Mac安装Hadoop文档-保姆级操作(二)
配置hadoop
进入hadoop的目录:
cd /opt/homebrew/Cellar/hadoop/3.3.6/libexec/etc/hadoop
修改core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:8020</value>
</property>
<!--用来指定hadoop运行时产生文件的存放目录 自己创建-->
<property>
<name>hadoop.tmp.dir</name>
<value>file:/opt/homebrew/Cellar/hadoop/3.3.6/tmp</value>
</property>
</configuration>
修改hdfs-site.xml,配置namenode和datanode
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!--不是root用户也可以写文件到hdfs-->
<property>
<name>dfs.permissions</name>
<value>false</value> <!--关闭防火墙-->
</property>
<!--把路径换成本地的name坐在位置-->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/homebrew/Cellar/hadoop/3.3.6/tmp/dfs/name</value>
</property>
<!--在本地新建一个存放hadoop数据的文件夹,然后将路径在这里配置一下-->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/homebrew/Cellar/hadoop/3.3.6/tmp/dfs/data</value>
</property>
</configuration>
修改 mapred-site.xml
<configuration>
<property>
<!--指定mapreduce运行在yarn上-->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>localhost:9010</value>
</property>
<!-- 新添加 -->
<!-- 下面的路径就是你hadoop distribution directory -->
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/opt/homebrew/Cellar/hadoop/3.3.6/libexec</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/opt/homebrew/Cellar/hadoop/3.3.6/libexec</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/opt/homebrew/Cellar/hadoop/3.3.6/libexec</value>
</property>
</configuration>
修改yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>localhost:9000</value>
</property>
<property>
<name>yarn.scheduler.capacity.maximum-am-resource-percent</name>
<value>100</value>
</property>
</configuration>
创建数据目录
mkdir -p /opt/homebrew/Cellar/hadoop/3.3.6/tmp/dfs/name
mkdir -p /opt/homebrew/Cellar/hadoop/3.3.6/tmp/dfs/data
启动Hadoop并验证
首先格式化namenode
hdfs namenode -format
启动Hadoop
cd /opt/homebrew/Cellar/hadoop/3.3.6/libexec/sbin
./start-dfs.sh
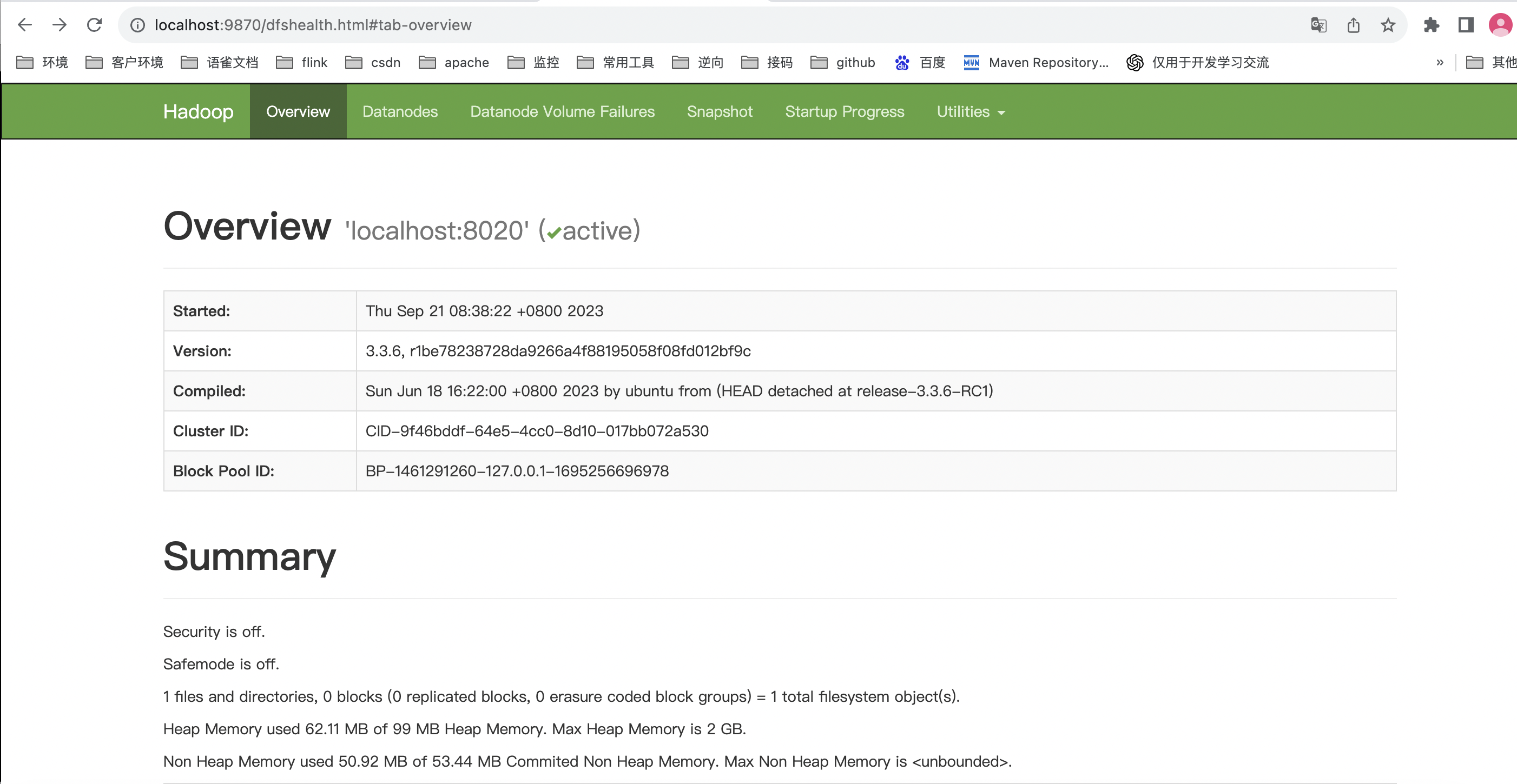
HDFS界面浏览器输入
http://localhost:9870/
出现以下界面就说明成功了:
启动yarn服务
cd /opt/homebrew/Cellar/hadoop/3.3.6/libexec/sbin
./start-yarn.sh
Yarn界面浏览器输入
http://localhost:8088/