Nacos服务公网环境登陆报密码错误问题排查
问题现象
nacos服务内网可以正常登录,如下:
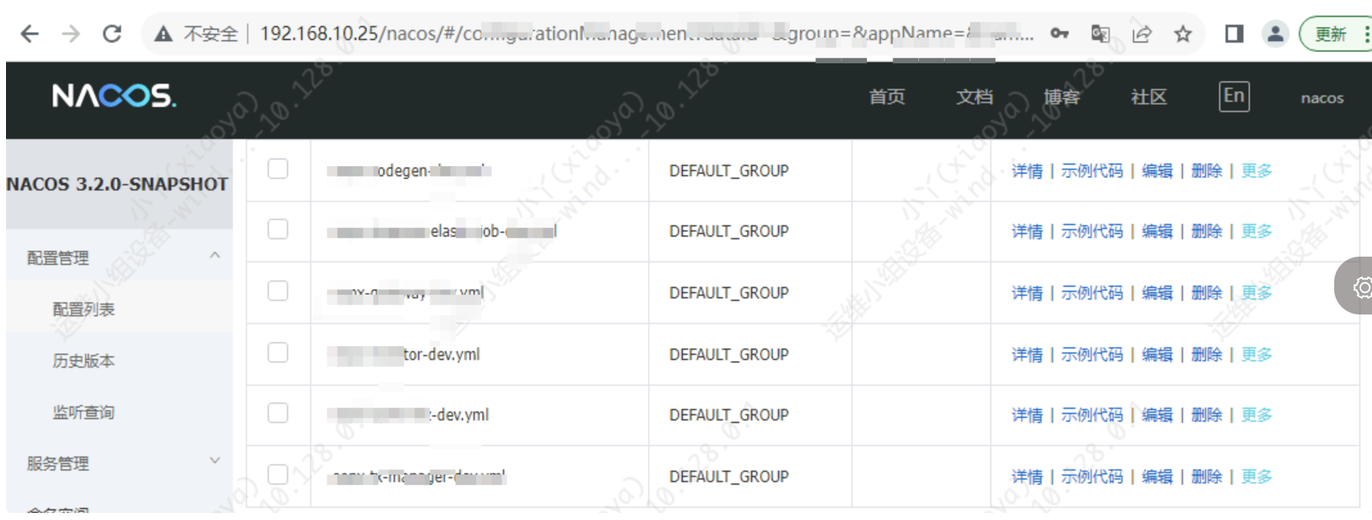
走公网代理出来之后,无法正常登录,报错"用户名密码错误"

排查步骤
链路分析
首先确认公网代理的链路:
域名—>haproxy—>nginx—>nacos
内网代理链路:
ip—>nginx—>nacos
查找报错接口
既然内网登录正常,证明该用户名密码正确。
首先查看现场,浏览器访问登录地址,打开f12,查看是否有报错接口
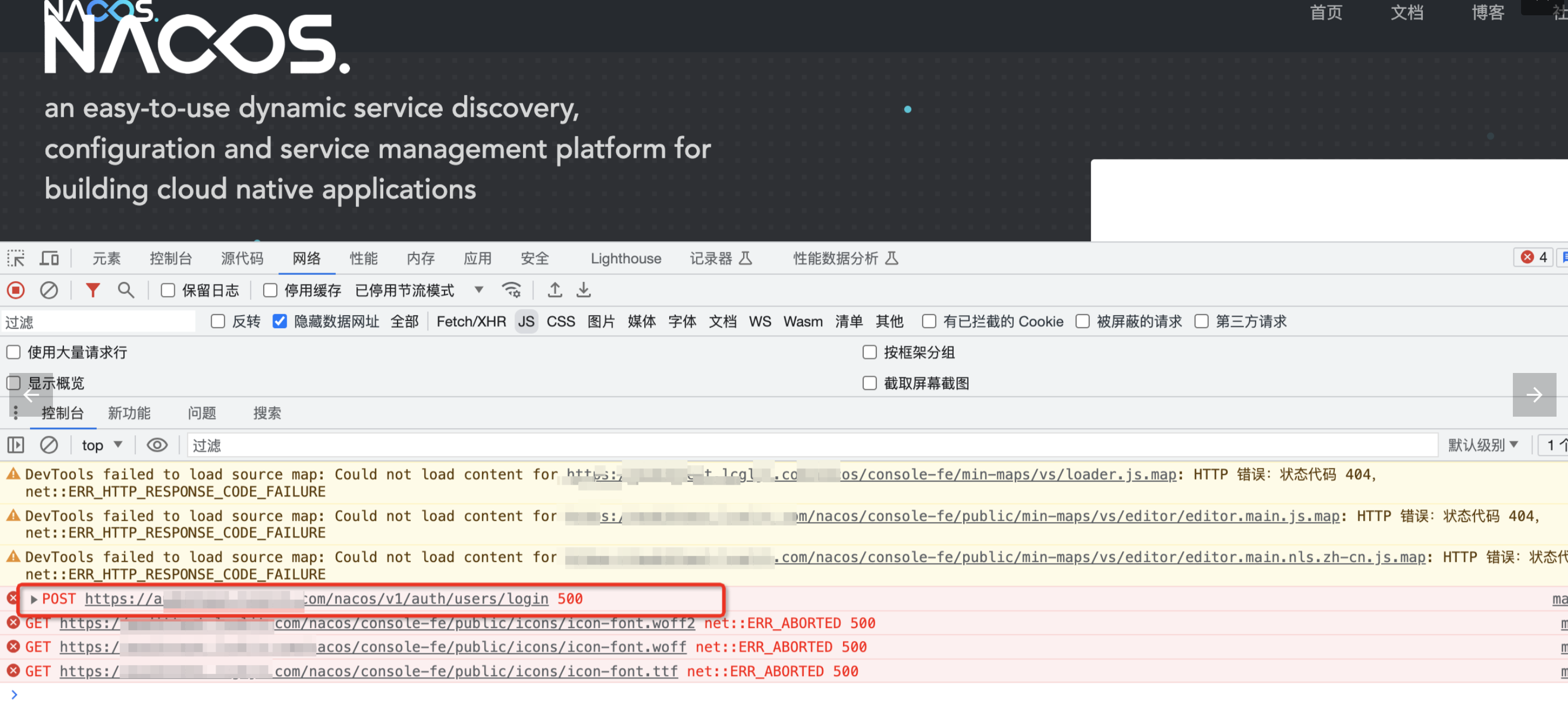
可以看到:https://xxx/nacos/v1/auth/users/login 这个接口返回500异常状态码。
对比,可以看到,内网环境下,该接口是正常返回200状态码的。

分析是链路中哪一层返回的500异常状态码。
抓包分析
最简单的办法就是抓包分析。开启抓包,公网多次访问。分析抓包结果。
像这种问题,直接从链路最内层开始抓,从内层到外层的顺序。
nacos层抓包
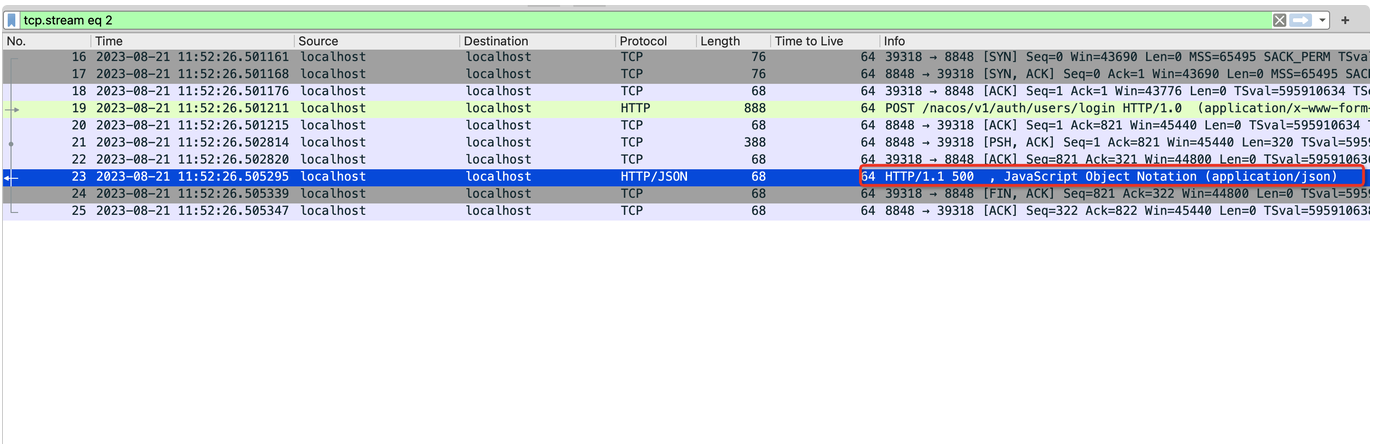
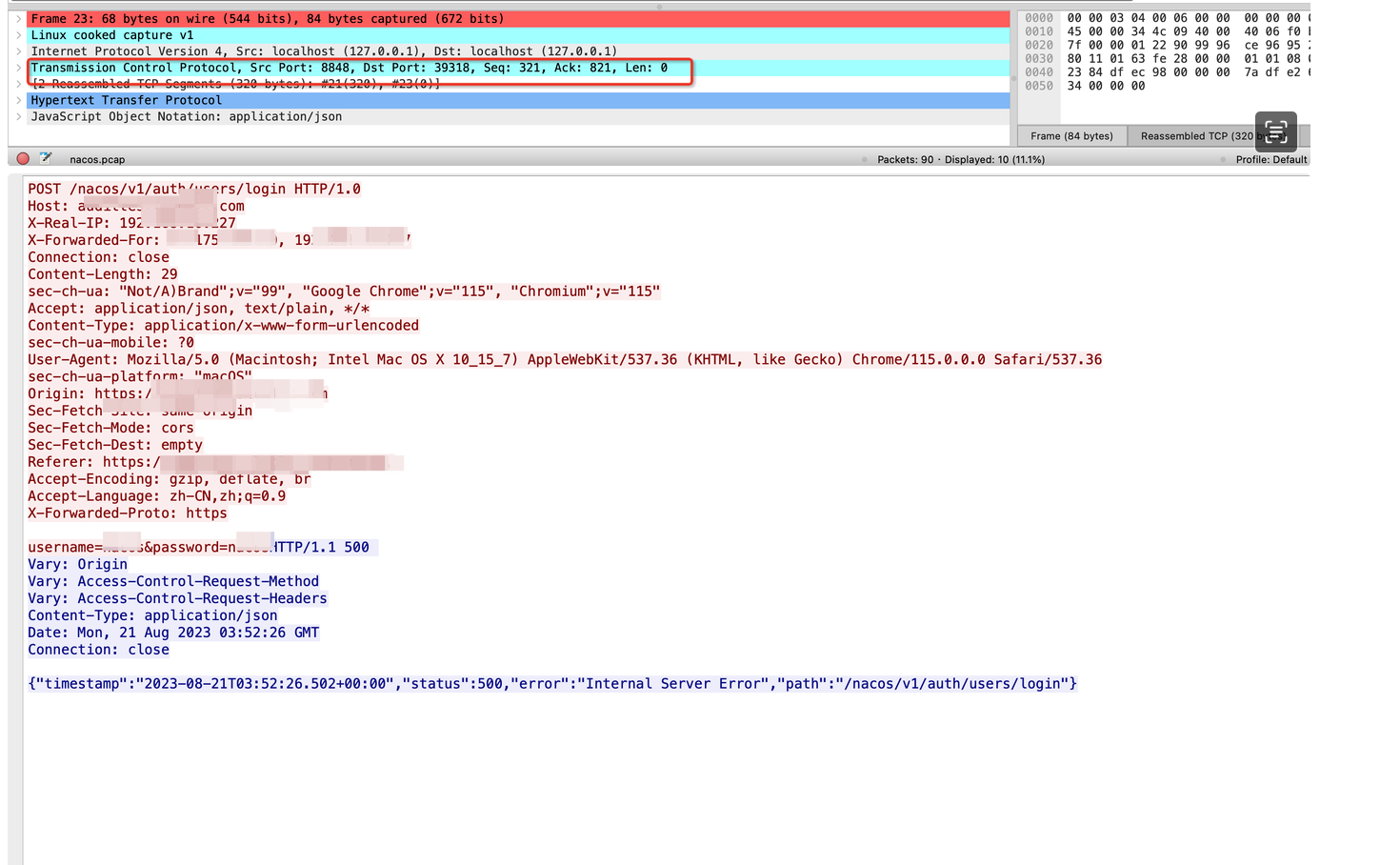
可以看到是后端nacos服务直接返回的即是500异常状态码。看到这个结果,即外层就无需抓包了,是由于nacos返回了500,导致最终客户端拿到的状态码是500。
在外层也简单抓包看下。
haproxy层抓包

可以看到是nginx层返回给haproxy服务500状态码
nacos日志分析
既然是nacos服务直接返回的500状态码,那么肯定要从nacos报错日志中入手。最终在服务器系统日志中发现服务存在跨域的报错。借助tail -f 实时观察日志,并且同时再次走公网访问验证,日志同时再次打印对应日志。由此可见,是由于后端这块儿跨域的配置有问题导致。
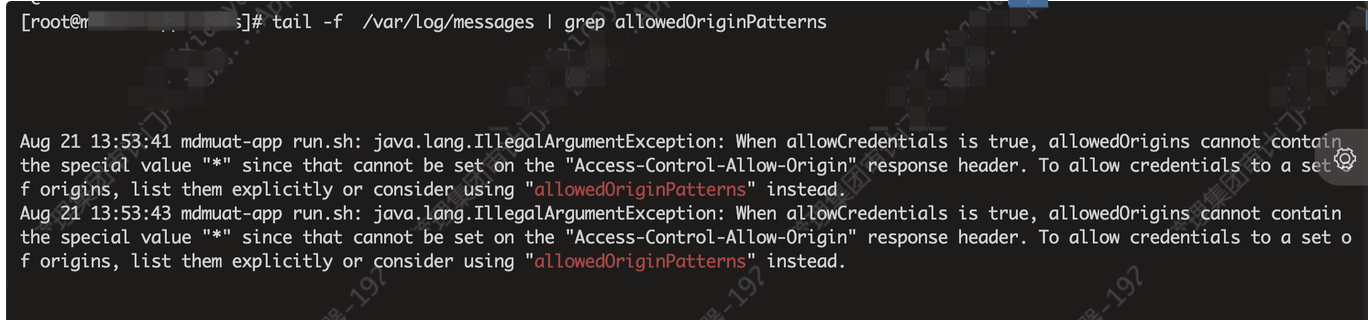
将日志报错反馈给开发修改代码配置解决。