Mac安装Hadoop文档-保姆级操作(一)
首先配置ssh环境
在Mac下如果想使用Hadoop,必须要配置ssh环境, 如果不执行这一步,后面启动hadoop时会出现Connection refused连接被拒绝的错误。
首先终端命令框输入:
ssh localhost
报错 Connection refused按照如下操作
表示当前用户没有权限,更改设置如下:进入系统偏好设置 --> 共享 --> 勾选远程登录->勾选所有用户,如下图:
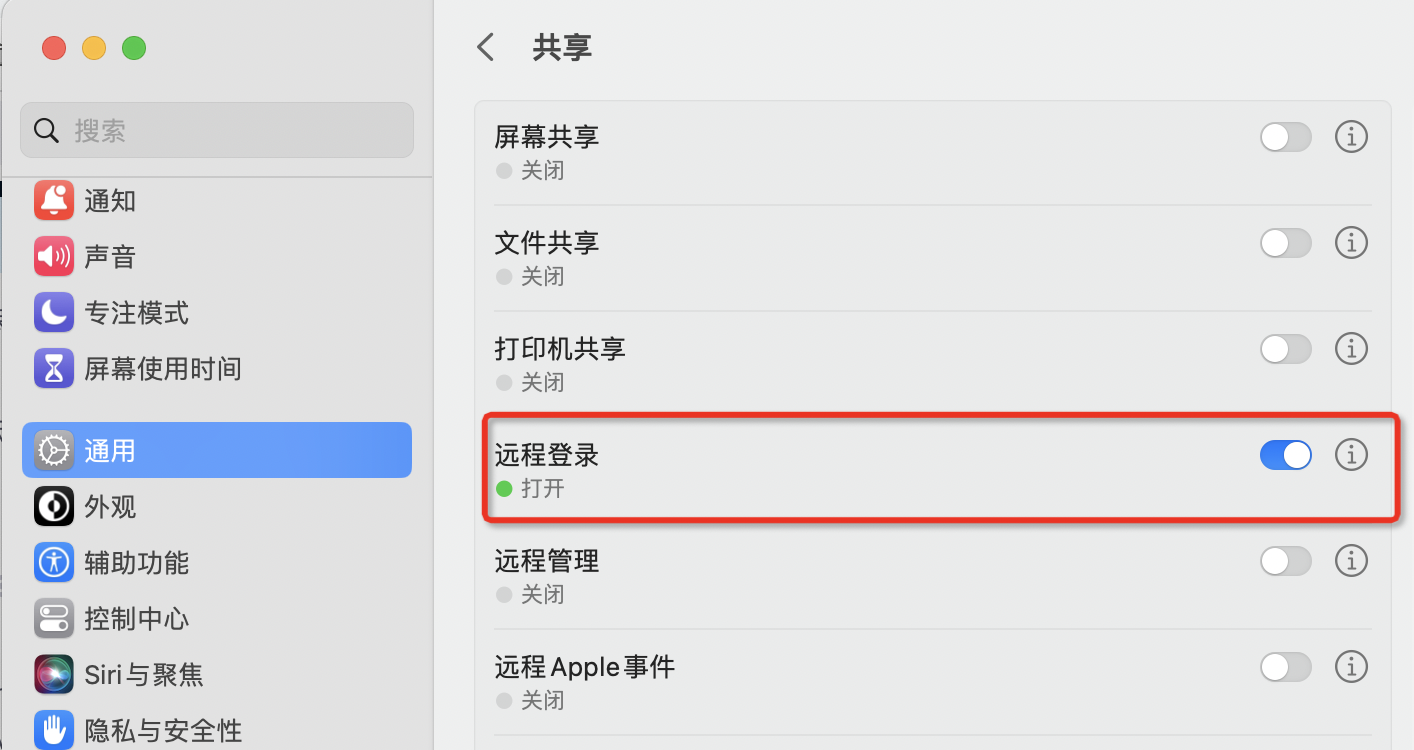
再次输入ssh localhost会提示输入密码,这个时候要重新配置一下ssh免密登录。
进入ssh的目录:
cd ~/.ssh
进行ls操作
会看到~/.ssh目录下有两个文件:
①私钥:id_rsa
②公钥:id_rsa.pub
将id_rsa.pub中的内容拷贝到 authorized_keys中:
cat id_rsa.pub >> authorized_keys
安装与配置Hadoop
使用Homebrew安装Hadoop-没有安装Homebrew先安装在终端执行
/bin/zsh -c "$(curl -fsSL https://gitee.com/cunkai/HomebrewCN/raw/master/Homebrew.sh)"
点击回车,输入开机密码即可安装,此过程比较慢,请耐心等待,下载源按需自选。
输入brew -v测试一下安装是否成功
brew -v
配置环境变量
vim ~/.bashrc
export JAVA_HOME="/Library/Java/JavaVirtualMachines/jdk-11.jdk/Contents/Home"
export PATH="$PATH:$JAVA_HOME/bin"
export HADOOP_HOME="/opt/homebrew/Cellar/hadoop/3.3.6/libexec"
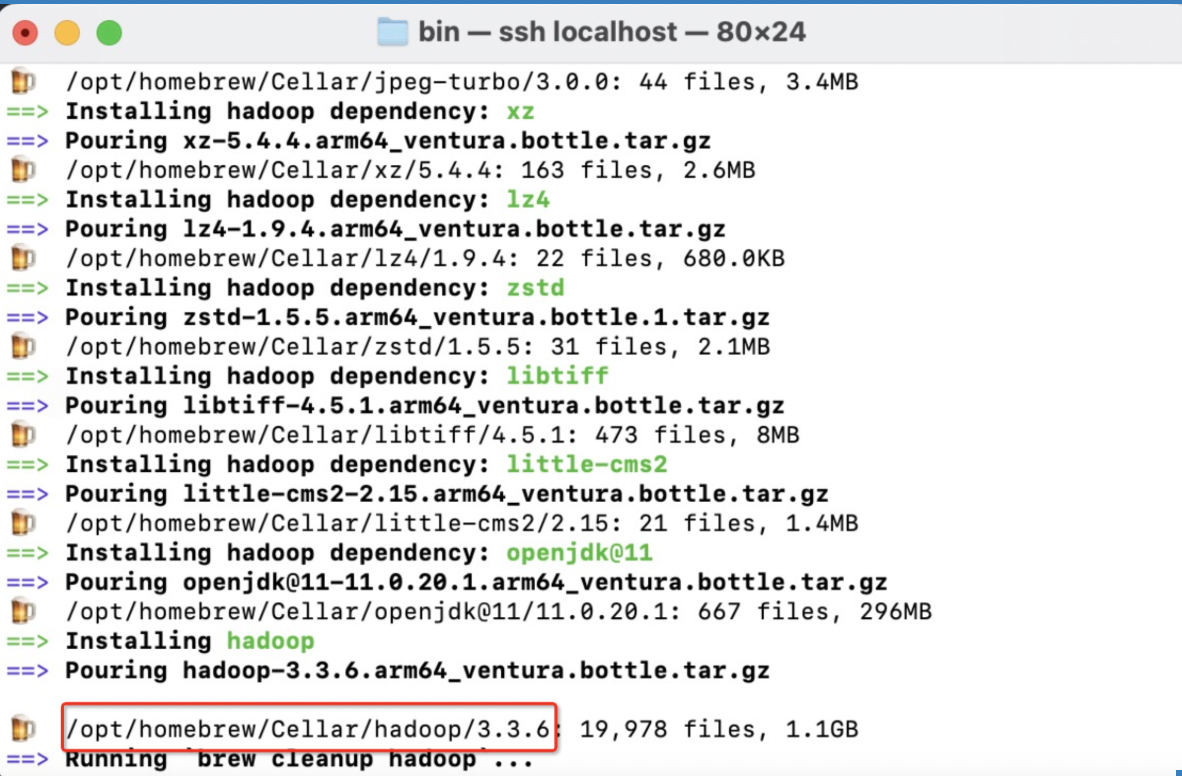
安装Hadoop
使用brew命令安装(这里没有指定版本,安装的是最新版的hadoop)
brew install hadoop
如图 完成后会显示安装目录以及安装的版本