压测实操--nnbench压测hdfs_namenode负载方案
本次压测使用nnbench对namenode负载进行性能测试。nnbench生成很多与HDFS相关的请求,给NameNode施加较大的压力,这个测试能在HDFS上创建、读取、重命名和删除文件操作。
对应nnbench参数

参数列表 | |
-operation | create_write open_read rename delete |
-maps | mapper数 |
-reduces | reducer数 |
-startTime | 开始时间 |
-blockSize | block size |
-bytesToWrite | 文件写入字节数 单位为b |
-bytesPerChecksum | |
-numberOfFiles | 生成的文件数 |
-replicationFactorPerFile | 每个文件副本数 |
-baseDir | 根路径 |
-readFileAfterOpen |
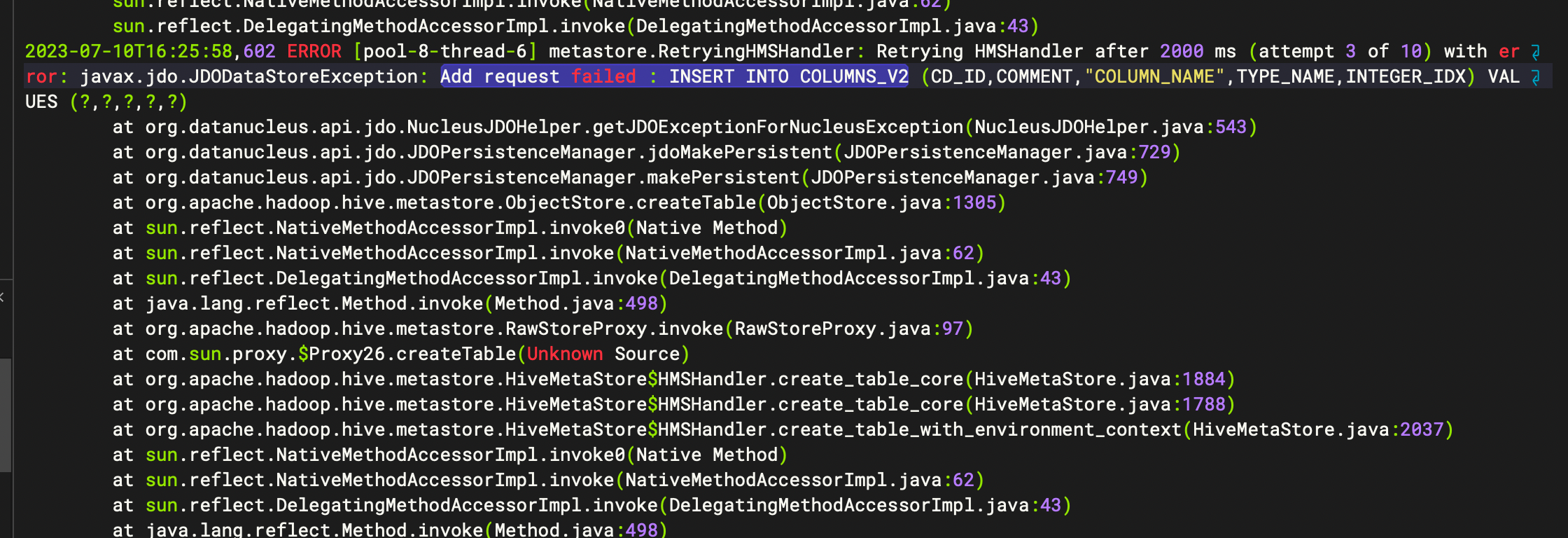
注意:如果集群开放了安全认证,需要提前认证通过后,进行压测。
步骤
一、先使用默认值进行压测
目前压测集群的namenode为1G
.png")
create_write操作
示例:测试map为100,reduce为5,创建10000个文件。(需要查看的指标仪表盘样例)
hadoop jar /usr/hdp/3.1.5.0-152/hadoop-mapreduce/hadoop-mapreduce-client-jobclient-3.1.1.3.1.5.0-152-tests.jar nnbench \ -operation create_write \ -maps 100 \ -reduces 5 \ -blockSize 1 \ -bytesToWrite 1024 \ -numberOfFiles 10000 \ -replicationFactorPerFile 3 \ -readFileAfterOpen true \ -baseDir /benchmarks/NNBench
.png")
.png")
.png")
.png")
hdfs指标
.png")
.png")
.png")
.png")
1、测试map为100,reduce为5,创建100w个文件。
hadoop jar /usr/hdp/3.1.5.0-152/hadoop-mapreduce/hadoop-mapreduce-client-jobclient-3.1.1.3.1.5.0-152-tests.jar nnbench \ -operation create_write \ -maps 100 \ -reduces 5 \ -blockSize 1 \ -bytesToWrite 1024 \ -numberOfFiles 1000000 \ -replicationFactorPerFile 3 \ -readFileAfterOpen true \ -baseDir /benchmarks/NNBench
2、测试map为100,reduce为5,创建500w个文件。
hadoop jar /usr/hdp/3.1.5.0-152/hadoop-mapreduce/hadoop-mapreduce-client-jobclient-3.1.1.3.1.5.0-152-tests.jar nnbench \ -operation create_write \ -maps 100 \ -reduces 5 \ -blockSize 1 \ -bytesToWrite 1024 \ -numberOfFiles 5000000 \ -replicationFactorPerFile 3 \ -readFileAfterOpen true \ -baseDir /benchmarks/NNBench
3、测试map为100,reduce为5,创建1000w个文件。
hadoop jar /usr/hdp/3.1.5.0-152/hadoop-mapreduce/hadoop-mapreduce-client-jobclient-3.1.1.3.1.5.0-152-tests.jar nnbench \ -operation create_write \ -maps 100 \ -reduces 5 \ -blockSize 1 \ -bytesToWrite 1024 \ -numberOfFiles 10000000 \ -replicationFactorPerFile 3 \ -readFileAfterOpen true \ -baseDir /benchmarks/NNBench
4、测试map为100,reduce为5,创建3000w个文件。
hadoop jar /usr/hdp/3.1.5.0-152/hadoop-mapreduce/hadoop-mapreduce-client-jobclient-3.1.1.3.1.5.0-152-tests.jar nnbench \ -operation create_write \ -maps 100 \ -reduces 5 \ -blockSize 1 \ -bytesToWrite 1024 \ -numberOfFiles 30000000 \ -replicationFactorPerFile 3 \ -readFileAfterOpen true \ -baseDir /benchmarks/NNBench
此时有节点内存已经达到93.2%,节点挂掉的风险比较大,增加namenode内存再继续进行压测
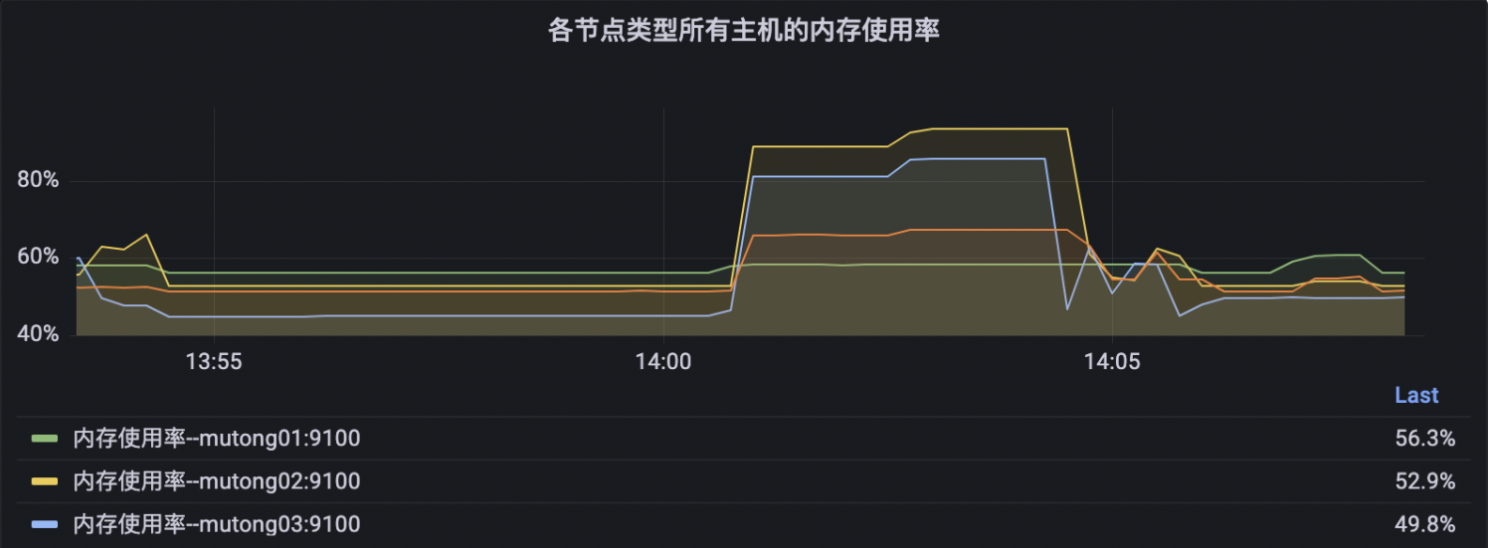
openread操作
1、测试map为100,reduce为5,创建100w个文件。
hadoop jar /usr/hdp/3.1.5.0-152/hadoop-mapreduce/hadoop-mapreduce-client-jobclient-3.1.1.3.1.5.0-152-tests.jar nnbench \ -operation open_read \ -maps 100 \ -reduces 5 \ -blockSize 1 \ -bytesToWrite 1024 \ -numberOfFiles 1000000 \ -replicationFactorPerFile 3 \ -readFileAfterOpen true \ -baseDir /benchmarks/NNBench
具体指标见示例中的仪表盘截图。
2、测试map为100,reduce为5,创建500w个文件。
hadoop jar /usr/hdp/3.1.5.0-152/hadoop-mapreduce/hadoop-mapreduce-client-jobclient-3.1.1.3.1.5.0-152-tests.jar nnbench \ -operation open_read \ -maps 100 \ -reduces 5 \ -blockSize 1 \ -bytesToWrite 1024 \ -numberOfFiles 5000000 \ -replicationFactorPerFile 3 \ -readFileAfterOpen true \ -baseDir /benchmarks/NNBench
3、测试map为100,reduce为5,创建1000w个文件。
hadoop jar /usr/hdp/3.1.5.0-152/hadoop-mapreduce/hadoop-mapreduce-client-jobclient-3.1.1.3.1.5.0-152-tests.jar nnbench \ -operation open_read \ -maps 100 \ -reduces 5 \ -blockSize 1 \ -bytesToWrite 1024 \ -numberOfFiles 10000000 \ -replicationFactorPerFile 3 \ -readFileAfterOpen true \ -baseDir /benchmarks/NNBench
4、测试map为100,reduce为5,创建3000w个文件。
hadoop jar /usr/hdp/3.1.5.0-152/hadoop-mapreduce/hadoop-mapreduce-client-jobclient-3.1.1.3.1.5.0-152-tests.jar nnbench \ -operation open_read \ -maps 100 \ -reduces 5 \ -blockSize 1 \ -bytesToWrite 1024 \ -numberOfFiles 30000000 \ -replicationFactorPerFile 3 \ -readFileAfterOpen true \ -baseDir /benchmarks/NNBench
rename操作
1、测试map为100,reduce为5,创建100w个文件。
hadoop jar /usr/hdp/3.1.5.0-152/hadoop-mapreduce/hadoop-mapreduce-client-jobclient-3.1.1.3.1.5.0-152-tests.jar nnbench \ -operation rename \ -maps 100 \ -reduces 5 \ -blockSize 1 \ -bytesToWrite 1024 \ -numberOfFiles 1000000 \ -replicationFactorPerFile 3 \ -readFileAfterOpen true \ -baseDir /benchmarks/NNBench
2、测试map为100,reduce为5,创建500w个文件。
hadoop jar /usr/hdp/3.1.5.0-152/hadoop-mapreduce/hadoop-mapreduce-client-jobclient-3.1.1.3.1.5.0-152-tests.jar nnbench \ -operation rename \ -maps 100 \ -reduces 5 \ -blockSize 1 \ -bytesToWrite 1024 \ -numberOfFiles 5000000 \ -replicationFactorPerFile 3 \ -readFileAfterOpen true \ -baseDir /benchmarks/NNBench
3、测试map为100,reduce为5,创建1000w个文件。
hadoop jar /usr/hdp/3.1.5.0-152/hadoop-mapreduce/hadoop-mapreduce-client-jobclient-3.1.1.3.1.5.0-152-tests.jar nnbench \ -operation rename \ -maps 100 \ -reduces 5 \ -blockSize 1 \ -bytesToWrite 1024 \ -numberOfFiles 10000000 \ -replicationFactorPerFile 3 \ -readFileAfterOpen true \ -baseDir /benchmarks/NNBench
4、测试map为100,reduce为5,创建3000w个文件。
hadoop jar /usr/hdp/3.1.5.0-152/hadoop-mapreduce/hadoop-mapreduce-client-jobclient-3.1.1.3.1.5.0-152-tests.jar nnbench \ -operation rename \ -maps 100 \ -reduces 5 \ -blockSize 1 \ -bytesToWrite 1024 \ -numberOfFiles 30000000 \ -replicationFactorPerFile 3 \ -readFileAfterOpen true \ -baseDir /benchmarks/NNBench
delete操作
1、测试map为100,reduce为5,创建100w个文件。
hadoop jar /usr/hdp/3.1.5.0-152/hadoop-mapreduce/hadoop-mapreduce-client-jobclient-3.1.1.3.1.5.0-152-tests.jar nnbench \ -operation delete \ -maps 100 \ -reduces 5 \ -blockSize 1 \ -bytesToWrite 1024 \ -numberOfFiles 1000000 \ -replicationFactorPerFile 3 \ -readFileAfterOpen true \ -baseDir /benchmarks/NNBench
2、测试map为100,reduce为5,创建500w个文件。
hadoop jar /usr/hdp/3.1.5.0-152/hadoop-mapreduce/hadoop-mapreduce-client-jobclient-3.1.1.3.1.5.0-152-tests.jar nnbench \ -operation delete \ -maps 100 \ -reduces 5 \ -blockSize 1 \ -bytesToWrite 1024 \ -numberOfFiles 5000000 \ -replicationFactorPerFile 3 \ -readFileAfterOpen true \ -baseDir /benchmarks/NNBench
3、测试map为100,reduce为5,创建1000w个文件。
hadoop jar /usr/hdp/3.1.5.0-152/hadoop-mapreduce/hadoop-mapreduce-client-jobclient-3.1.1.3.1.5.0-152-tests.jar nnbench \ -operation delete \ -maps 100 \ -reduces 5 \ -blockSize 1 \ -bytesToWrite 1024 \ -numberOfFiles 10000000 \ -replicationFactorPerFile 3 \ -readFileAfterOpen true \ -baseDir /benchmarks/NNBench
4、测试map为100,reduce为5,创建3000w个文件。
hadoop jar /usr/hdp/3.1.5.0-152/hadoop-mapreduce/hadoop-mapreduce-client-jobclient-3.1.1.3.1.5.0-152-tests.jar nnbench \ -operation delete \ -maps 100 \ -reduces 5 \ -blockSize 1 \ -bytesToWrite 1024 \ -numberOfFiles 30000000 \ -replicationFactorPerFile 3 \ -readFileAfterOpen true \ -baseDir /benchmarks/NNBench
二、增加资源配置进行压测
例如增大namenode内存为2G,依次测试create_write/openerad/rename/delete操作,在内存或者cpu负载达到瓶颈时,结束压测。
三、总结
在集群硬件资源能给到最大条件下(比如namenode最大能给到8G,再大就会影响其他组件的内存使用),压测出此时的并行文件数为该集群中能达到的最大值,执行任务过程中不要超过最大值,并且建议根据该值设置任务运行并行文件阈值进行控制。也可以对每次运行命令的结果tps进行整理形成曲线图,观察不同变量下tps的趋势。
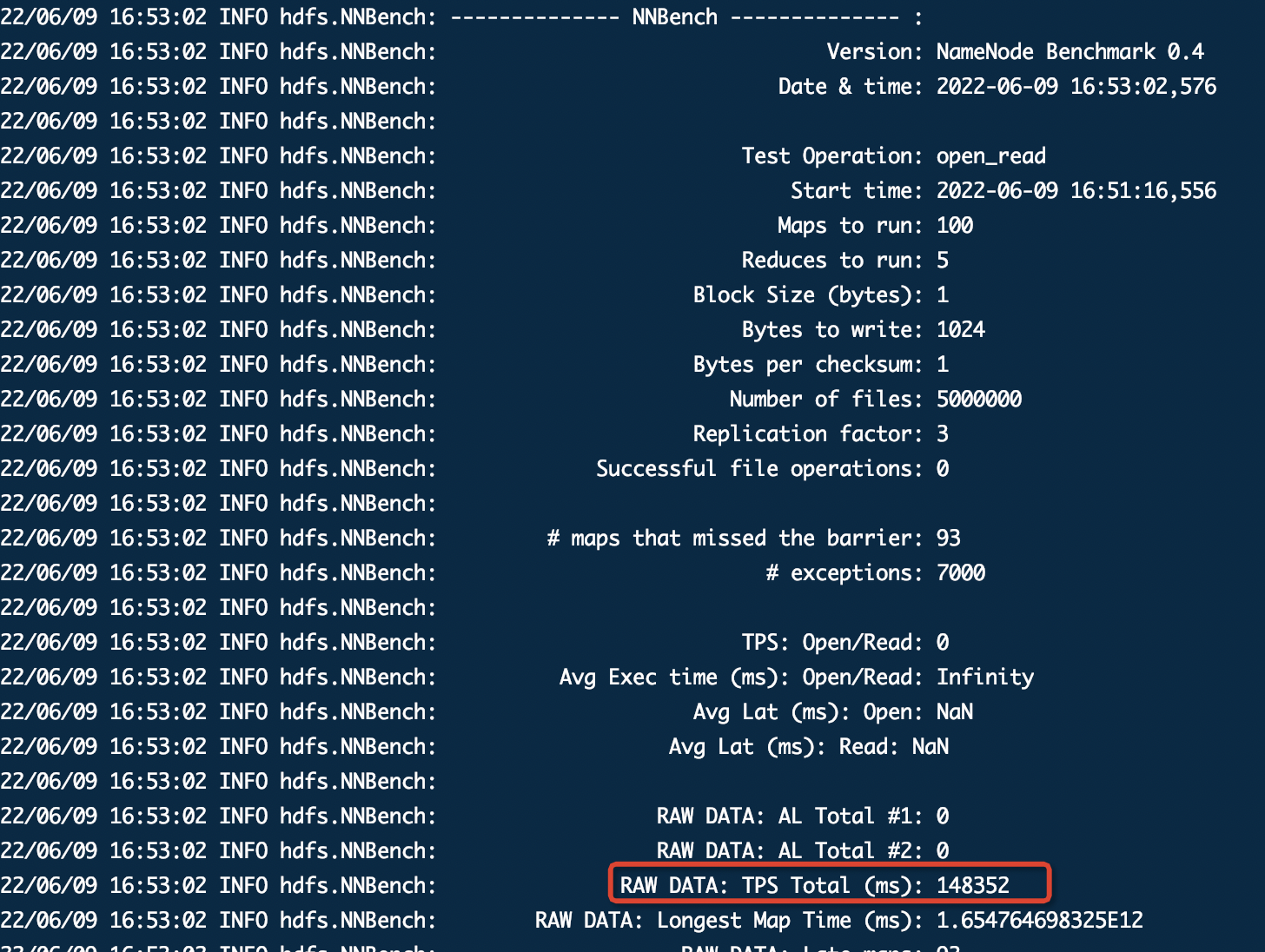
趋势图样例
.png")