HDFS Fsimage分析磁盘目录(文件级别)
首先获取fsimage信息
hdfs dfsadmin -fetchImage /opt/fsimage
格式化fsimage 转换为可读文本
hdfs oiv -i /opt/fsimage/fsimage_0000000000000026275 -o /opt/fsimage/fsimage.csv -p Delimited -delimiter ","
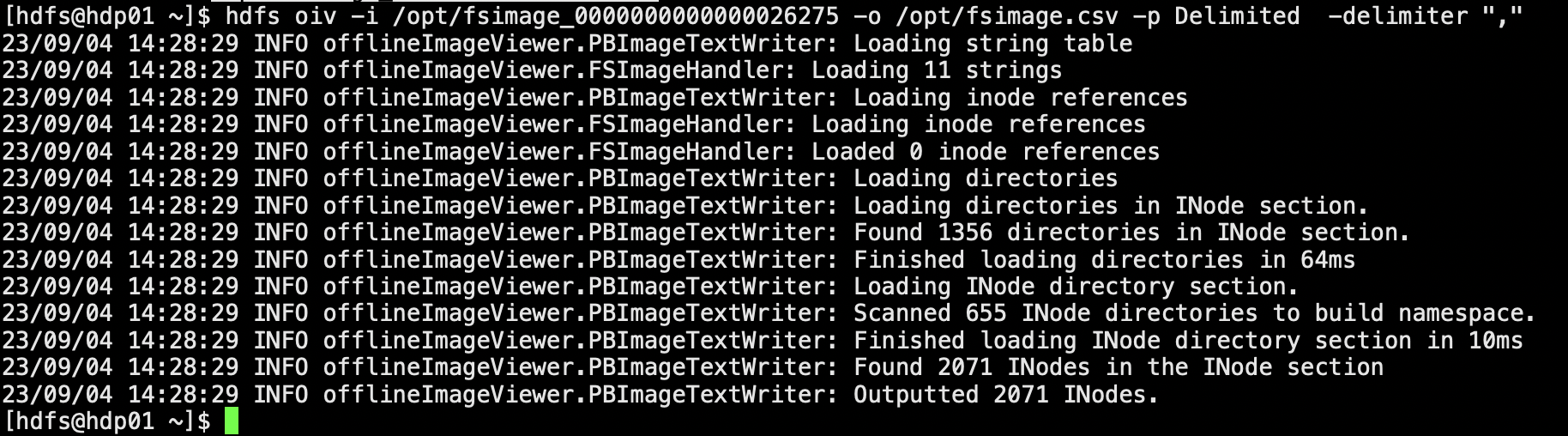
查看前10行fsimage.csv
head /opt/fsimage/fsimage.csv
数据结构:
1. Path(路径):HDFS 中存储文件或目录的位置。
2. Replication(副本数):文件在 HDFS 中的副本数。HDFS 通过将文件划分为块并在不同的节点上复制这些块来提供容错和可靠性。
3. ModificationTime(修改时间):指示文件或目录上一次被修改的时间戳。
4. AccessTime(访问时间):指示文件或目录上一次被访问的时间戳。
5. PreferredBlockSize(首选块大小):文件在 HDFS 中的块大小。文件被分割成相同大小的块,并存储在 HDFS 上的不同节点上。
6. BlocksCount(块数):文件在 HDFS 中的块数量。
7. FileSize(文件大小):文件的总大小。(单位字节)
8. NSQUOTA(命名空间配额):命名空间(文件和目录)的配额限制。
9. DSQUOTA(数据配额):文件或目录的数据配额限制。
10. Permission(权限):用于确定文件或目录对用户和组的访问权限。包括读取、写入和执行权限。
11. UserName(用户名):文件或目录所属的用户。
12. GroupName(组名):文件或目录所属的组。
这些参数描述了在 HDFS 中管理和组织文件和目录时使用的关键属性和元数据。

删除fsimage.csv的首行表头
sed -i -e "1d" /opt/fsimage.csv
以上是手动步骤
可以通过代码直接进行 跑代码就可以了
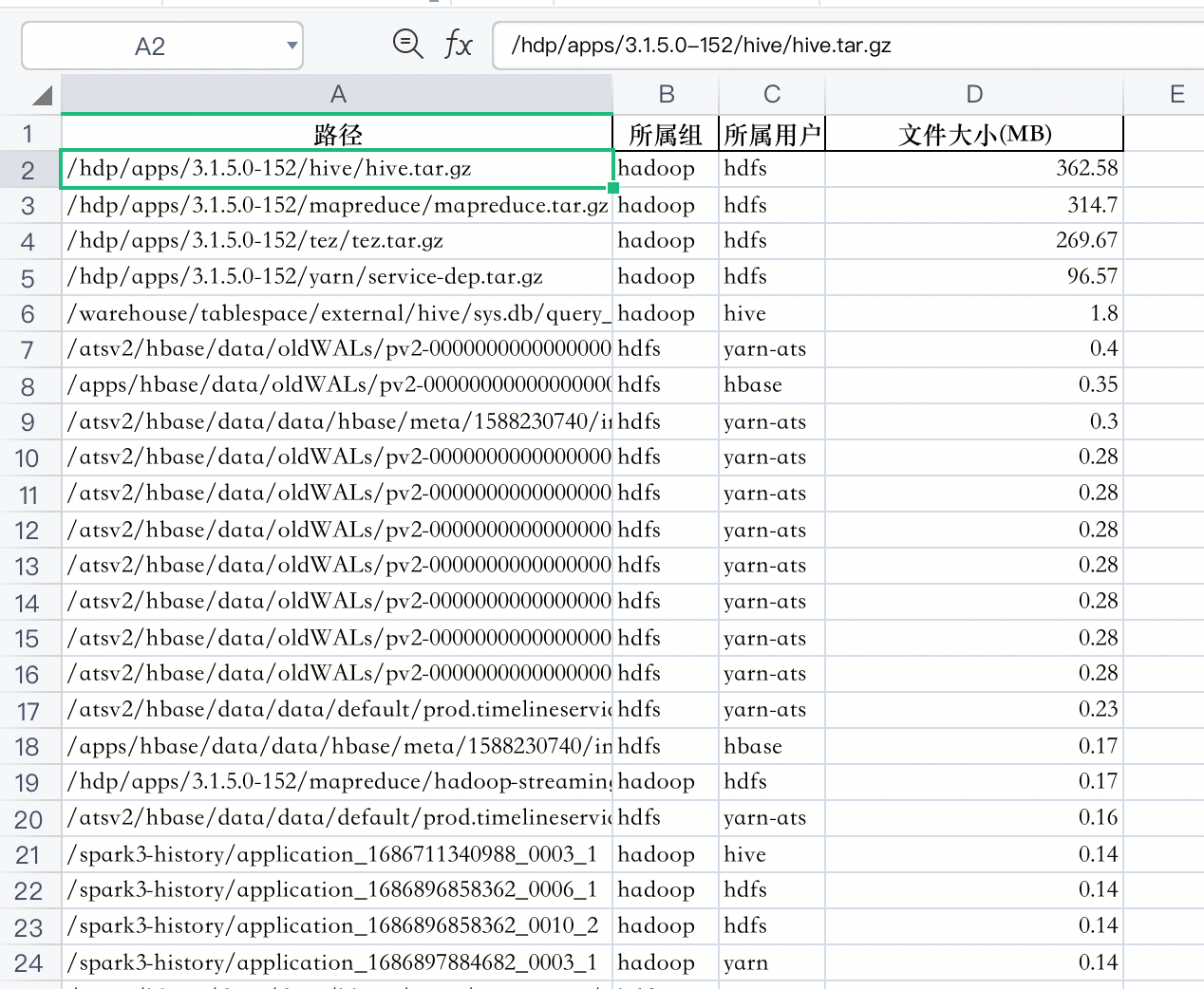
统计文件大小
# coding=UTF-8
import subprocess
from datetime import date
import pandas as pd
def Get_fsimage(path):
fsimage_path = subprocess.getstatusoutput(f"hdfs dfsadmin -fetchImage {path}")[1]
print(fsimage_path)
result = fsimage_path.split(" ")
return result[-3]
def Get_fsimage_csv(fsimage_path):
result = \
subprocess.getstatusoutput(
f'hdfs oiv -i {fsimage_path} -o /opt/fsimage/fsimage.csv -p Delimited -delimiter ","')[
1]
print(result)
def Get_head_fsimage():
subprocess.getstatusoutput('sed -i -e "1d" /opt/fsimage/fsimage.csv')[1]
result = subprocess.getstatusoutput("head /opt/fsimage/fsimage.csv")[1]
print(result)
def Get_filesize():
fsimage_csv = subprocess.getstatusoutput('cat /opt/fsimage/fsimage.csv')[1]
lines = fsimage_csv.split("\n")
groups = []
for line in lines:
result = line.split(',')
# 将第6个元素转换为浮点数
# result[-6] = float(result[-6])
# 进行除法运算并保留两位小数
result[-6] = round(int(result[-6]) / 1024 / 1024, 2)
group = [result[0], result[-1], result[-2], result[-6]]
groups.append(group)
column_titles = ["路径", "所属组", "所属用户", "文件大小(MB)"]
df = pd.DataFrame(groups, columns=column_titles)
filename = '/opt/fsimage/hdfs_output' + date.today().strftime("%Y%m%d") + '.xlsx'
df.to_excel(filename, index=False)
return filename
def run():
print("获取fsimage信息")
fsimage_path = Get_fsimage("/opt/fsimage/")
print("格式化fsimage 转换为可读文本")
Get_fsimage_csv(fsimage_path)
print("尝试获取前10行数据")
Get_head_fsimage()
print("统计文件大小......")
filename = Get_filesize()
print(f"统计完成! \n 输出路径:{filename}")
if __name__ == '__main__':
print('开始')
run()
输出为excel文档 需要对文件大小进行降序