大数据集群监控配置操作指导(三)Flink监控开启jmx
官网的关于 flnk+prometheus的文章
https://flink.apache.org/features/2019/03/11/prometheus-monitoring.html
prometheus 和 pushgateway 都是同一个网站下载:
https://prometheus.io/download/
利用 PrometheusReporter 获取监控数据
导包
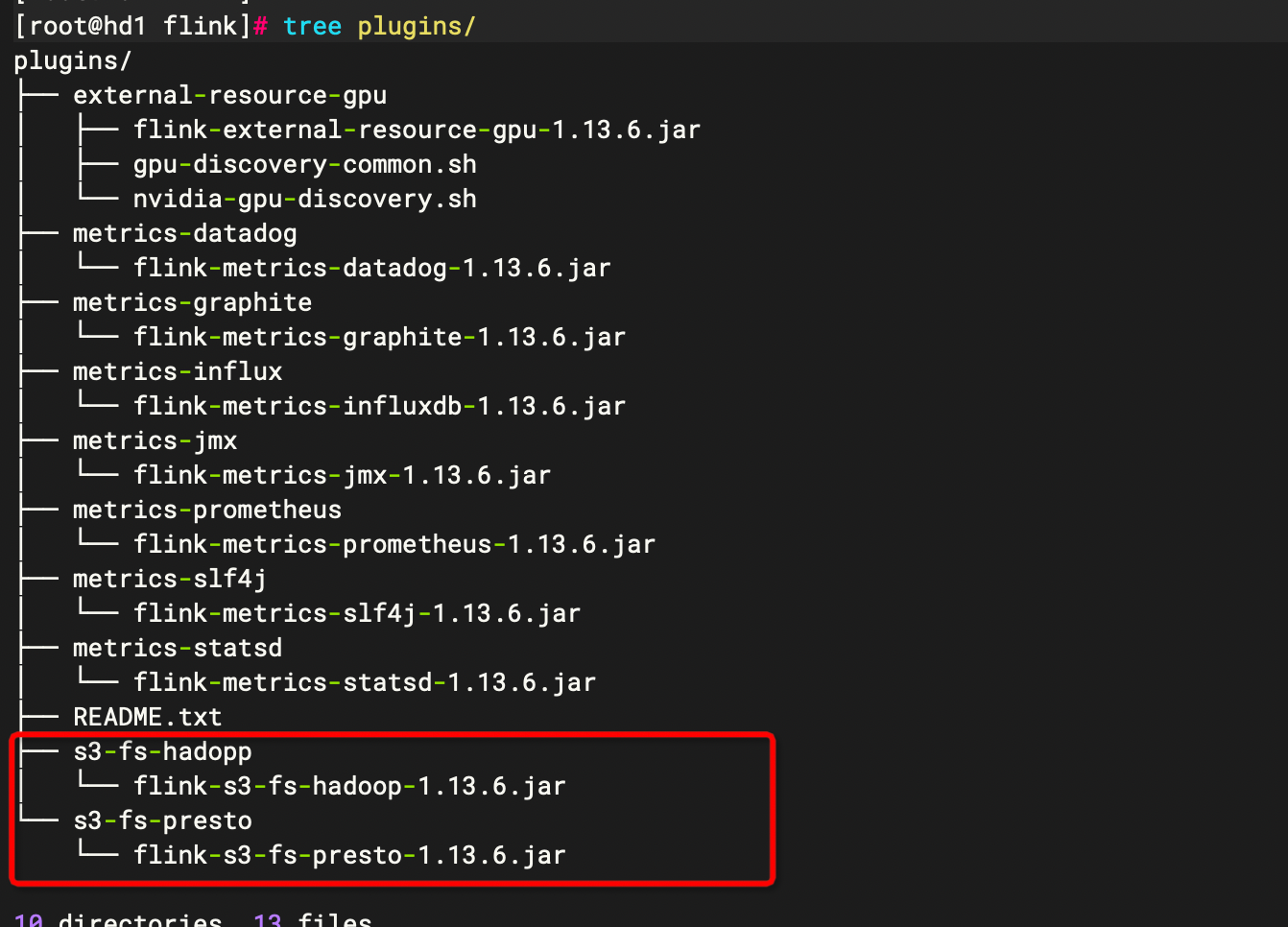
要使用该 reporter 的话,需要将 opt 目录下的 flink-metrics-prometheus-1.9.0.jar 依赖放到 lib 目录下
cp opt/flink-metrics-prometheus_2.12-1.13.6.jar lib/
可以配置的参数有:
port:该参数为可选项,Prometheus 监听的端口,默认是 9249,和上面使用 JMXReporter 一样,如果是在一台服务器上既运行了 JobManager,又运行了 TaskManager,则使用端口范围,比如 9249-9259。
filterLabelValueCharacters:该参数为可选项,表示指定是否过滤标签值字符,如果开启,则删除所有不匹配 [a-zA-Z0-9:_] 的字符,否则不会删除任何字符。
除了上面两个可选参数,另外一个参数是必须要在 flink-conf.yaml 中配置的,那就是 metrics reporter class。比如像下面这样配置:
metrics.reporter.prom.class: org.apache.flink.metrics.prometheus.PrometheusReporter
利用 PrometheusPushGatewayReporter 获取监控数据
PushGateway 是 Prometheus 生态中一个重要工具,使用它的原因主要是:
Prometheus 采用 pull 模式,可能由于 Prometheus 和其他 target 对象不在一个子网或者防火墙原因,导致 Prometheus 无法直接拉取各个 target 数据。
在监控业务数据的时候,需要将不同数据汇总, 由 Prometheus 统一收集。
那么使用 PrometheusPushGatewayReporter 的话,该 reporter 会定时将 metrics 数据推送到 PushGateway,然后再由 Prometheus 去拉取这些 metrics 数据。如果使用 PrometheusPushGatewayReporter 收集数据的话,也是需要将 opt 目录下的 flink-metrics-prometheus-1.9.0.jar 依赖放到 lib 目录下的,可配置的参数有:
deleteOnShutdown:默认值是 true,表示是否在关闭时从 PushGateway 删除指标。
filterLabelValueCharacters:默认值是 true,表示是否过滤标签值字符,如果开启,则不符合 [a-zA-Z0-9:_] 的字符都将被删除。
host:无默认值,配置 PushGateway 服务所在的机器 IP。
jobName:无默认值,要上报 Metrics 的 Job 名称。
port:默认值是 -1,这里配置 PushGateway 服务的端口。
randomJobNameSuffix:默认值是 true,指定是否将随机后缀名附加到作业名。
配置 Reporter
在 flink-conf.yaml 中配置的样例如下:
metrics.reporter.promgateway.class: org.apache.flink.metrics.prometheus.PrometheusPushGatewayReporter
metrics.reporter.promgateway.host: 172.16.104.226
metrics.reporter.promgateway.port: 9091
metrics.reporter.promgateway.jobName: myJob
metrics.reporter.promgateway.randomJobNameSuffix: true
metrics.reporter.promgateway.deleteOnShutdown: false
metrics.reporter.promgateway.groupingKey: k1=v1;k2=v2
metrics.reporter.promgateway.interval: 60 SECONDS

部署 pushgateway
Pushgateway 是一个独立的服务,Pushgateway 位于应用程序发送指标和 Prometheus 服务器之间。 Pushgateway 接收指标,然后将其作为目标被 Prometheus 服务器拉取。可以将其看作代理服务,或者与 blackbox exporter 的行为相反,它接收度量,而不是探测它们。
解压 pushgateway
Tar -xvf pushgateway-1.5.1.linux-amd64.tar.gz
mv pushgateway-1.5.1.linux-amd64 pushgateway
启动 pushgateway
进入到 pushgateway 目录下
Cd pushgateway
./pushgateway &

配置成服务pushgateway
vim /etc/systemd/system/pushgateway.service
[Unit]
Description=pushgateway
Documentation=https://prometheus.io/
After=network.target
[Service]
Type=simple
User=root
ExecStart=/opt/dtstack/pushgateway/pushgateway
Restart=on-failure
[Install]
WantedBy=multi-user.target
启动pushgateway服务,并配置开机自启
systemctl daemon-reload
systemctl start pushgateway
systemctl status pushgateway
systemctl enable pushgateway
查看是否在后台成功运行
ps aux | grep pushgateway
登录 pushgateway webui
http://172.16.104.226:9091/
运行任务
./bin/flink run -m yarn-cluster -yjm 1024 -ytm 1024 examples/streaming/WindowJoin.jar
修改prometheus配置
vim /opt/dtstack/prometheus-2.33.3/prometheus.yml
scrape_configs:
- job_name: 'pushgateway'
static_configs:
- targets: ['localhost:9091']
labels:
instance: 'pushgateway'
重启prometheus
systemctl restart prometheus
反压查看监控:
flink_taskmanager_job_task_isBackPressured
是否反压
flink_taskmanager_job_task_isBackPressured{jobUqId="aBcDf"}
发送端很高,说明是下游反压
flink_taskmanager_job_task_buffers_outPoolUsage{jobUqId="aBcDf",task_id="0dfd460ec7c42df129e084b4306beaa2"}
接收端很高, 说明接收端正在将反压传递给上游节点
flink_taskmanager_job_task_buffers_inPoolUsage{jobUqId="aBcDf",task_id="0dfd460ec7c42df129e084b4306beaa2"}
flink_taskmanager_job_task_buffers_inputFloatingBuffersUsage{jobUqId="aBcDf",task_id="0dfd460ec7c42df129e084b4306beaa2"}
flink_taskmanager_job_task_buffers_inputExclusiveBuffersUsage{jobUqId="aBcDf",task_id="0dfd460ec7c42df129e084b4306beaa2"}
————————————————