Flink 状态管理
一、 Flink 中的状态
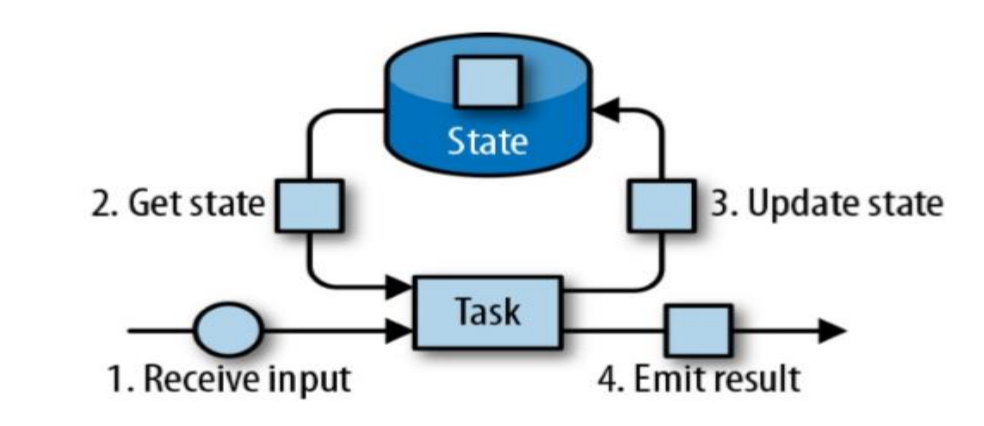
1、由一个任务维护,并且用来计算某个结果的所有数据,都属于这个任务的状态
2、可以认为状态就是一个本地变量,可以被任务的业务逻辑访问
3、Flink 会进行状态管理,包括状态一致性、故障处理以及高效存储和访问,以 便开发人员可以专注于应用程序的逻辑
二、状态类型
1、在 Flink 中,状态始终与特定算子相关联
2、为了使运行时的 Flink 了解算子的状态,算子需要预先注册其状态
状态类型:
(1)算子状态(Operator State)
算子状态的作用范围限定为算子任务,由同一并行任务所处理的所有数据都 可以访问到相同的状态,状态对于同一子任务而言是共享的,算子状态不能由相同或不同算子的另一个子任务访问
(2)键控状态(Keyed State)
键控状态是根据输入数据流中定义的键(key)来维护和访问的,Flink 为每个 key 维护一个状态实例,并将具有相同键的所有数据,都分区到 同一个算子任务中,这个任务会维护和处理这个 key 对应的状态,当任务处理一条数据时,它会自动将状态的访问范围限定为当前数据的 key
数据结构:
算子状态数据结构:
(1)列表状态(List state)
将状态表示为一组数据的列表
(2)联合列表状态(Union list state)
也将状态表示为数据的列表。它与常规列表状态的区别在于,在发生故 障时,或者从保存点(savepoint)启动应用程序时如何恢复
(3)广播状态(Broadcast state)
如果一个算子有多项任务,而它的每项任务状态又都相同,那么这种特 殊情况最适合应用广播状态。
键控状态数据结构:
(1)值状态(Value state)
将状态表示为单个的值
(2)列表状态(List state)
将状态表示为一组数据的列表
(3)映射状态(Map state)
将状态表示为一组 Key-Value 对
(4)聚合状态(Reducing state & Aggregating State)
将状态表示为一个用于聚合操作的列表
三、状态后端
1、每传入一条数据,有状态的算子任务都会读取和更新状态
2、由于有效的状态访问对于处理数据的低延迟至关重要,因此每个并行 任务都会在本地维护其状态,以确保快速的状态访问
3、状态的存储、访问以及维护,由一个可插入的组件决定,这个组件就 叫做状态后端(state backend)
4、状态后端主要负责两件事:本地的状态管理,以及将检查点 (checkpoint)状态写入远程存储