
相关文章
Linux网络扫描和嗅探工具—Nmap
1、简介Nmap,也就是Network Mapper,是Linux下的网络扫描和嗅探工具包。它由Fyodor编写并维护。由于Nmap品质卓越,使用灵活,它已经是渗透测试人员必备的工具。其基本功能有三个...
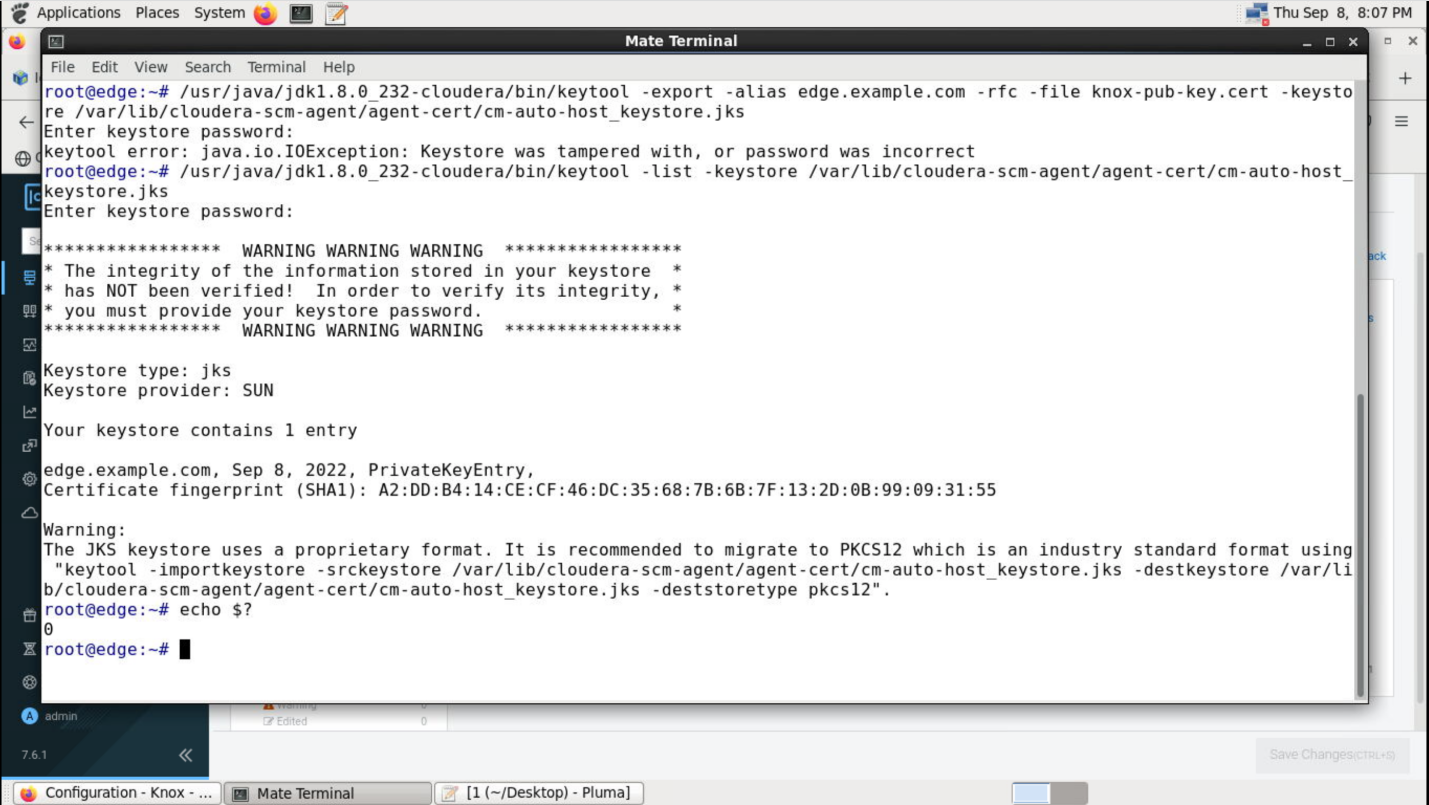
CDP实操--配置KNOX SSO(五)
1.1配置Atlas的SSO身份验证在Knox SSO的topology里配置Knox与LDAP集成认证如下,并重启Knox服务role=authenticationauthentication.na...
oracle回收站简介
一、回收站简介1、概念和功能回收站从ORACLE 10g开始引入,全称叫Tablespace Recycle Bin。回收站实际是一个逻辑区域,使用的已经分配的表空间,表被drop时,数据不会实际删除...
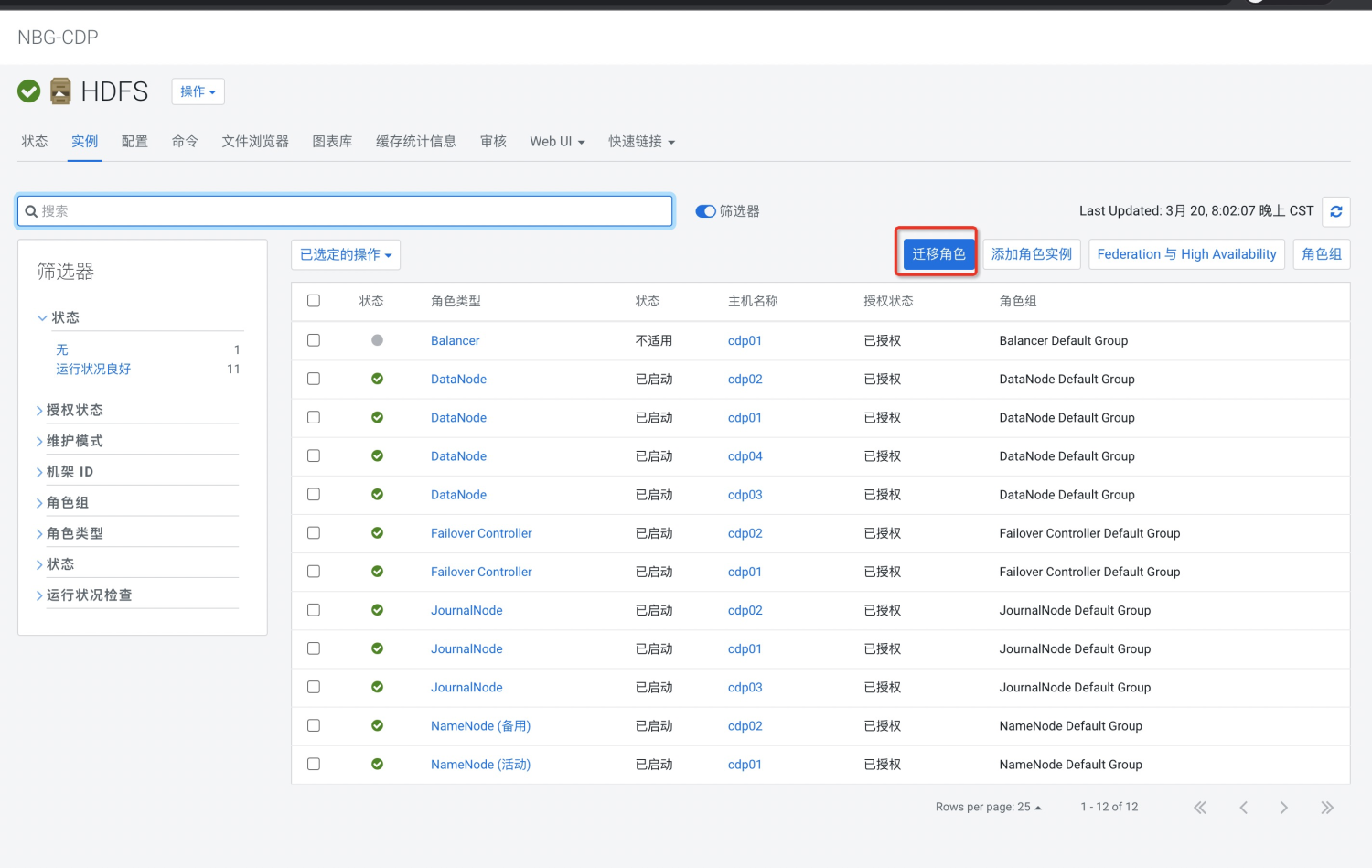
CDP实操--HDFS角色迁移
hdfs角色迁移功能在cdp页面中就可以实现该功能,迁移的时间与namenode元数据大小,以及block数量多少有关,注意迁移过程中集群需要关闭,要预留出操作时间窗口。1、页面选择迁移角色2...
华为云创建udf
如何使用 1.把以上程序打包成AddDoublesUDF.jar,并上传到HDFS指定目录下(如“/user/hive_examples_jars/”)且创建函数的用户与使用函数的用户有该文件的可读...
gitlab的部署
一、GitLab简介GitLab 是一个用于仓库管理系统的开源项目。使用Git作为代码管理工具,并在此基础上搭建起来的web服务。可通过Web界面进行访问公开的或者私人项目。它拥有与Github类似的...
发表评论
