迟不会很大,但实际相差的日志量 2 G 也会导致误导。此时就需要根据 master - slave 日志量差异对比才能看出问题。
二、处理主从延迟思路
1. 避免大事务
上面我们已经了解到延迟的计算公式,当 SQL 线程重放一个大事务时,SQL 线程的时间戳当于暂停了,虽然一个大事务是由很多 event 组成,也有可能这些 event 的时间戳可能完全相同(row 模式下)SQL 线程要花费较长时间去应用掉,由 SBM 计算公式得出无论主库是否有数据写入,从库的复制延迟会持续增加。避免大事务 避免大事务 避免大事务 说三遍。
2. DDL 导致的延迟
比如 BI 只读库,当主库应用一个 DDL 操作,即使是一个非常小的 INSTANT 操作,此时 BI 库中可能有大查询在跑可能会堵塞这个 DDL 提交(执行完需要获取一次 X 锁,刚好被 SQL 占用)必须等待查询完才能提交,延迟就一直蹭蹭蹭往上涨..... 此时就需用先 Kill 掉相关查询即可。
3. 合理的架构
如果业务压力确实比较大,读库负载较高,无法快速应用掉主库的日志数据,此时就需要考虑扩展从库,分担压力。
4. 多线程复制
5.6 支持库级别的 SQL_thread 回放 5.7 的 WRITESET 支持事务不冲突情况下并行回放。如果你被延迟困扰,升级到 5.7 吧。
5. 增大从库 buffer pool
增大从库 innodb_buffer_pool 参数 innodb 可以缓存更多的数据,可以减少 IO 压力。