CDH实操--kudumaster迁移
1 概述
本次kudumaster迁移,中间不需要停kudu集群(会涉及滚动重启kudu角色); 注:若因为任务持续运行导致kudu停止超时可手动一台台停止-启动
2 master迁移

将cdh2中的master节点迁移到cdh3中。(注意leader、follow,将follow节点进行迁移)
2.1 将每个master的记录下来
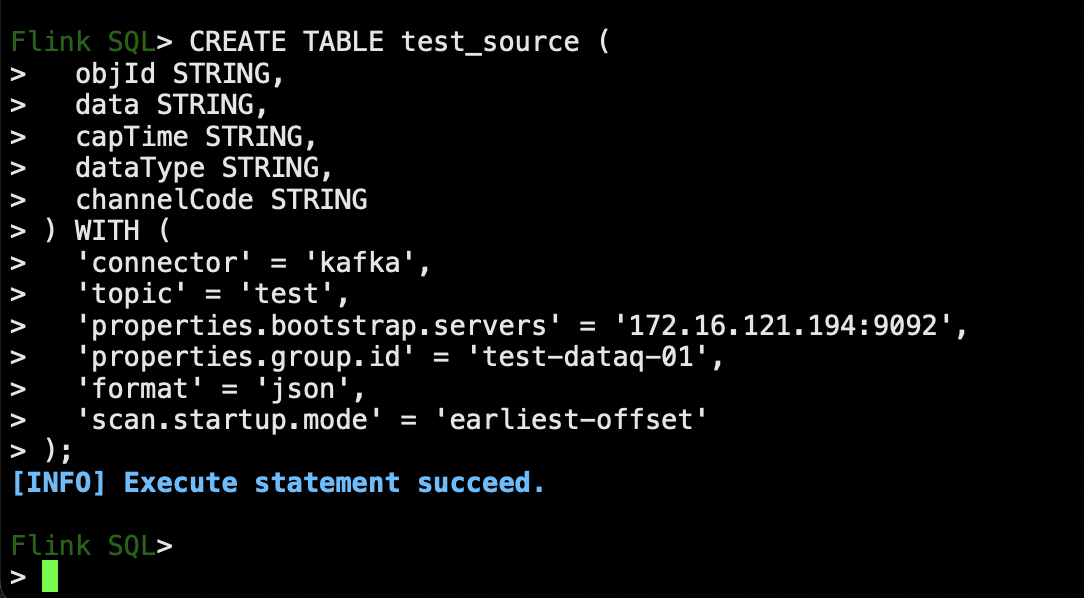
#操作前先停掉待迁移的master
sudo -u kudu kudu fs dump uuid --fs_wal_dir=/data/kmaster/wal/ --fs_data_dirs=/data/kmaster/data/ 2>/dev/null

2.2 存活的一个master上执行
sudo -u kudu kudu local_replica cmeta print_replica_uuids --fs_wal_dir=/data/kmaster/wal/ --fs_data_dirs=/data/kmaster/data/ 00000000000000000000000000000000 2>/dev/null
2.3 根据前两步确定dead master的uuid
2.4 在新master机器上执行,uuid为dead master的标识
mkdir -p /data/kmaster/data/ mkdir -p /data/kmaster/wal/ chown kudu:kudu -R /data/kmaster sudo -u kudu kudu fs format --fs_wal_dir=/data/kmaster/wal/ --fs_data_dirs=/data/kmaster/data/ --uuid=817b421e254943179c6f02ff333db29f

2.5 将一台存活master的元数据拷贝过来,用kudu用户执行
sudo -u kudu kudu local_replica copy_from_remote --fs_wal_dir=/data/kmaster/wal/ --fs_data_dirs=/data/kmaster/data/ 00000000000000000000000000000000 cdh1:7051

2.6 新master和存活master上更新master list
每台都执行下面命令
sudo -u kudu kudu local_replica cmeta rewrite_raft_config --fs_wal_dir=/data/kmaster/wal/ --fs_data_dirs=/data/kmaster/data/ 00000000000000000000000000000000 275d0ef30feb4c59a09ebf38d52fafdb:cdh1:7051 817b421e254943179c6f02ff333db29f:cdh3:7051

在之前的kudumastrer节点cdh1中执行报错,要先关掉该master服务,在去执行。


2.7 CM界面删除已停掉的待替换master,新master和之前存活的master一台台重启,对应的tserver显示过期配置,重启。

2.8 检查master状态,需要在每个master管理页面看到的master节点列表是一致的

2.9 执行健康检查脚本
sudo -u kudu kudu cluster ksck cdh1,cdh3

2.10 修改之前表的表属性,与当前的master节点一致。
在hive元数据mysql所在库中执行
UPDATE TABLE_PARAMS SET PARAM_VALUE = 'cdh1,cdh3' WHERE PARAM_KEY = 'kudu.master_addresses' AND PARAM_VALUE = 'cdh1,cdh2';
impala-shell中刷新元数据
方法1、执行INVALIDATE METADATA;(这个会消耗大量性能)
INVALIDATE METADATA;
方法2、重启impala catalog