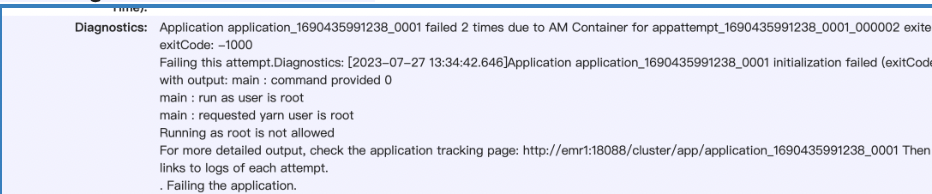
pod内无法访问slb的监听
问题背景
在A账号下的k8s集群中有个nginx 应用,需要去访问B账号下内网slb代理的一个服务。B账号下的slb有多条监听,测试发现只有个别监听可以telnet通,其余监听telnet均不通。可能是哪里的问题呢?
排查步骤
1、最先想到的是排查B账号下的slb监听是否有开启访问控制?
核实,确认所有的监听均没有开启访问控制。
2、A账号k8s集群中pod或者svc的ip刚好和B账号的slb的ip冲突了?
登陆到A账号的k8集群中,核查集群网络情况,如下:
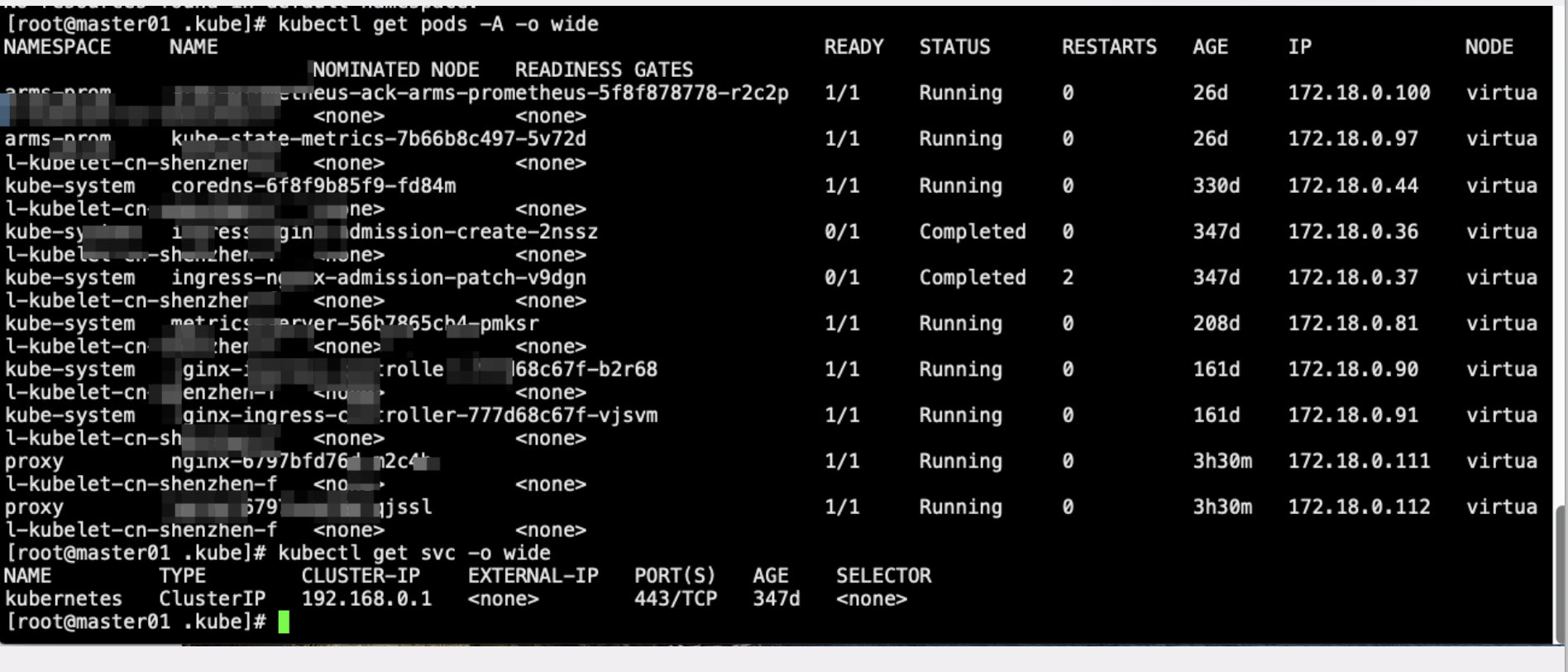
从输出结果确认,A账号这边不存在和要访问的ip有冲突的情况。
4、核查A账号和B账号网络打通情况
两个账号通过VPN ipsec打通,路由表信息如下:
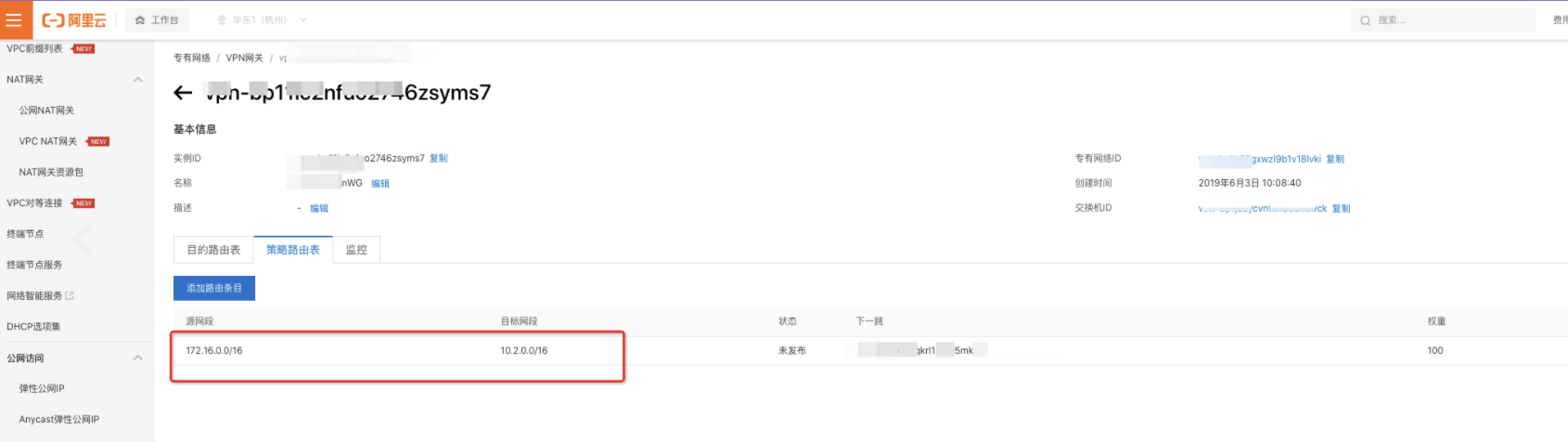
由于是直接访问的slb不通,同时发现,slb后端ecs的网段在vpn配置的路由表的段中。所以,直接绕过slb,测试到后端ecs的网路连通性情况。
针对这两个监听后端的ecs分别做ping测试,发现确实极个别的ecs可以ping通,很多ecs都无法ping通。
进一步,分别登陆到ping正常和ping异常的服务器,尝试去抓包分析。
这个时候,在ping异常的服务器上,查看ip信息的时候,发现,服务器上部署了docker服务,而ping正常的服务器上是没有部署docker服务的,同时ping异常的服务器上规划的网段刚好和A账号下的k8s集群的pod网段有冲突,这时候就判断是由于这里的问题导致的。
为了验证这一结论,在A账号的nginx服务的pod内发起ping动作,同时在ping异常的服务器上抓包,抓包结果如下:
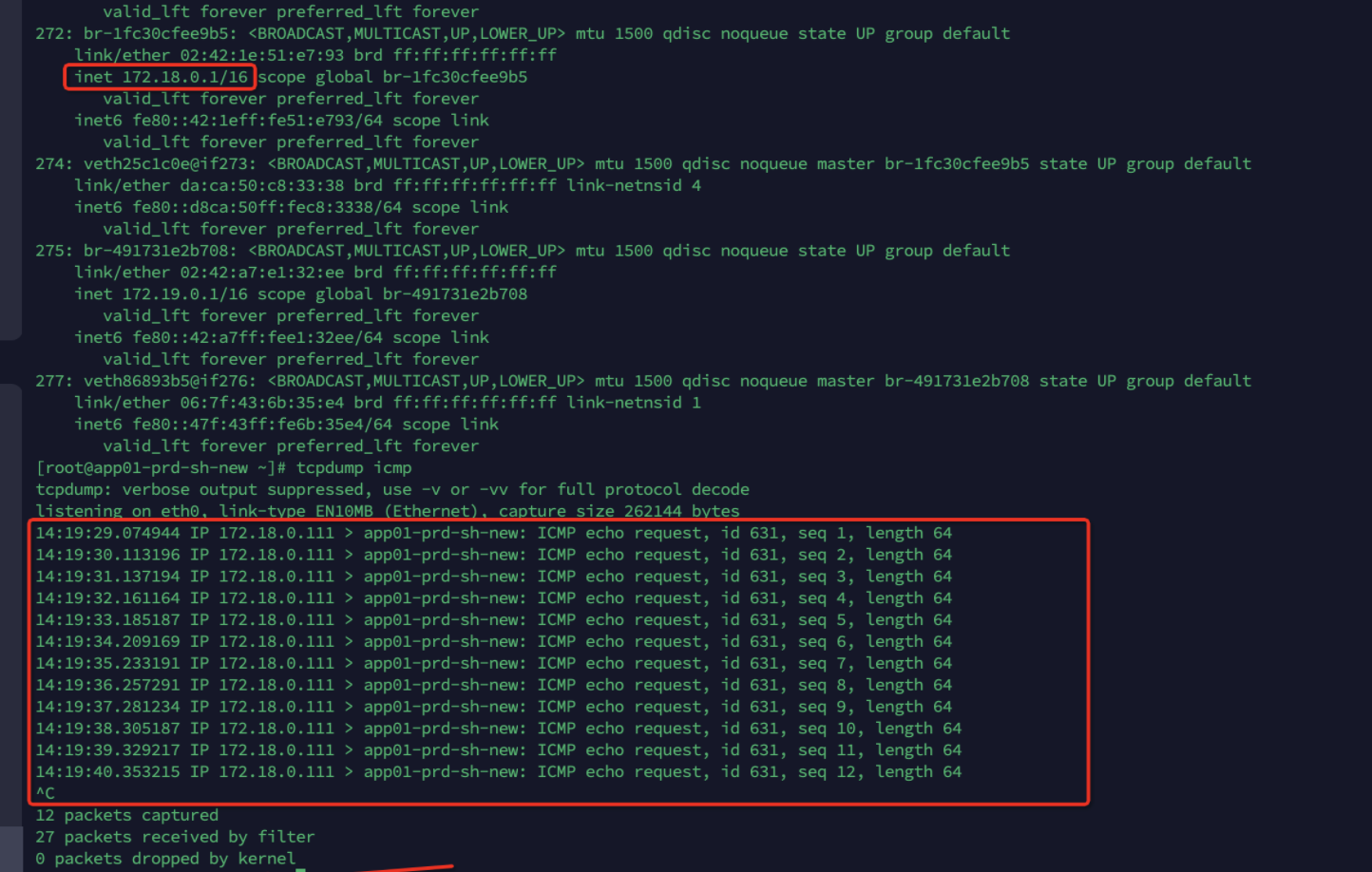
可以看到,只有入包,没有回包(因为,docker启动的容器,并没有占用172.18.0.111)
和之前的判断一致。所以要想解决这一问题,简单的方法就是调整下docker的网段。