CDN下载文件报错
一、问题现象
通过域名下载文件,下载到100M左右的时候,会提示下载错误,无法继续下载。
二、解决思路
业务链路:域名解析到cdn---slb--后端服务器。首先需要判断问题出在哪一层,再看这一层是否有什么配置导致下载错误。
1.slb ip 未开启访问控制策略,使用slb ip进行下载测试,可以下载成功。说明slb及之后的链路都是通的,问题出在cdn这一层。
2.定位到是cdn的问题后,根据以往的经验,怀疑可能是cdn的某个超时时间配置的过短导致下载失败。
3.排查后发现cdn超时时间合理,问题在cdn产品及nginx策略配置
三、解决步骤
1.分析访问域名的返回结果
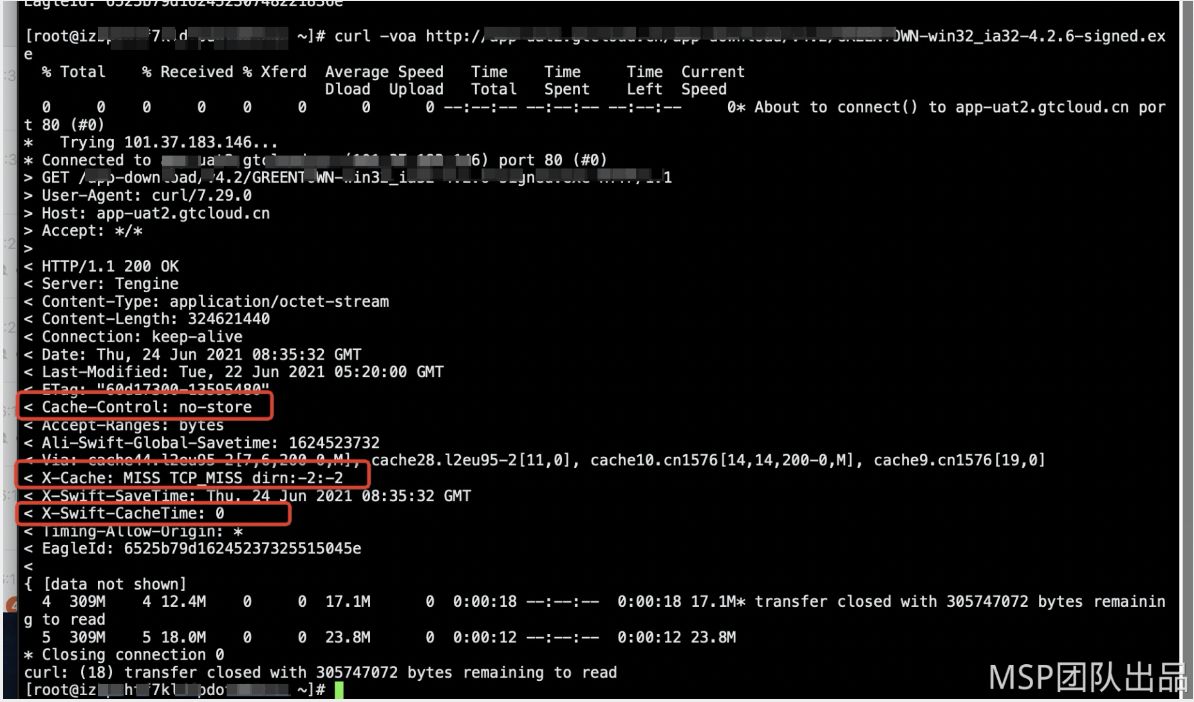
从Response Headers分析可以得到以下几个信息:
X-Cache: MISS TCP_MISS dirn:-2:-2表示这是一个MISS的请求,是回源的。
X-Swift-CacheTime: 0表示这个请求是无法缓存到CDN上的,每次都需要回源。
Cache-Control: public, max-age=0表示这里源站响应了max-age=0,是导致CDN无法缓存的原因。
2.问题原因
这个是产品层面的一个限制,对于超过100MB的文件,如果源站响应了Cache-Control为max-age=0、no-cache等不缓存的策略,将导致CDN无法缓存,这类请求会被CDN的Swift缓存组件断开。这主要是因为如果大文件请求不执行缓存,那么每次都需要回源,相当于CDN没有起到加速效果,而且对于CDN的回源带宽以及源站的性能都有影响。
3.解决方案
源站删除不缓存的Cache-Control头,支持CDN可以缓存此类文件。同时,对于大文件,如果源站支持Range,建议CDN层面开启Range回源功能。
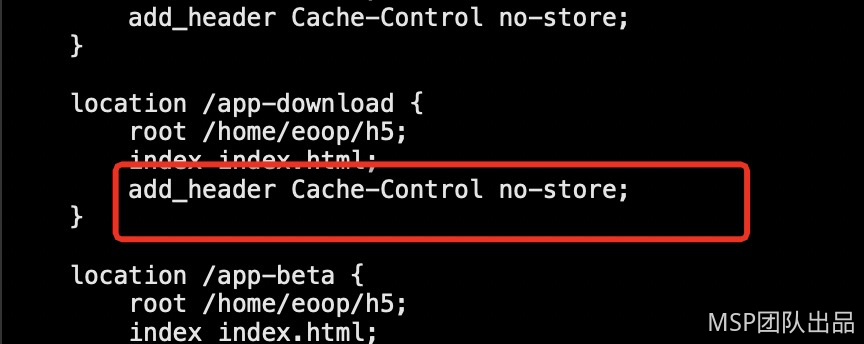
在nginx配置中加入如下内容:
etag on;
add_header Last-Modified “”;
add_header Cache-Control max-age=86400;
重启nginx后问题解决