CDH实操--HDFS高可用设置
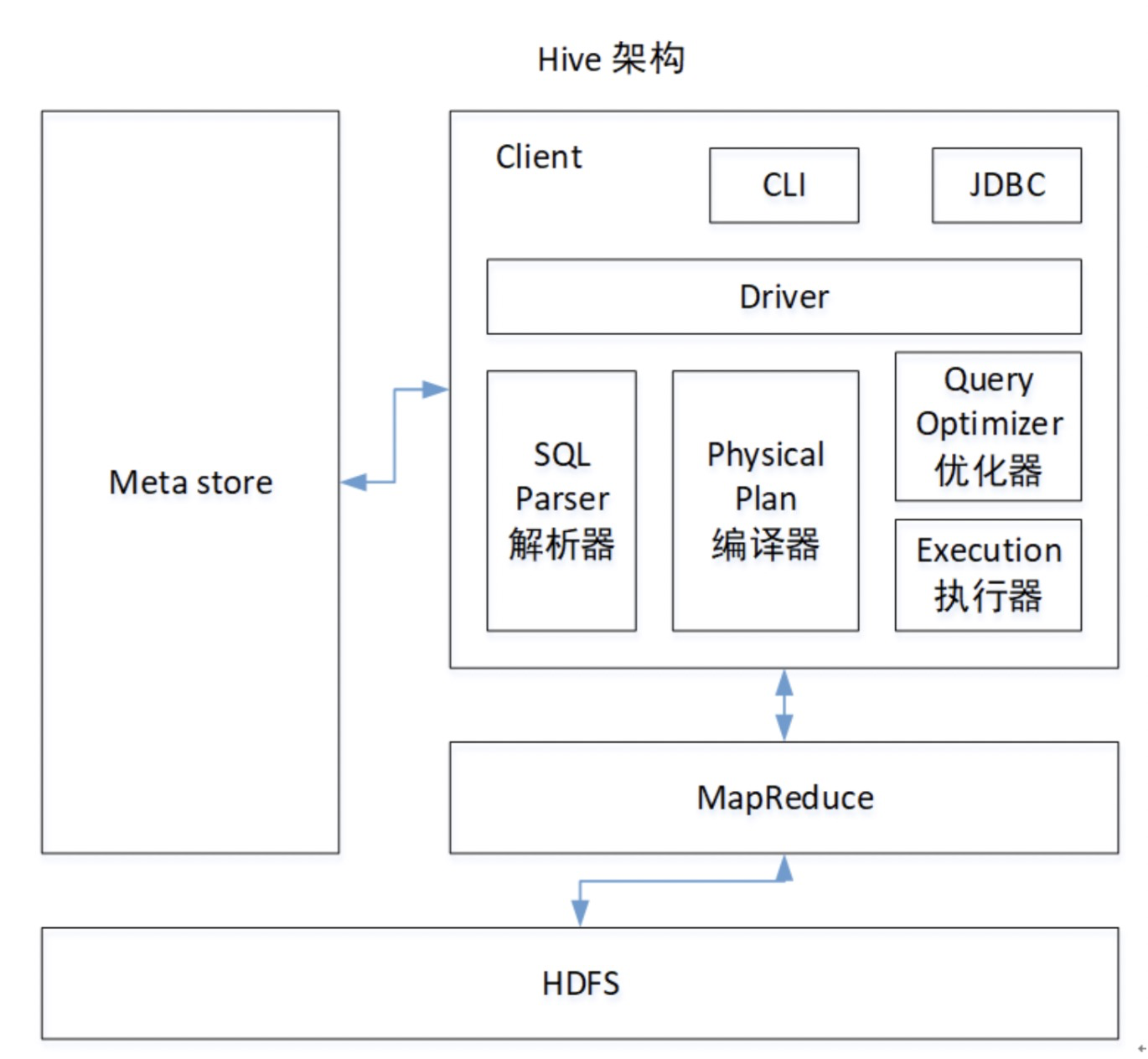
1 概述
在HDFS集群中NameNode存在单点故障(SPOF),对于只有一个NameNode的集群,如果NameNode机器出现意外,将导致整个集群无法使用。为了解决NameNode单点故障的问题,Hadoop给出了HDFS的高可用HA方案,HDFS集群由两个NameNode组成,一个处于Active状态,另一个处于Standby状态。
Active NameNode可对外提供服务,而Standby NameNode则不对外提供服务,仅同步Active NameNode的状态,以便在Active NameNode失败时快速的进行切换。本篇文章主要讲述如何使用Cloudera Manager启用HDFS的HA。
前置条件
a.拥有Cloudera Manager的管理员账号
b.CDH集群已安装成功并正常使用
2 启动HDFS的HA
2.1 使用管理员用户登录Cloudera Manager的Web管理界面,进入HDFS服务

2.2 点击“启用High Avaiability”,设置NameService名称

2.3 点击“继续”,选择NameNode主机及JouralNode主机

JouralNode主机选择,一般与Zookeeper节点一致即可(至少3个且为奇数)
2.4 点击“继续”,设置NameNode的数据目录和JouralNode的编辑目录

NameNode的数据目录默认继承已有NameNode数据目录。
2.5 点击“继续”,启用HDFS的High Availability,如果集群已有数据,格式化NameNode会报错,不用理。


2.6 点击“继续”,完成HDFS的High Availability

2.7 HDFS实例查看