楼高2年前1334
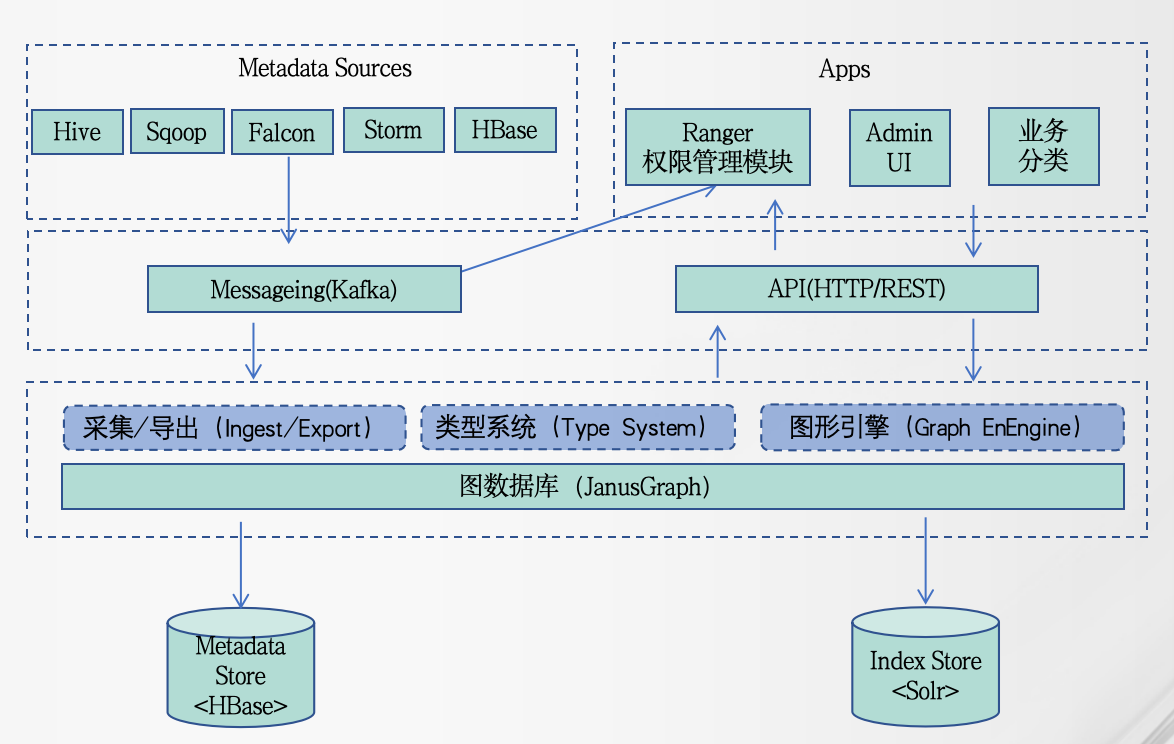
一、元数据概念元数据是关于数据的数据,它实质上封装了高度结构化字段中有关数据资产的不同属性、历史记录、来源、版本和其他信息,主要用于跟踪、分类和分析。元数据大致定义为提供有关其他内容的信息的数据,但不...
恩慈2年前2127
用户执行命令drop database/table/partition之后,再使用命令recover来恢复整个数据库/表/分区的所有数据。这种修复将会把FE上的数据库/表/分区的结构,从catalog...
楼高2年前2121
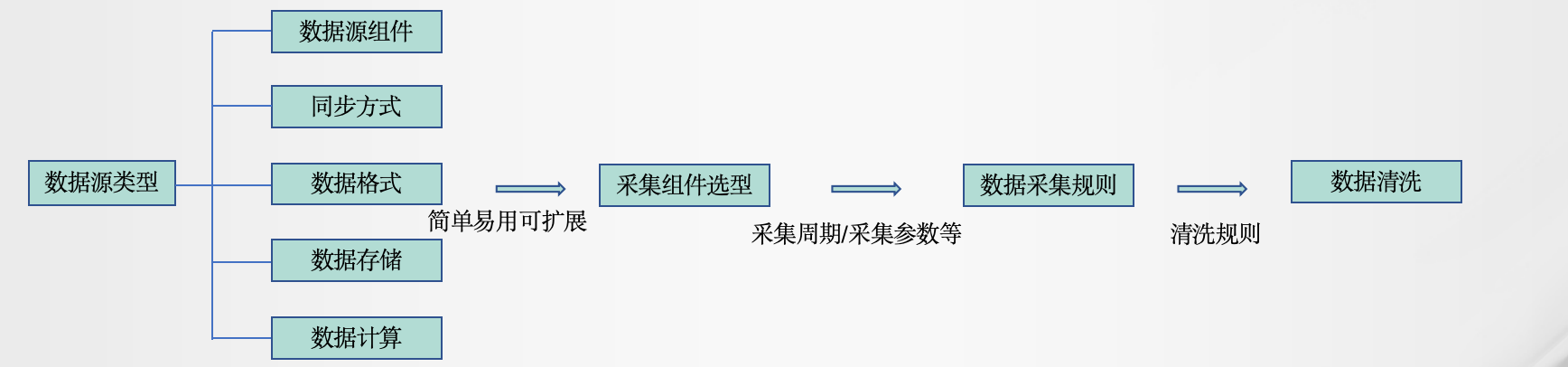
按数据的源头、实际上也是对应的数据采集方式,分别进行分析与技术推荐,数据从源头基本分为一下三大类1、Web页面/移动App/MES/IoT/系统生产: 这些数据是被动接收。建议可采用Apache Ni...
楼高2年前1326
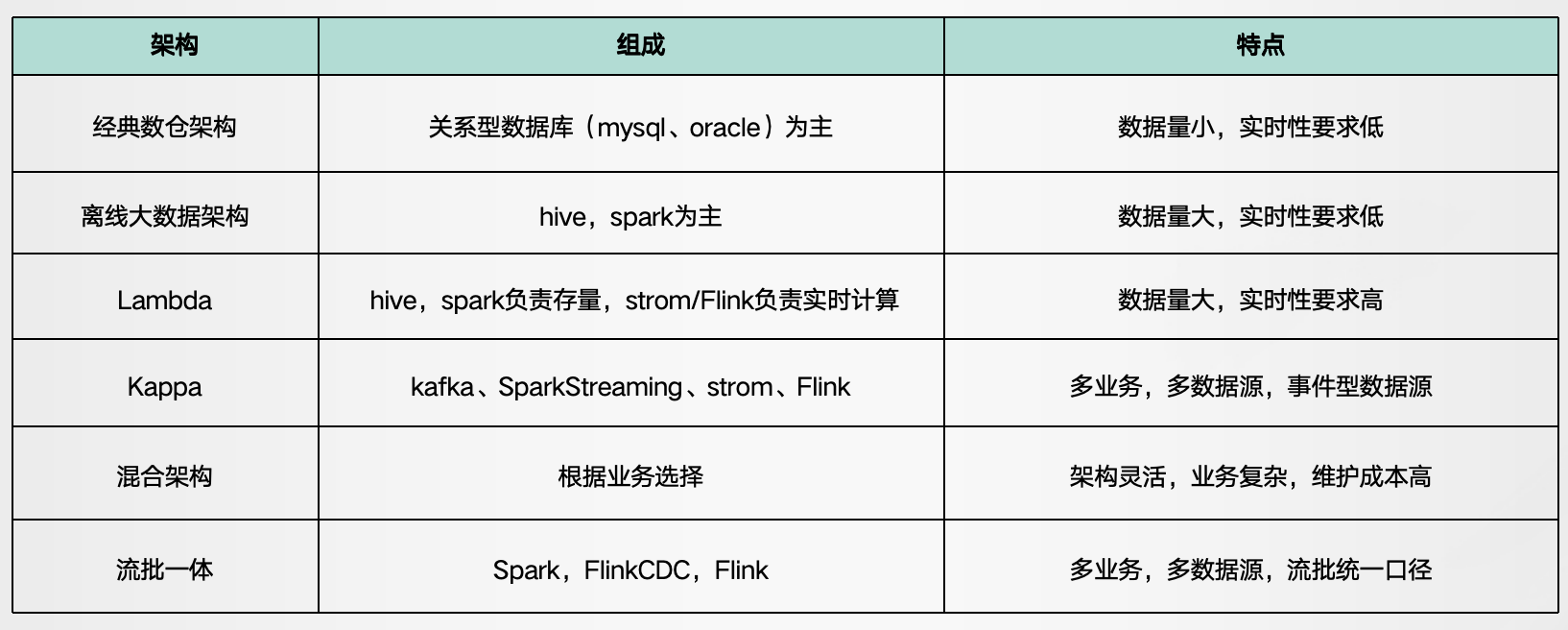
一、数仓架构经历过程随着数据量的暴增和数据实时性要求越来越高,以及大数据技术的发展驱动企业不断升级迭代,数据仓库架构方面也在不断演进,分别经历了以下过程:早期经典数仓架构 > 离线大数据架构 &...
楼高2年前1367
一、流批一体数据批流一体是一种云计算架构模式,它结合了批处理和流处理的特点,以实现更高效、灵活和可扩展的数据处理能力。在这种模式下,数据可以同时进行批处理和流处理,以满足不同场景下的需求...
恩慈2年前1494
Tls 证书生成生成的证书分发到每个节点 #ip和主机名为**coordinator**的ip和主机名及对应的vipkeytool -genkeypair -validity 36500 -ext S...
楼高2年前1312
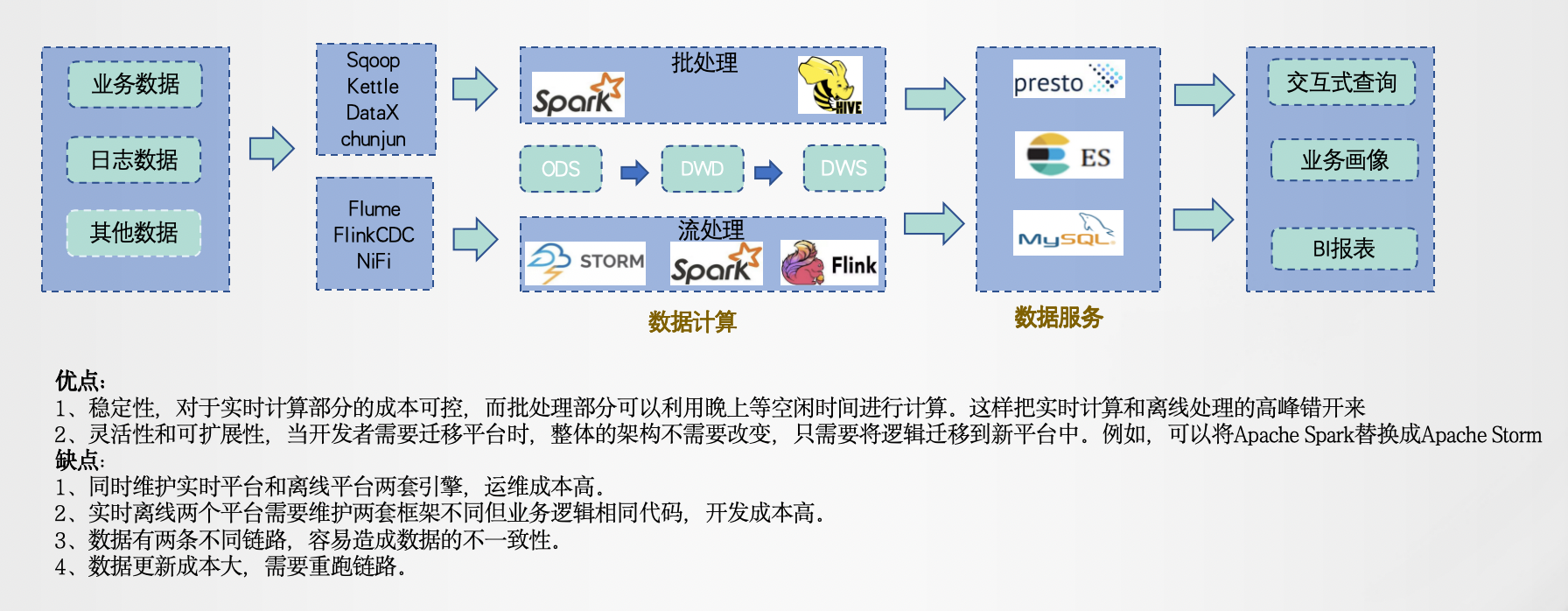
一、Lambda架构Apache Storm的创建者Nathan Marz于 2011 年开发,旨在解决大规模实时数据处理的挑战。Lambda数据架构提供了一个可扩展、容错且灵活的系统来处理大量数据。...