楼高2年前983
1.Fetch抓取Fetch抓取是指,Hive中对某些情况的查询可以不必使用MapReduce计算。例如:SELECT * FROM students;在这种情况下,Hive可以简单地读取studen...
楼高2年前1077
(1)ResourceManager相关配置调度器:yarn.resourcemanager.scheduler.class 默认是容量调度器处理调度器请求的线程数量:yarn.resource...
楼高2年前1067
MapReduce程序效率的瓶颈在于两点:1)计算机性能(1)CPU、内存、磁盘、网络2)I/O操作优化(1)数据倾斜(2)Map运行时间太长,导致Reduce等待过久(3)小文件过多下来就根据这两点...
楼高2年前1309
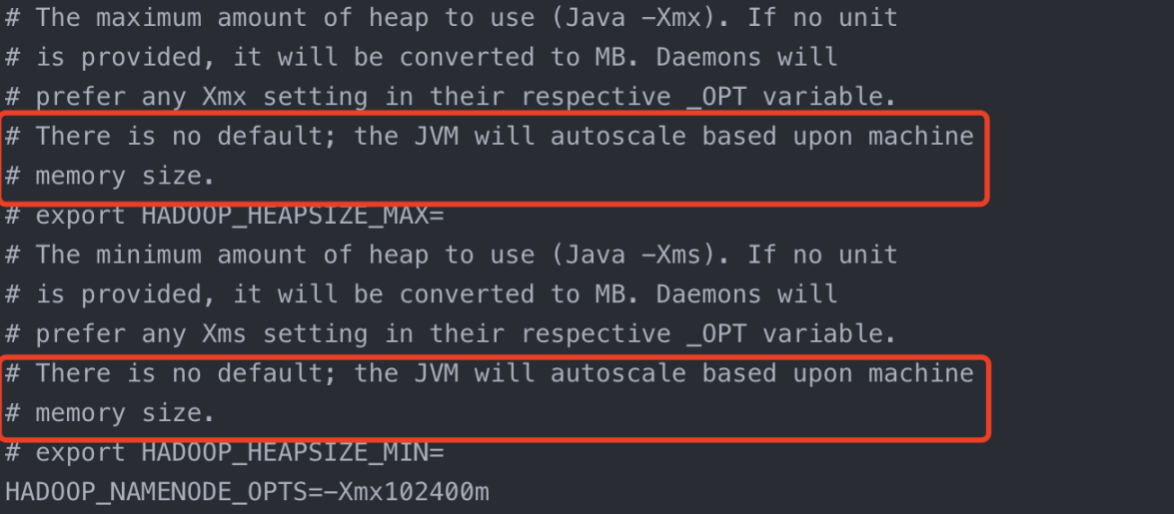
1.NameNode内存生产配置(1)NameNode内存计算,每个文件块大概占用150byte,一台服务器128G内存为例,能存储9.1亿个文件128 * 1024 * 1024 * 1024 /...
楼高2年前1398
1 线上问题kafka报错many open files,查看日志如下截取部分错误信息...
楼高2年前2140
1 线上问题kafka生产者罢工,停止生产,生产者内存急剧升高,导致程序几次重启。查看日志,发现Produce程序爆异常kafka.common.MessageSizeTooLargeExceptio...
楼高2年前1375
Kafka在运行时会生成大量的日志记录信息,包含了运行状态、错误信息、性能指标等。这些日志文件会占用很大的磁盘空间,过多的日志文件也会影响Kafka的性能,因此需要采取一些日志管理措施来清理无用的日志...
楼高2年前1110
1.监控健康状态为了了解 Kafka 的运作状态和性能状况需要对 Kafka 进行监控和诊断,通过Kafka提供的监控工具和插件可以诊断出 Kafka 的异常、错误、瓶颈和故障等问题并及时采取对应的措...
楼高2年前1304
一、增量恢复增量恢复需要使用 MirrorMaker 来实现,下面是 MirrorMaker 的用法示例:# 创建MirrorMaker 配置文件cat > /tmp/mirror-maker....
楼高2年前1700
一、数据备份Kafka的数据备份包括两种类型:全量备份和增量备份全量备份是将整个 Kafka 的数据复制到一个不同的地方增量备份是在全量备份后仅仅备份增量的数据...
楼高2年前1243
一、配置文件Kafka的配置文件为 config/server.properties,在此文件中进行 Kafka 的基础配置,例如端口、日志目录、Zookeeper 信息和 Broker ID 等还可...